Lecture 4:DRAM
1. DRAM 定义与 SRAM/DRAM 对比 P1 00:00:34
DRAM = Dynamic Random Access Memory,三个关键属性:Dynamic(动态)——需要周期性刷新,否则数据因泄漏丢失,这是与 SRAM 最本质的区别;Random Access(随机访问)——每个 bit 可独立读写;Volatile(易失性)——断电后数据丢失。这三个属性决定了 DRAM 的系统定位(主存)及其外围电路设计(刷新控制器、写回机制)。
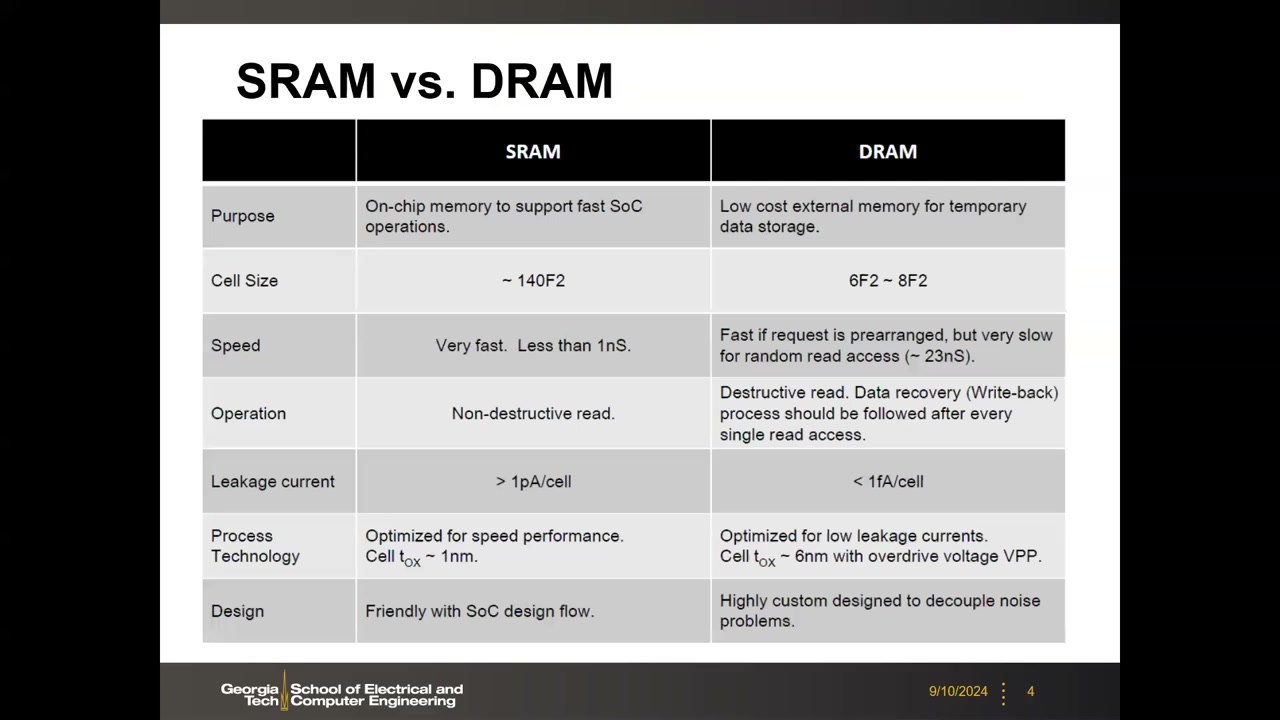
SRAM 与 DRAM 的全面对比 P1 00:01:05:
| 项目 | SRAM | DRAM |
|---|---|---|
| 用途 | 片上高速缓存(cache),支撑高速 SoC 运算 | 低成本片外主存(off-chip) |
| 单元面积 | ~140 F²(旧工艺约 150 F²) | 6–8 F²,同节点下小得多 |
| 速度 | 非常快,<1 ns(L1 可匹配 2–4 GHz 时钟) | 随机读较慢(~23 ns;整行周期约 40 ns) |
| 读操作 | 非破坏性读 | 破坏性读,每次读后必须写回 |
| 漏电流 | >1 pA/cell | <1 fA/cell(否则保持特性极差) |
| 工艺 | 为速度优化,tOX ~1 nm | 为低漏电优化,tOX ~6 nm,字线用升压 VPP |
| 设计 | 与 SoC 设计流程兼容 | 高度定制设计以解耦噪声 |
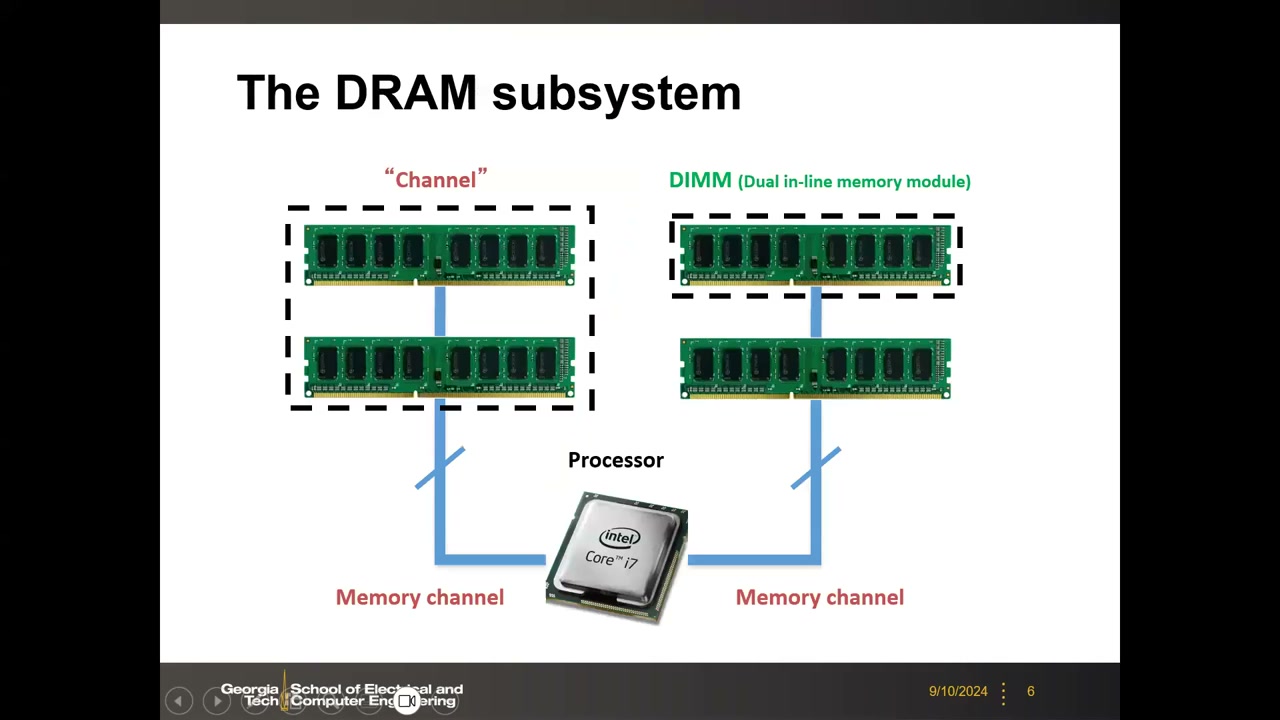
2. DRAM 子系统层级:Channel → DIMM → Rank → Chip → Bank → Mat P1 00:03:24
理解内存系统寻址与带宽的基础框架是自顶向下的层级:Channel(通道)→ DIMM(内存条)→ Rank → Chip(芯片)→ Bank →(Mat)→ Row/Column(行/列)。
- Channel 与 DIMM P1 00:03:52:处理器通过若干内存通道与 DIMM(双列直插内存模块)通信,同一 Channel 内的 DIMM 共享数据总线;DIMM 数据 I/O 典型为 64 个引脚(64-bit 数据总线)。
- Rank P1 00:04:57:DIMM 每一面的芯片组为一个 Rank(Rank 0 = 正面,Rank 1 = 背面),由片选 CS<0:1> 经 MUX 选择,每个 Rank 一次给出 64 bit。
- Rank → Chip P1 00:06:58:一个 Rank 由 8 颗芯片组成,每颗芯片每次只输出 8 bit(×8 芯片 × 8 颗 = 64-bit 总线)。
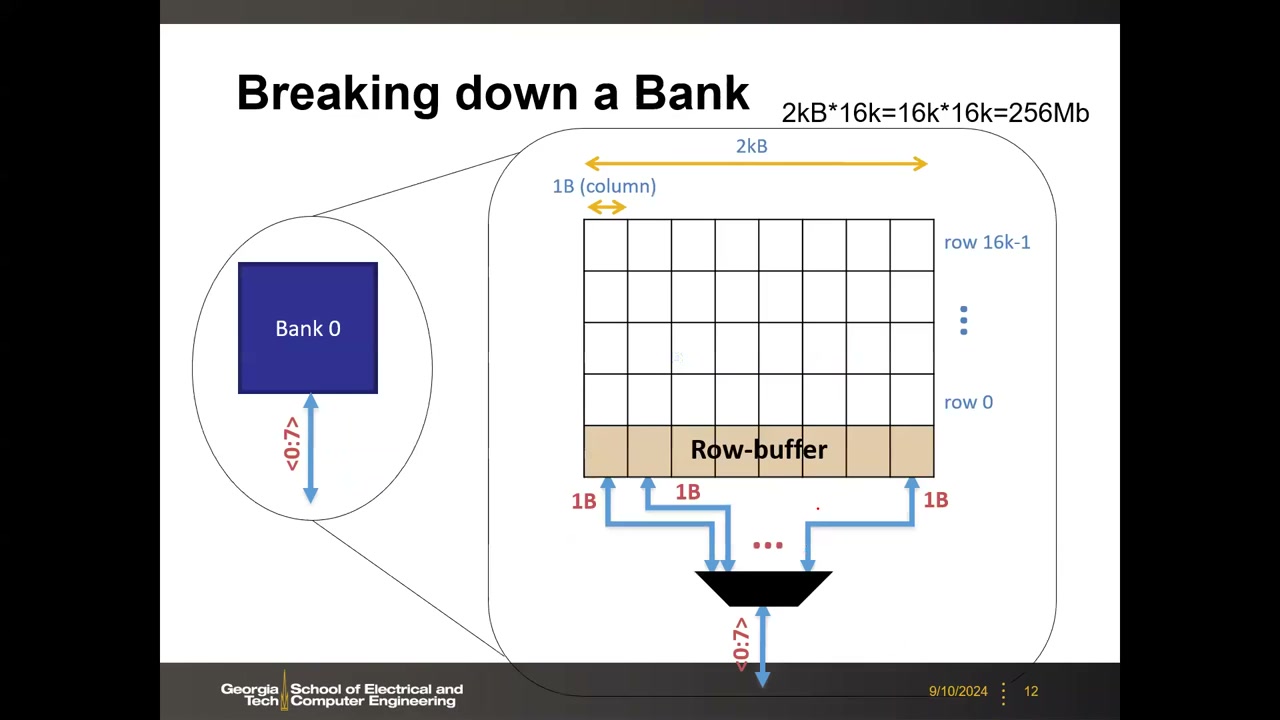
- Chip → Bank P1 00:07:58:每芯片内 8 个 Bank,经 MUX 选择;多 Bank 允许交错操作隐藏访问延迟。Bank 是 DRAM 中能独立传输数据的最小细分单位(每芯片 4 或 8 个)。
- Bank 内部:示例为 16k 行 × 16k 列阵列,每行 2kB,2kB × 16k = 16k × 16k = 256 Mb。激活一行后整行数据进入阵列边缘的 Row-buffer(行缓冲,本质是灵敏放大器阵列),再由列选择 MUX 选出 1 Byte 输出。Row-buffer 命中/未命中是 DRAM 时序的核心概念。
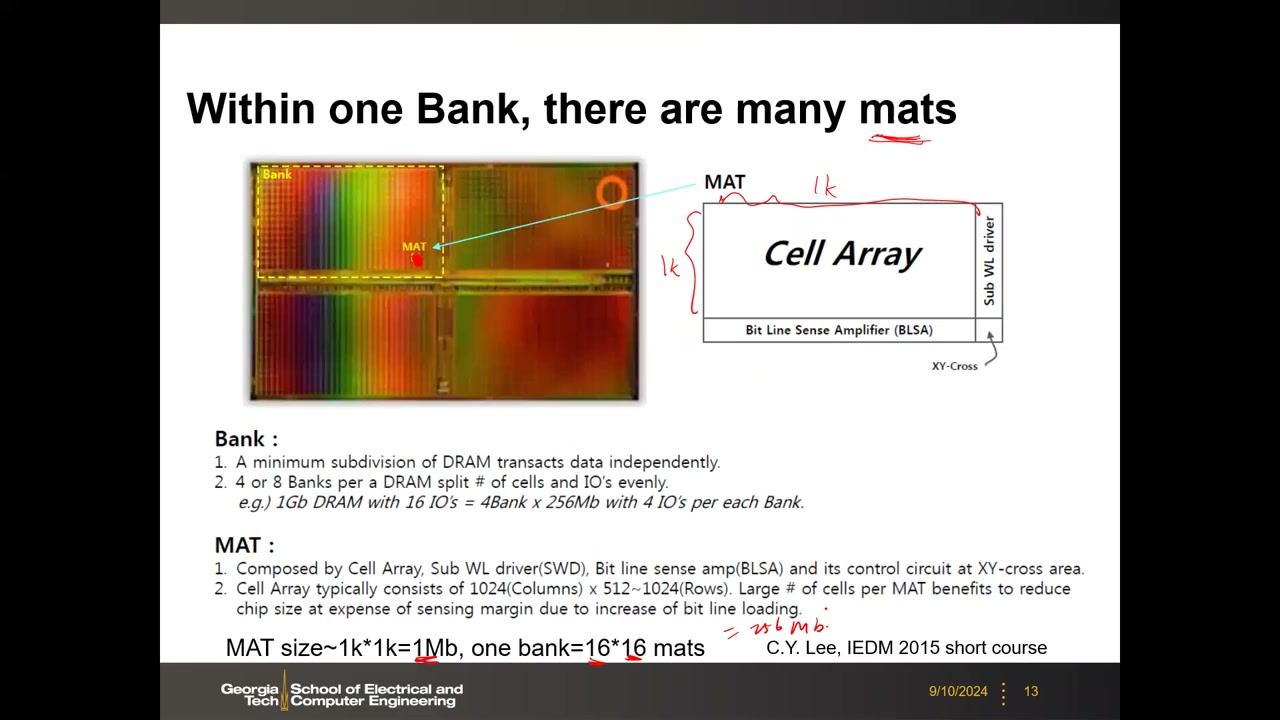
- Mat(子阵列) P1 00:09:24:Bank 太大,再分为许多 Mat = Cell Array + 子字线驱动器(SWD)+ 位线灵敏放大器(BLSA)+ XY-cross 控制区。典型 Mat ≈ 1k × 1k = 1 Mb,一个 Bank = 16 × 16 个 Mat = 256 Mb。Mat 越大越省面积,但位线负载增大、感测裕量下降——面积与感测裕量的折中。DRAM Mat(1k×1k)远大于 SRAM 子阵列(64×64 至 256×256)。
3. DDR 协议:Prefetch、Burst 与引脚带宽 P1 00:11:13
DDR(Double Data Rate)是 DRAM 的 I/O 接口协议。关键事实:DRAM 内部(core)时钟仅约 200 MHz,几十年来基本不变(至今约 200–300 MHz,受内部阵列物理限制);而 I/O 时钟被不断"超频"以提供系统级大带宽。核心技巧 = Prefetch(预取)+ 双沿传输:内部一次并行取出多组数据,I/O 在时钟上升沿和下降沿都发数据,本质是 core 与接口之间的并行到串行转换(serialize/deserialize)。
| 代际 | 内部阵列时钟 | Prefetch | I/O 时钟 | 每引脚数据率 | 串行化比 |
|---|---|---|---|---|---|
| DDR | 200 MHz | 2 | 200 MHz | 400 Mbps | 2:1 |
| DDR2 | 200 MHz | 4 | 400 MHz | 800 Mbps | 4:1 |
| DDR3 | 200 MHz | 8 | 800 MHz | 1600 Mbps | 8:1 |
即 DRAM I/O 吞吐率提升 8 倍(200→1600 Mbps/pin),内部总线速度保持 200 MHz 不变;DDR5 思路相同,继续把 I/O 时钟与预取倍数翻倍。注意以上数据率均为每引脚(per pin)指标。
带宽算例 P1 00:16:13:现代 CPU 需要 GB/s 级数据交换——12.8 GB/s 系统数据率 ÷ 64-bit DIMM = 每引脚 1600 Mb/s,而 core 只有 200 MHz,故必须用 DDR3 的 8:1 串行化接口。core 侧时钟由 CSL(列选择线)脉冲构成:2.5 ns 脉宽 + 2.5 ns 间隔 = 5 ns 周期 → 200 MHz。
BW = (Gbps/pin) × (#I/O pins)。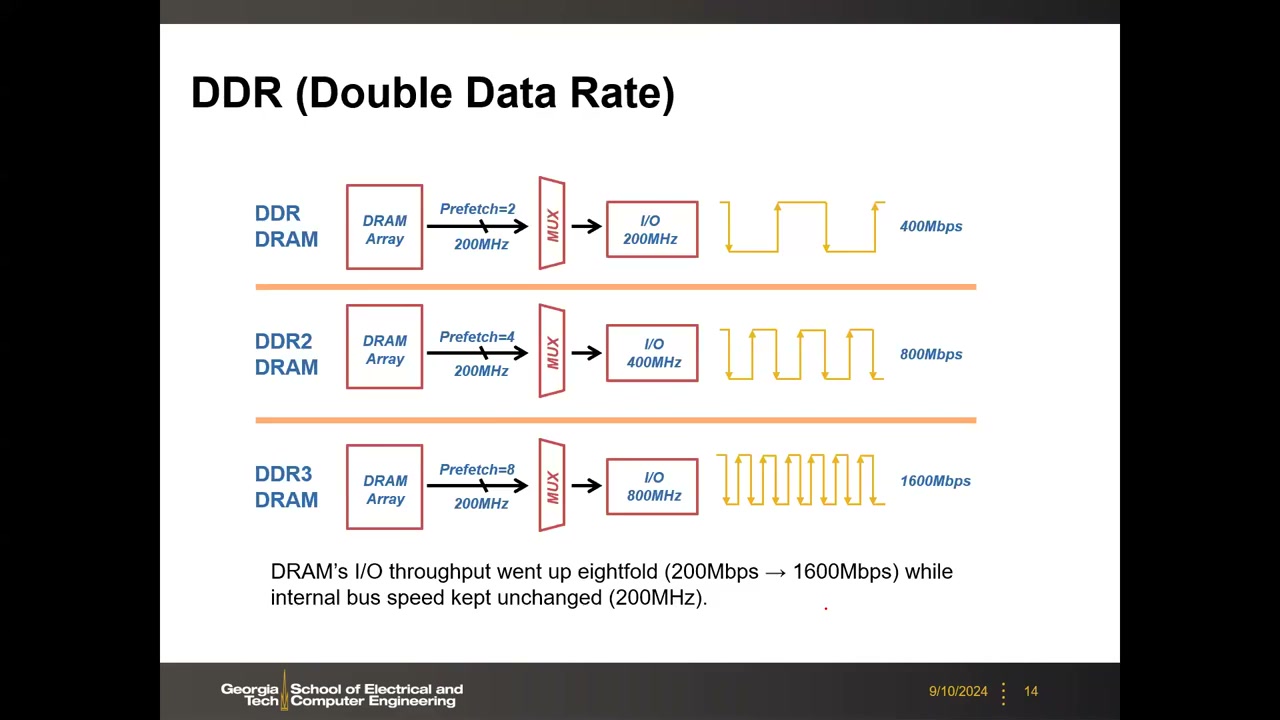

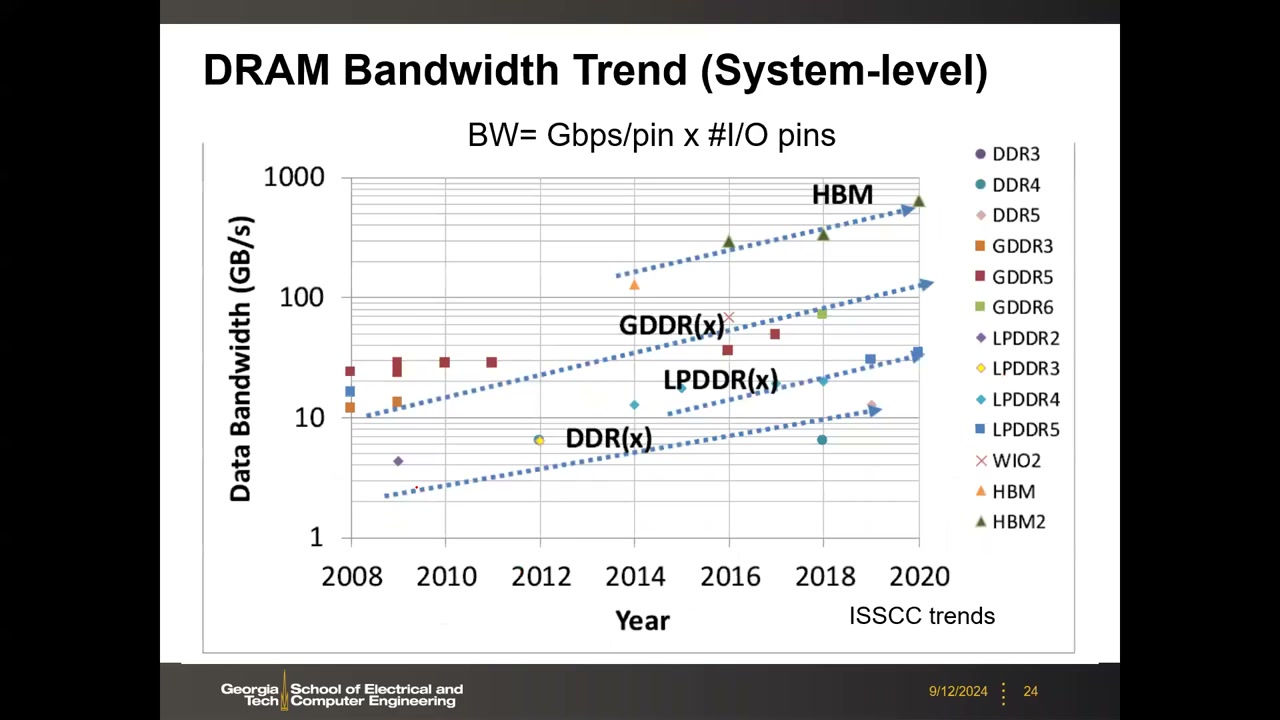
4. DRAM 历史、产品家族与产业格局 P2 00:02:43
历史:1966 年 IBM 的 Robert Dennard 发明单晶体管 DRAM(同名 Dennard 缩放定律);1970 年 Intel 1103 为首颗商用 DRAM(1 Kb,3 晶体管单元);1973 年 MK4096 为首颗 1T1C DRAM(4 Kb、地址复用、VDD 11.4–12.6 V、访问时间 300 ns、刷新 2 ms)。对比今天:电压 ~1.1 V、访问时间 ~30 ns(改善有限)、刷新 64 ms;真正数量级提升的是容量(4 Kb → 32 Gb,百万倍级)。
产品四大类 P2 00:06:08:
| 类别 | 代表 | 目标场景 | 设计取向 | 每 pin 速率 |
|---|---|---|---|---|
| Commodity DDR | SK Hynix 16Gb DDR5(ISSCC 2019) | 服务器/桌面主存 | 成本优先:大阵列段、长位线/字线摊薄外围面积 | 6.4 Gbps |
| LPDDR | Samsung 16Gb LPDDR5(ISSCC 2021) | 手机/平板 | 功耗优先:长刷新间隔、短位线、关断未用块 | 8 Gbps |
| GDDR | Micron 8Gb GDDR6X(ISSCC 2021,PAM4) | 图形/游戏 | 性能优先:短位线短字线降 RC,面积成本高 | 22 Gbps |
| HBM | HBM3P | 超算 / AI-ML | 宽接口(1024 pin)+ 3D 堆叠 | 较低,但系统带宽 >1 TB/s |
DDR5 芯片参考参数(业界首颗公开 DDR5):16 Gb、6.4 Gbps/pin、1y-nm 工艺、76.22 mm²、VDD/VDDQ 1.1 V、VPP 1.8 V(片上最高电压)、32 banks / 8 bank groups、In-DRAM ECC。
工艺节点 P2 00:20:43:DRAM 的特征尺寸 F 定义为金属 M1 半节距,是真实尺寸(与 logic 的"营销节点"不同)。20→10 nm 之间用 1x(≈19 nm)/1y(≈17 nm)/1z/1a/1b/1c 表示,每代仅缩 1–2 nm;2024 年最新量产为 1b(≈12 nm 级)。没有命名"0x",因为传统 1T1C 缩放接近极限。
市场与商业模式 P2 00:23:36:2020 年市场份额 Samsung 43.5%、SK hynix 30.1%、Micron 21.0%(总市场约 670 亿美元);近年 SK hynix 凭 HBM 升至 ~35%。三大厂均为 IDM(整合器件制造商)、全链路闭环——不存在 DRAM 代工厂,学术界也因此拿不到 1T1C 的 PDK/SPICE 模型。


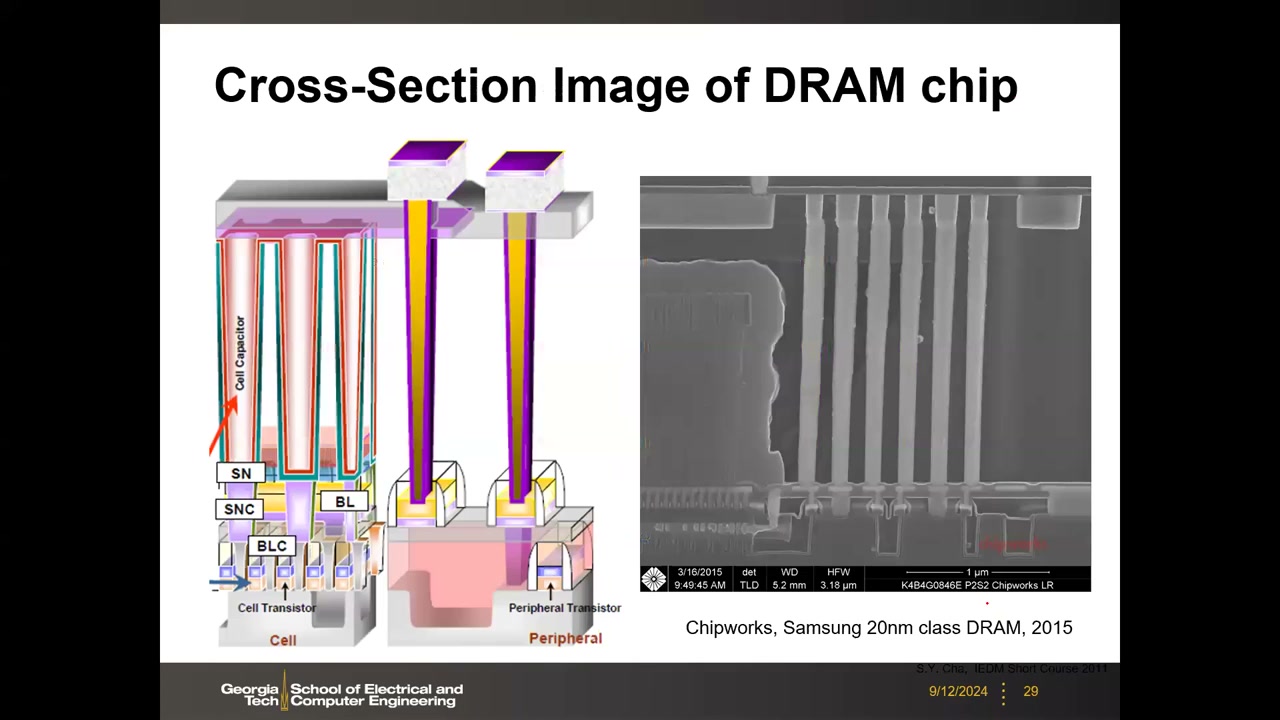
5. 1T1C 单元结构 P2 00:27:01
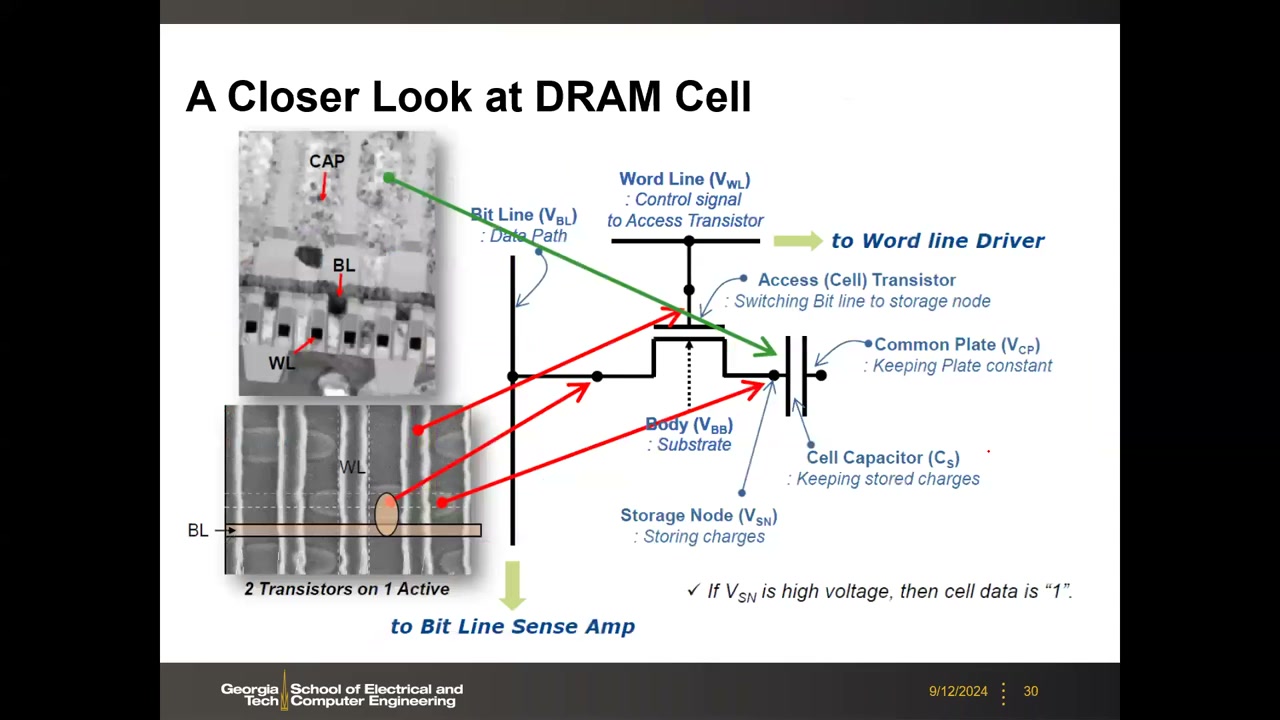
1T1C = 1 晶体管 + 1 电容 = 1 bit。电路要素:Word Line(WL)控制存取晶体管栅极;Bit Line(BL)为数据通路(每个单元只接一条位线);存取晶体管(NMOS);单元电容 CS,其一端为存储节点 SN(存放电荷),另一端为所有单元共享、电位恒定的公共板(Plate Line)。数据表示:VSN = VDD 为 "1",VSN = 0 为 "0"。
电容实际尺寸远大于晶体管,垂直堆叠在晶体管上方,并折成圆柱(cylinder)形以增大极板表面积(C ∝ 表面积)。版图上 BL 接触位于两条 WL 之间("2 Transistors on 1 Active"),TEM 剖面可见高耸密集的电容阵列在上、单元晶体管在下、外围电路晶体管在旁。
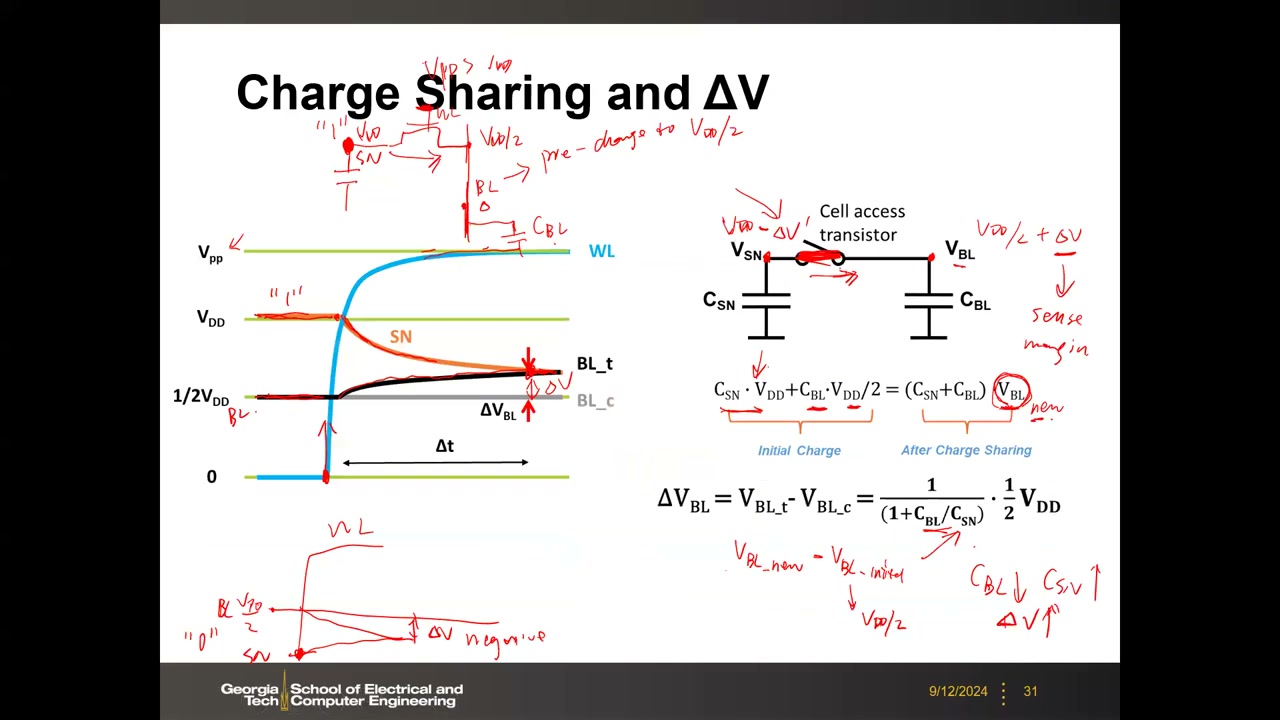
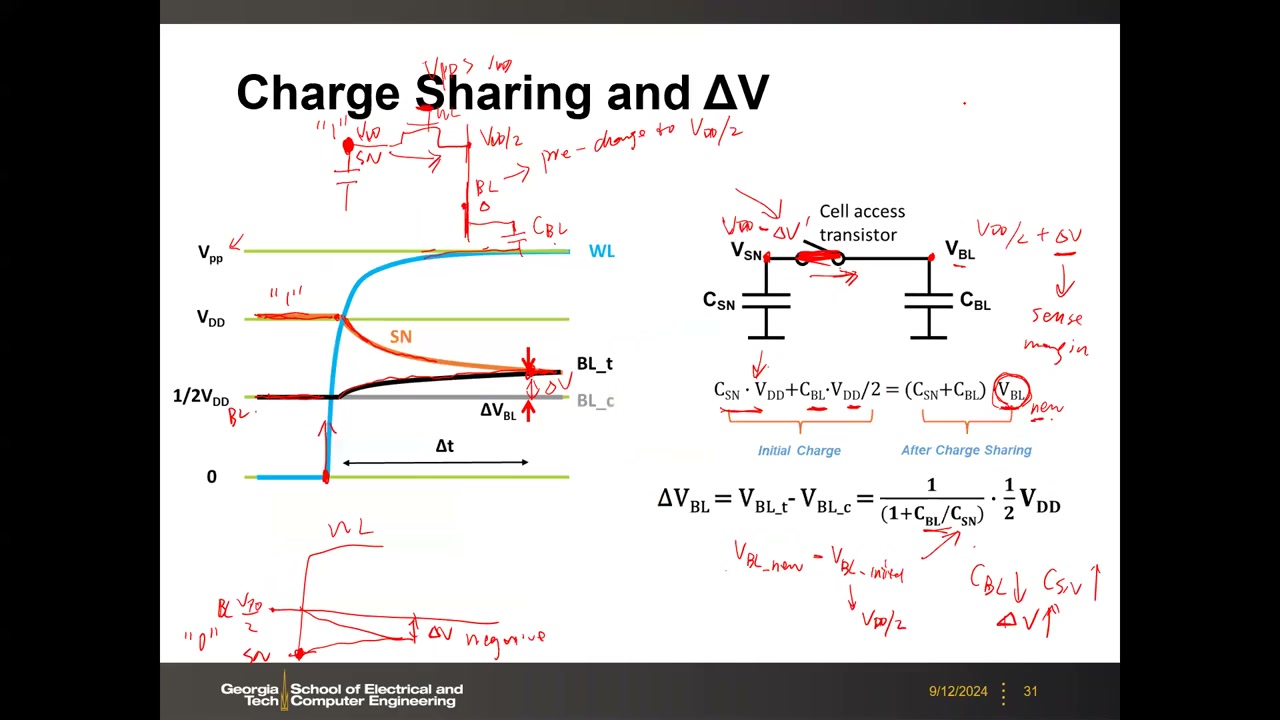
6. 读操作:电荷分享与感测裕量 ΔV(核心公式) P2 00:33:16
读 "1" 流程:① BL 预充到 ½VDD(与 SRAM 预充 VDD 不同);② WL 升压至 VPP > VDD,保证存取管栅过驱动充分、导通电阻低;③ VSN=VDD > VBL=½VDD,电荷从 SN 流向位线寄生电容 CBL;④ 达到等电位稳态。
电荷守恒:C_SN·V_DD + C_BL·(V_DD/2) = (C_SN + C_BL)·V_BL_new,由此得感测裕量公式(作业与考试必考):
ΔV_BL = V_BL_new − ½V_DD = [1 / (1 + C_BL/C_SN)] · (½V_DD)
比值 CBL/CSN 决定一切:要增大 ΔV 需 CSN 大、CBL 小——这正是必须做高圆柱电容维持足够 CSN 的原因。读 "1" 时 ΔV 为正,读 "0" 时 BL 向 SN 放电、ΔV 为负,靠正负判别数据。
电荷分享延迟 P2 00:44:46:把存取管视作沟道电阻 RT 的 RC 电路,回路内 CS 与 CB 串联:τ = R_T · C_S·C_B/(C_S + C_B),电荷分享延迟 T_d ≈ 2.3τ(达到摆幅 97%)。要快就要小 RT——再次解释 WL 升压 VPP 的必要性。

7. 破坏性读出、灵敏放大器与完整读写时序 P2 00:47:32
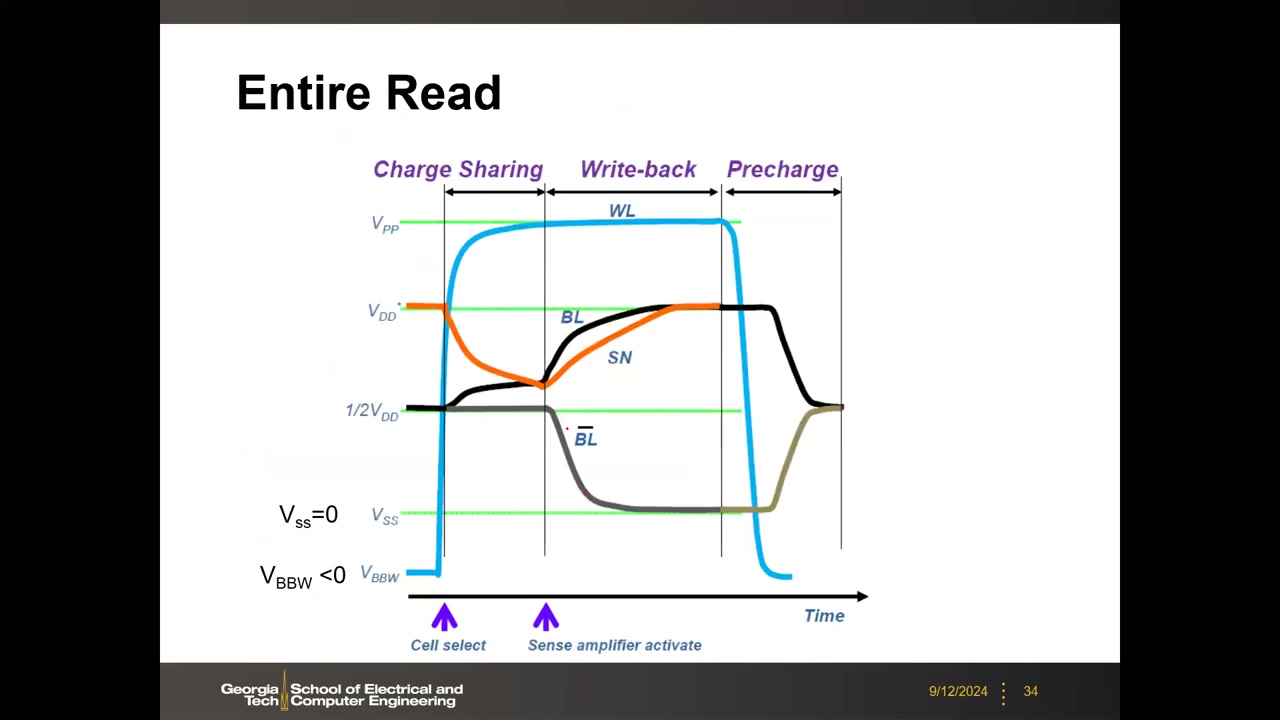
DRAM 读是破坏性的:电荷分享后 SN 电压已从 VDD 跌落,必须在读操作内把 "1" 恢复回 VDD,称 restore / write-back(写回),由灵敏放大器自动完成。灵敏放大器是交叉耦合反相器锁存,两输入为 BLt(true)与 BLc(参考),由 SAEN 控制上拉/下拉接通:开启后高侧(½VDD+ΔV)被拉到 VDD、另一侧放电到 0;因 WL 仍开启,电流反向把 SN 充回 VDD。最新 1z/1a/1b 节点的量产灵敏放大器与此教科书设计基本相同,仅各加两管做失调消除(offset cancellation)。
完整读 = 三阶段 P2 00:53:16:Charge Sharing(WL 开启、ΔV 建立)→ Write-back(SAEN 开启、SN 恢复)→ Precharge(关 WL、均衡 BL 回 ½VDD)。字线摆幅很大:待机时 VBBW < 0(负字线抑制亚阈值泄漏),激活时升至 VPP。
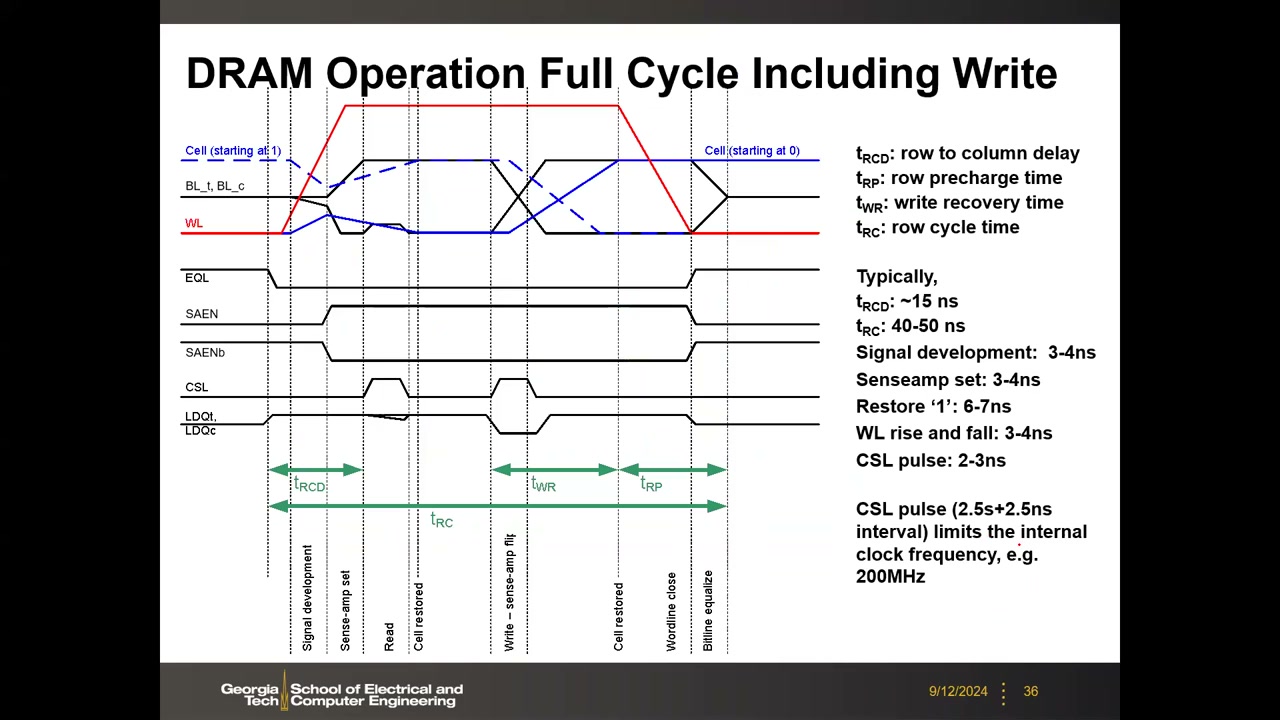
外围电路三模块 P2 00:54:47:Equalize(EQL 控制的 3 管预充均衡,强制 BL 到 ½VDD)、Sense(交叉耦合锁存 + NSET/PSET)、Connect(CSL 控制的传输门,把 BL 接到 LDQ 数据总线)。CSL 的开关频率就是 ~200 MHz 内部时钟。
时序参数(数据手册定义,典型值在先进节点亦变化不大) P2 00:58:31:tRCD(行到列延迟)≈ 15 ns;tRC(行周期)≈ 40–50 ns;信号建立 3–4 ns;灵敏放大器置位 3–4 ns;恢复 "1" 6–7 ns;CSL 脉冲 2–3 ns。CSL 5 ns 节拍是 DRAM 内部时钟约 200 MHz 的根源。
差分参考的来源 P2 01:06:08:每个 DRAM 单元只有一条位线(无 bit-bar),参考 BLc 取自另一(空闲)子阵列——只激活一个阵列,另一个的位线天然保持 ½VDD(开放位线思想,见第 11 节)。写操作则很直接:把 BL 驱到 VDD/GND,开 WL 复制到 SN——读才是 DRAM 真正棘手的部分。
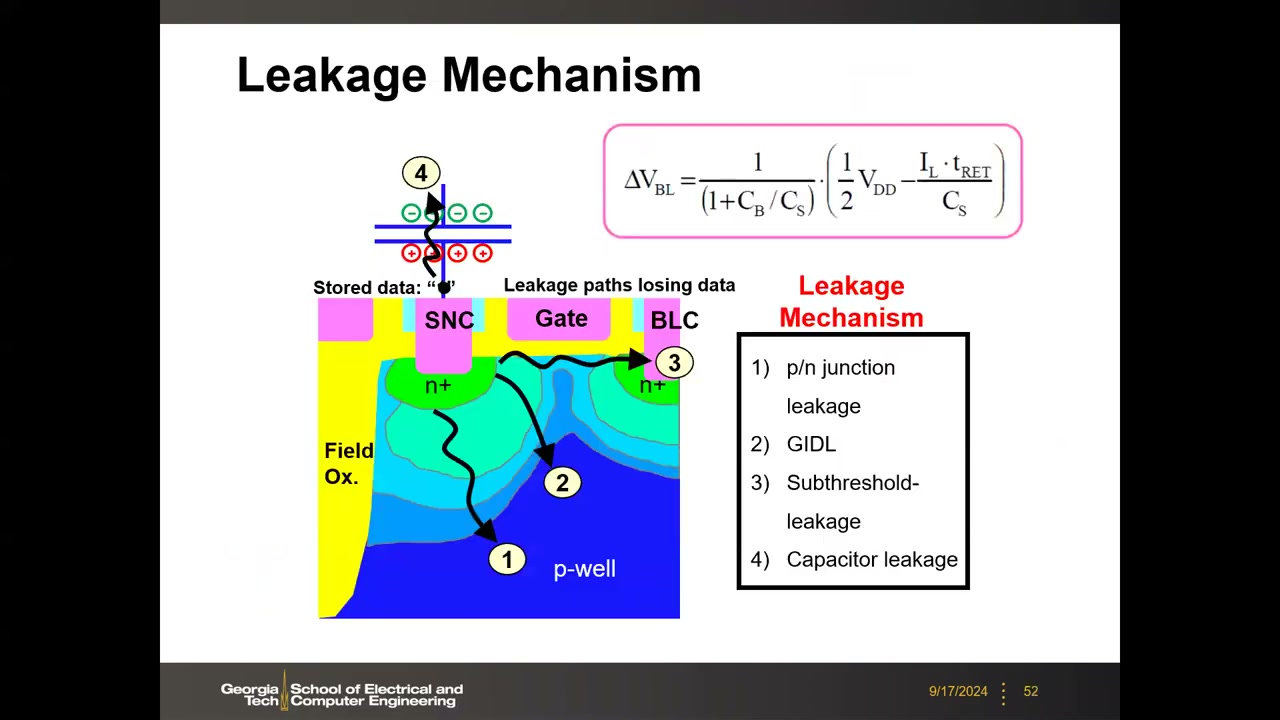
8. 泄漏机制、数据保持与刷新开销 P2 01:08:47
DRAM 之所以叫 "Dynamic",是因为存在泄漏使 SN 电荷流失。存 "1"(SN=VDD)有四条泄漏路径 P3 00:02:42:① p/n 结反偏泄漏;② GIDL(栅致漏极泄漏);③ 亚阈值泄漏 Ioff;④ 电容介质泄漏(缺陷少时可忽略)。考虑泄漏后的感测裕量公式:
ΔV_BL = [1/(1+C_B/C_S)] · (½V_DD − I_L·t_RET/C_S)
第二项是泄漏电荷除以存储电容造成的电压衰减——保持到 tRET 时读出的起始电压已从 VDD 下降。该公式把器件泄漏与电路感测裕量直接关联,是所有微缩设计指标的出发点(实际设计要求 ΔV ≥ 200 mV 以克服工艺涨落与感放失调)。
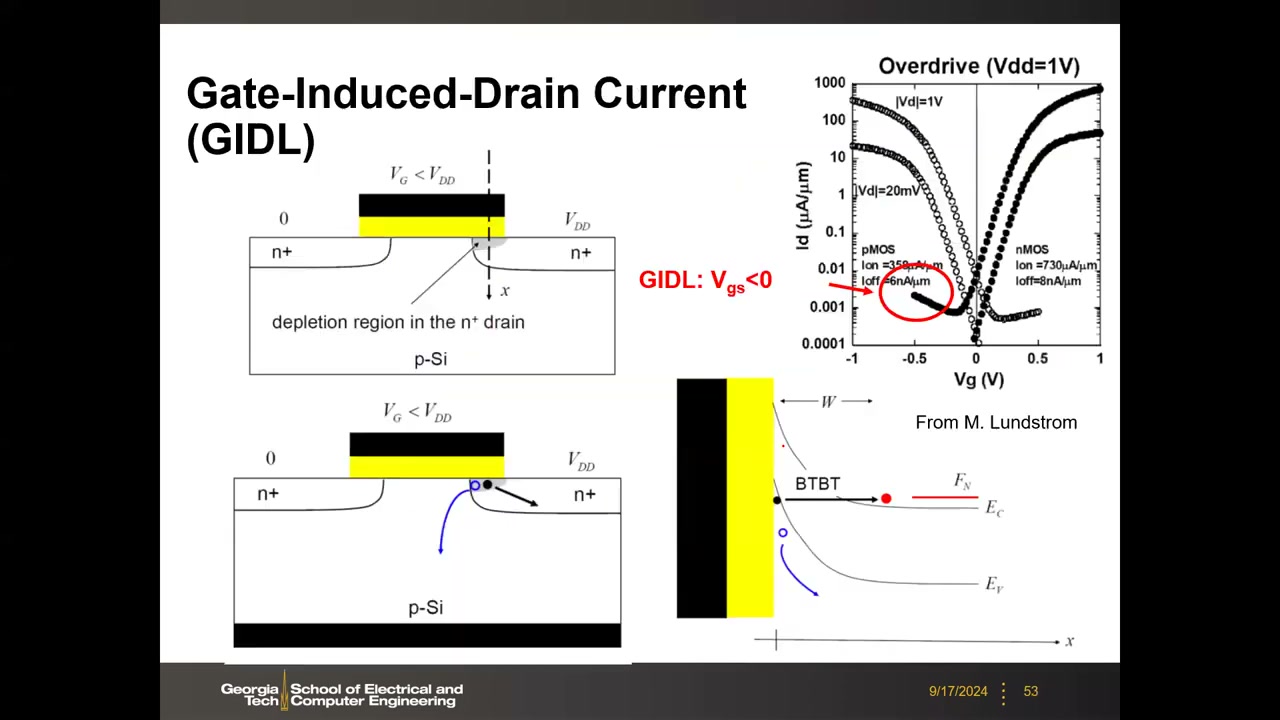
GIDL 物理 P3 00:07:45:当 VGD<0 时栅-漏交叠区能带强烈弯曲,价带电子直接带带隧穿(BTBT)到导带产生电子-空穴对,形成漏→衬底泄漏。保持模式下 WL=0(实际 −0.5 V)、SN=VDD 恰满足 GIDL 条件;负字线虽抑制 Ioff 却加剧 GIDL。
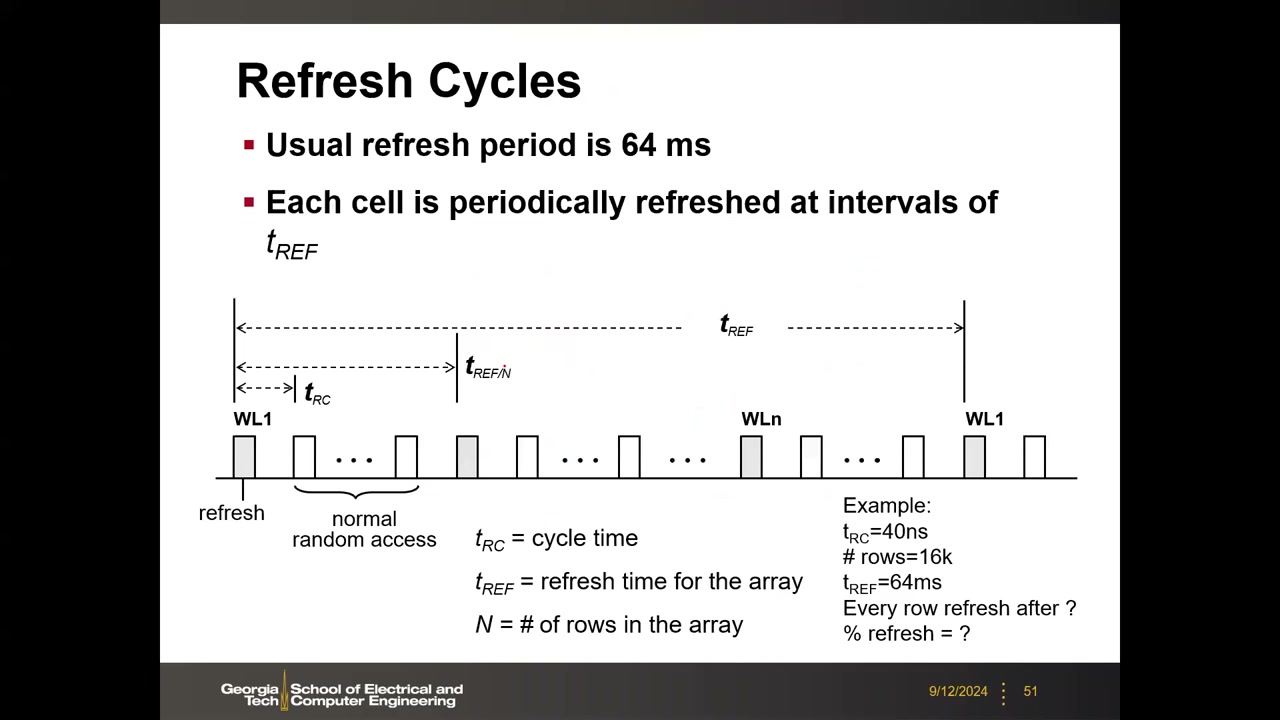
保持时间与 64 ms 标准:实际保持时间数十 ms 到秒级、片内差异极大;保持时间分布(CDF)显示仅极少数尾部位(tail bits)低于 64 ms,但可能超过 ECC 能力,故 JEDEC 统一规定 64 ms 刷新周期。
刷新开销算例 P2 01:11:46:N=16k 行、tRC=40 ns、tREF=64 ms → 相邻行刷新间隔 = 64 ms / 16k = 4 µs;刷新时间占比 = 40 ns / 4 µs ≈ 1%。若刷新周期缩到 32 ms 则开销升至 2%。随密度增大刷新开销上升(现约 8–10%;O. Mutlu 曾预测 64 Gb 时代达 46%,实际靠多 Bank 划分缓解),能量开销典型约 15%。
9. 动态保持干扰与 Row Hammer P3 00:15:06
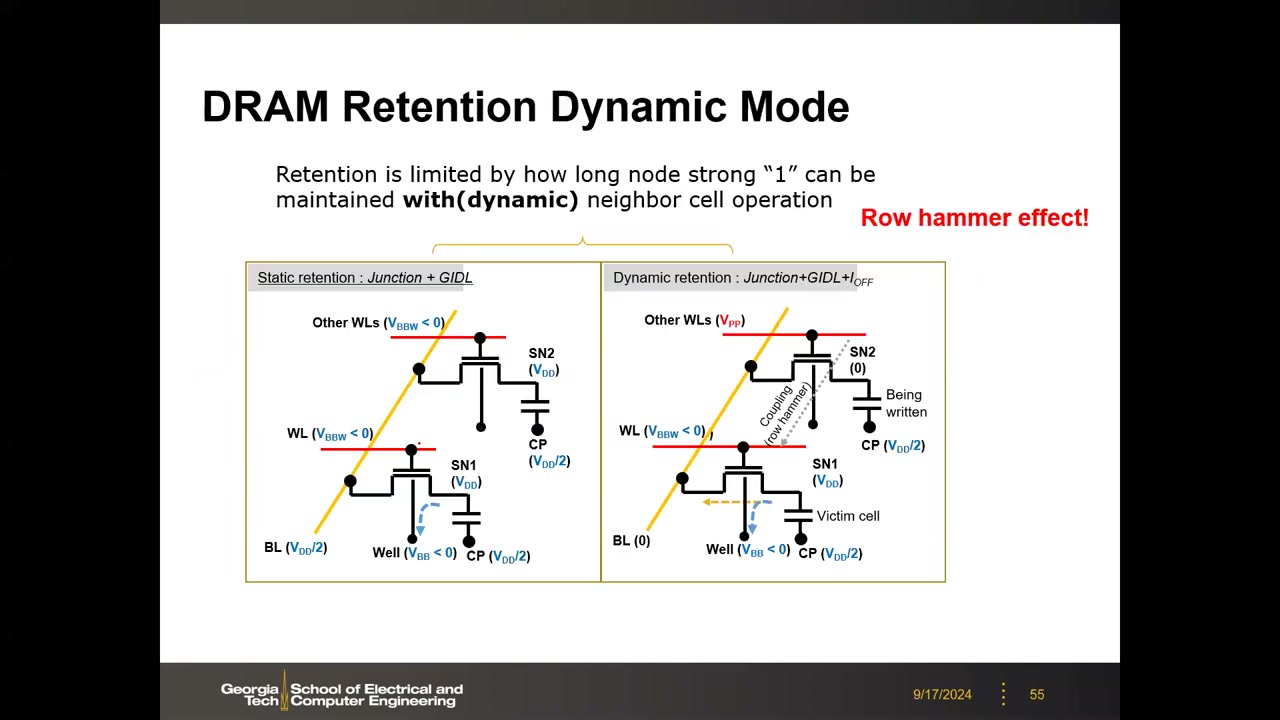
静态保持:单元待机且邻近无操作,泄漏 = 结泄漏 + GIDL。动态保持:本单元保持、相邻行正被操作(邻行字线抬到 VPP)——相邻字线间电容耦合使本行字线电压瞬时抬升 ΔV,在 log ID-VG 上 Ioff 被指数式放大,受害单元(victim cell)保持时间缩短。注意电容只在电位切换时传导瞬态电流,静态(电位恒定)无串扰。
Row Hammer(行锤):存储系统安全领域的著名攻击——反复读/写同一行(像锤子敲打),通过字线耦合干扰使相邻行数据翻转。Row hammer 与短沟道效应一起限制了字线间距的进一步缩小(见第 13 节)。
10. 单元电容:沟槽 vs 堆叠与电容工艺微缩 P3 00:21:51
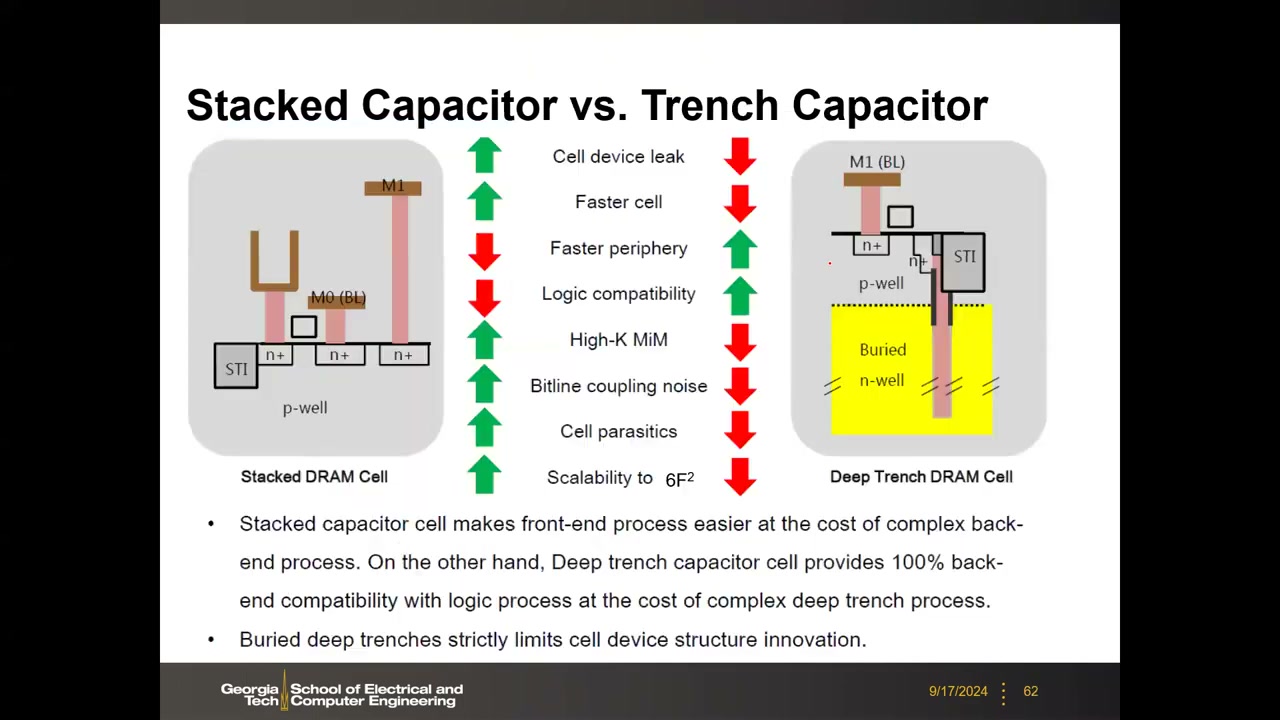
沟槽电容(Trench):先在硅衬底刻深沟槽、覆介质、填 N+ 多晶硅内电极,电容埋于硅内、晶体管后做。70 nm 节点后停产——只能做 8F² 版图、深沟槽内沉积高 K 极难、深宽比过高(末代已达 90:1)。残存用途:eDRAM(与逻辑工艺兼容,IBM Power 系列曾用)。
堆叠电容(STC,现行主流) P3 00:26:16:先做晶体管,再在接触孔上方堆叠圆筒电容。优点:易沉积高 K MIM、支持 6F²;挑战:机械稳定性、热预算受限(电容工艺 700→450°C)。三大厂 2010 年完成向 6F² 开放位线转换。讲者总结:"堆叠电容让前道简单、后道复杂;深沟槽 100% 后道兼容逻辑工艺,但沟槽本身工艺复杂"。
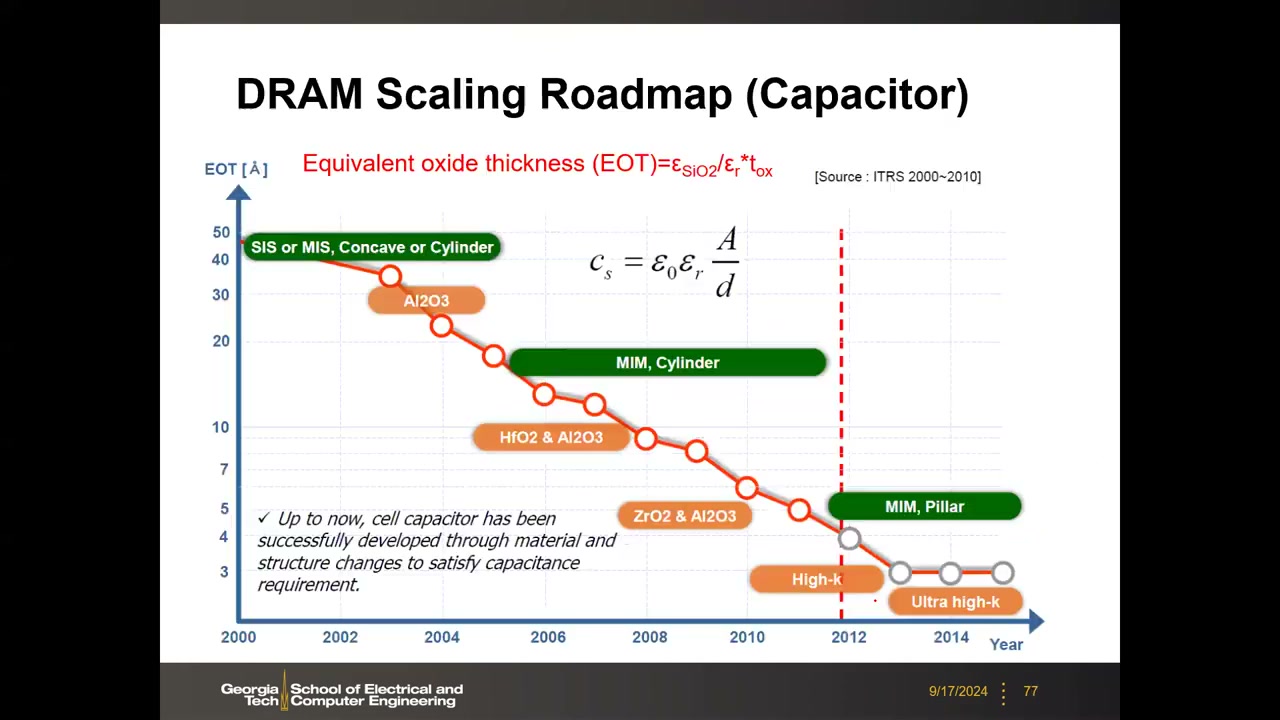
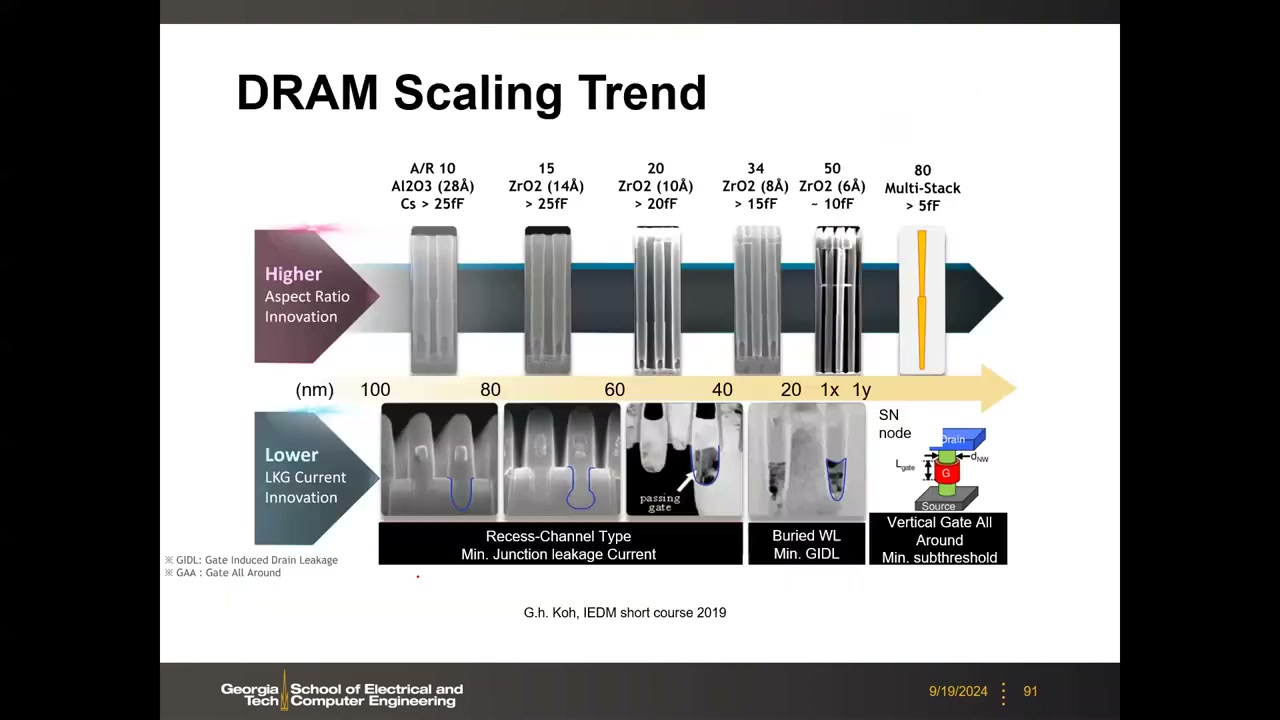
电极/介质演进 P3 00:55:16:SIS(双多晶硅)→ MIS(金属顶电极 + HSG 粗糙底电极)→ MIM(双金属 TiN 电极,介质 Ta₂O₅/Al₂O₃/HfO₂ → 今天主流 ZrO₂,k≈40,约为 SiO₂ 的 10 倍)。圆筒电容 C = εA/t,A = πD·H;缩放使 D 减小,三条对策:①升 ε(高 K);②增 H(越堆越高);③介质厚度 t 已不能再减(直接隧穿泄漏限制,对带隙 Eg 指数敏感——k 与 Eg 成反比折衷,最佳区 k≈20–40、Eg≈5–6 eV,HfO₂/ZrO₂ 胜出)。
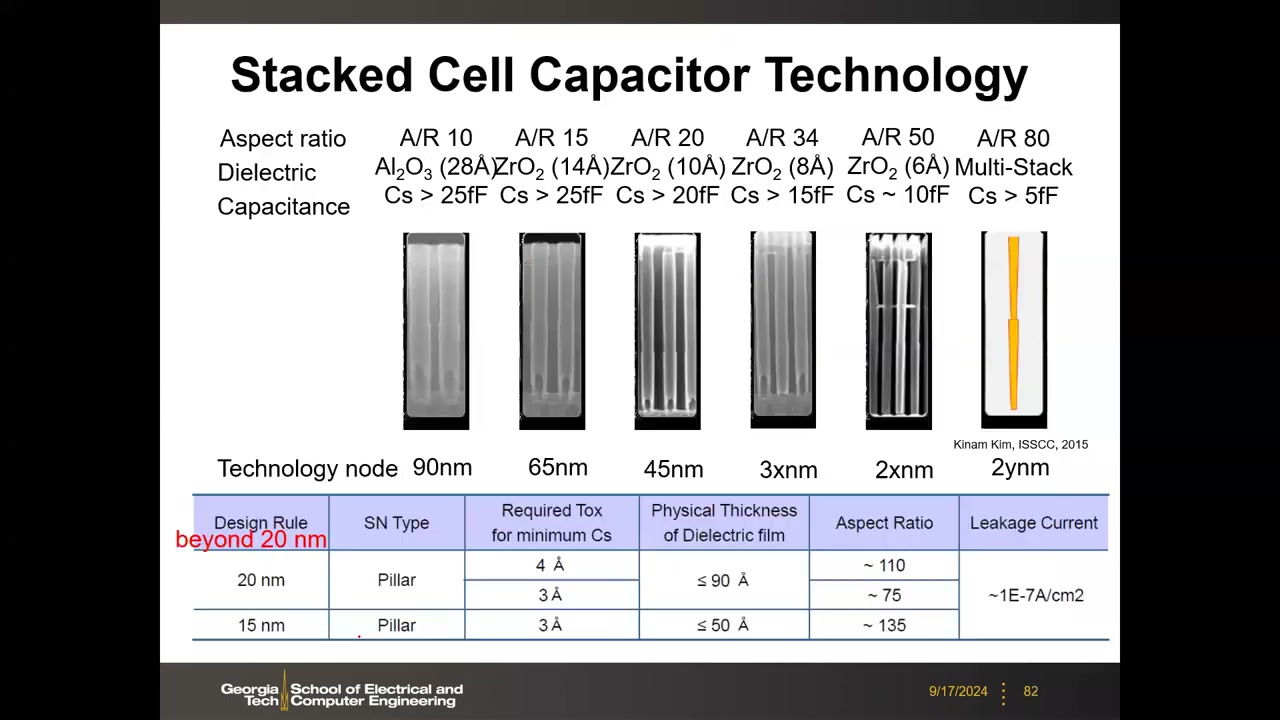
EOT 与深宽比:EOT =(εSiO2/εr)·tox,今天约 3–5 Å。电容形状从圆筒(U 形薄壁)转向柱状(Pillar,实心柱),省去存储节点电极厚度项支持继续缩放;柱状电容深宽比逼近 100(底部 12 nm、高约 1.2 µm,"像摩天大楼"),20 nm 级起引入机械支撑层(MESH)防倒塌。各代堆叠电容参数(Kinam Kim, ISSCC 2015):
| 节点 | 深宽比 A/R | 介质 | 电容 CS |
|---|---|---|---|
| 90 nm | 10 | Al₂O₃(28 Å) | >25 fF |
| 65 nm | 15 | ZrO₂(14 Å) | >25 fF |
| 45 nm | 20 | ZrO₂(10 Å) | >20 fF |
| 3x nm | 34 | ZrO₂(8 Å) | >15 fF |
| 2x nm | 50 | ZrO₂(6 Å) | ~10 fF |
| 2y nm | 80 | Multi-Stack | >5 fF |
20 nm 以下:柱状 SN、EOT 3–4 Å、介质物理厚度 ≤90 Å、A/R 约 75–135、电容泄漏电流密度 <1E-7 A/cm²。
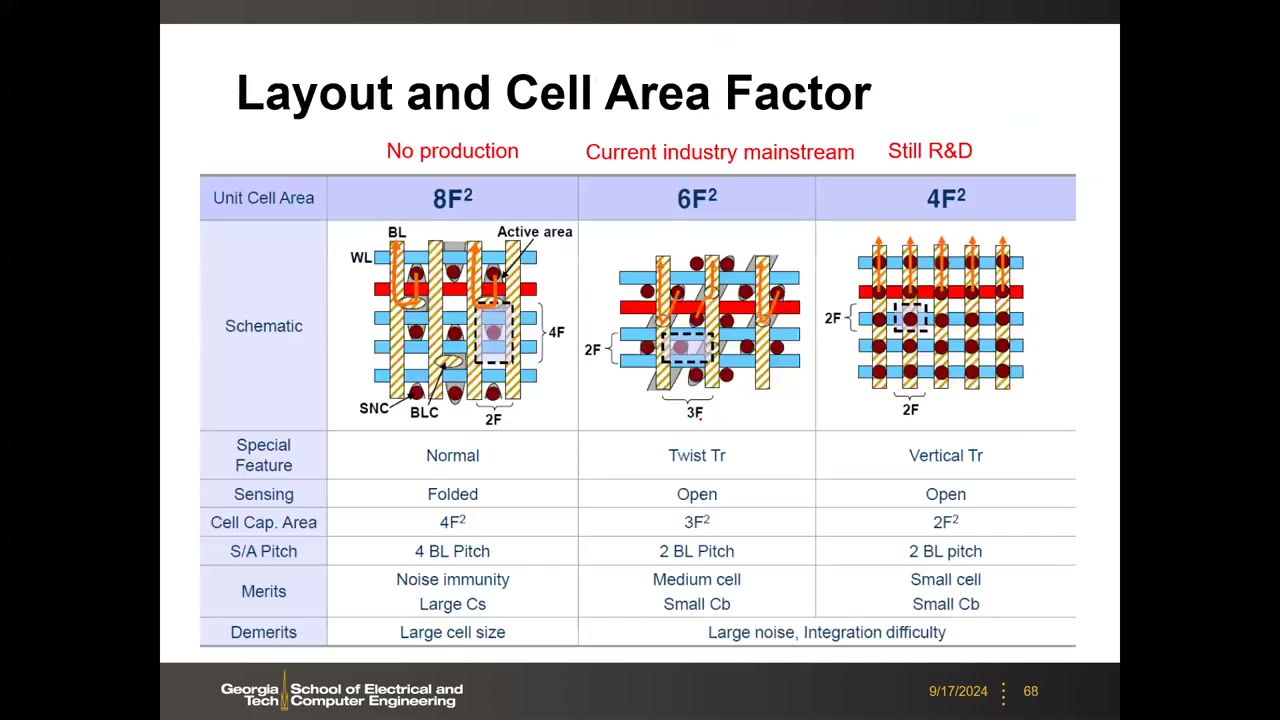
11. 阵列架构与版图:折叠/开放位线、8F²→6F²→4F² P3 00:28:45
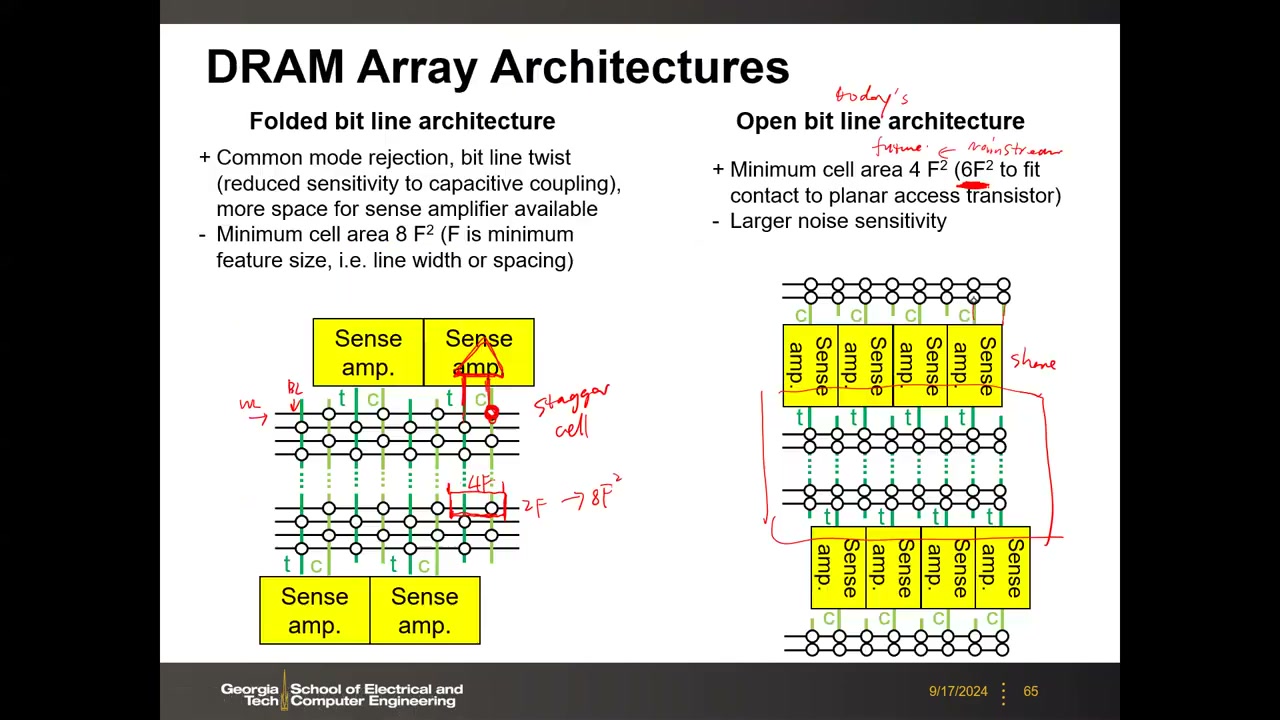
阵列尺寸约束:位线长度受感测裕量限制(典型每位线 512–1000 单元),字线长度受 RC 延迟限制。两种差分感测架构:
- 折叠位线(Folded BL,8F²):BLt 与 BLc 取自同一阵列相邻两条位线。约束:字线与位线对的交点只能放一个单元(单元交错/staggered,否则参考位线也被充放电),且需要"穿越字线"(passing WL)→ 4F × 2F = 8F²。优点:两线近邻、共模噪声被差分感放抵消,还可加捻(twist)。
- 开放位线(Open BL,6F²):感放夹在两个子阵列之间,BLt/BLc 分别来自两个阵列,一次只激活一个。每个交点都可放单元,理论极限 2F×2F = 4F²,但为给平面晶体管留位线接触实际 6F²(3F×2F)。缺点:两条位线相距远、无共模噪声抑制。业界 40 nm 以下全部转向开放位线 6F²(面积效率优先)。
| 8F² | 6F² | 4F² | |
|---|---|---|---|
| 感测方式 | 折叠 | 开放 | 开放 |
| 晶体管 | 常规直沟道 | 有源区/沟道相对字线倾斜 | 需垂直晶体管 |
| 单元尺寸 | 4F×2F | 3F×2F | 2F×2F |
| 感放间距 | 4 BL pitch | 2 BL pitch | — |
| 状态 | 噪声免疫好但单元大,已停产 | 当今工业主流 | 研发中 |
6F² 为何要斜沟道:若沟道平行于位线,电容正上方与位线冲突无法"立起来";倾斜让位线接触与存储节点错位,堆叠电容才能站立。这种密集布线在逻辑设计规则下是"Mission Impossible",是 DRAM 专属工艺。真实 6F² 三种流派 P3 00:45:10:Samsung(斜有源区,3F BL 间距 / 2F WL 间距);Qimonda 埋入式字线 bWL(TiN 金属栅埋入硅内,WL-BL 交叠电容低、直线条光刻简单——对产业影响重大,该公司研究员还在 DRAM 高 K 研究中发现了掺杂 HfO₂ 的铁电性);Micron 扭曲位线(有源区图形连续利于光刻,未用于今日量产)。
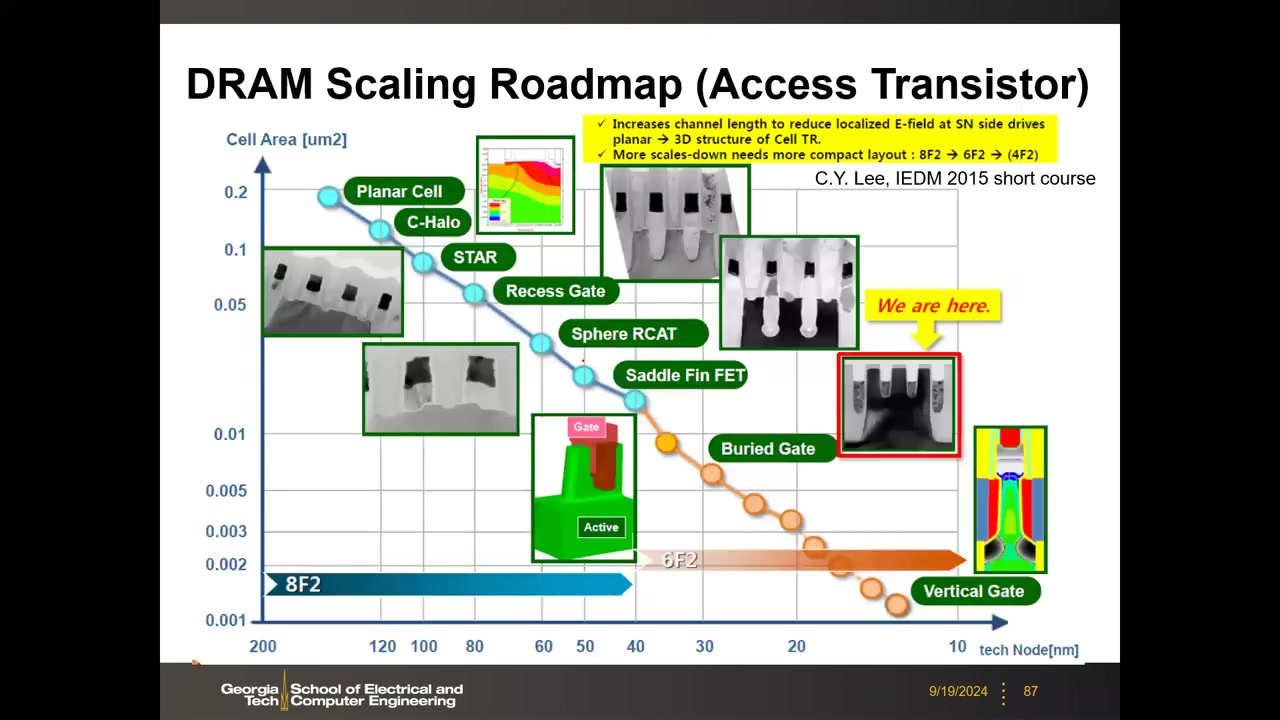
12. 存取晶体管演进与位线电容削减 P4 00:08:55
DRAM 存取晶体管与逻辑晶体管是"完全不同的动物":为数据保持优化超低漏电,要求 Ioff < 1 fA/µm(比低功耗逻辑晶体管低 3–4 个数量级);只用 NMOS;承受 VPP≈1.8 V 过驱动故栅氧更厚;性能仅相当于约 65 nm 时代的老逻辑晶体管。结构演进路线 P4 00:13:26:
- RCAT(90 nm):凹陷沟道——栅刻成 U 形凹槽,增大有效 Leff 而不占平面面积 → 低掺杂、低电场、保持时间显著改善。DRAM 史上首次"以结构换漏电"。
- Saddle FinFET(45 nm):Recess Gate + FinFET 组合(栅像"骑在马鞍上")——保住保持时间的同时降低体效应/DIBL,同 Vth 下导通电流提高约 30%。
- Buried Gate / 埋入式字线 BCAT(32 nm,现役):金属字线(TiN/W)整体埋入硅表面以下,增大与位线接触的距离 → WL 总电容降到约 1/3,大幅削减 BL-to-WL 寄生。
- 下一代:Vertical Gate-All-Around(最小化亚阈值泄漏,见第 13 节)。今日存取管同时具备凹陷沟道 + 埋入栅 + saddle fin 三特征。
位线电容削减 P4 00:01:18:感测裕量 ~ CS/CBL,CBL 构成(IEDM short course 2011 饼图):BL-to-WL 47% + BL-to-SN/板极 47% + BL-BL 4% + BL-衬底 2%。两大对策:Air Gap(空气隙) P4 00:06:20——在位线与存储节点之间刻出空洞(ε≈1,介电常数下限的"终极方案"),sub-20nm 节点起采用,削减 BL-to-SN 分量;埋入式字线削减 BL-to-WL 分量。

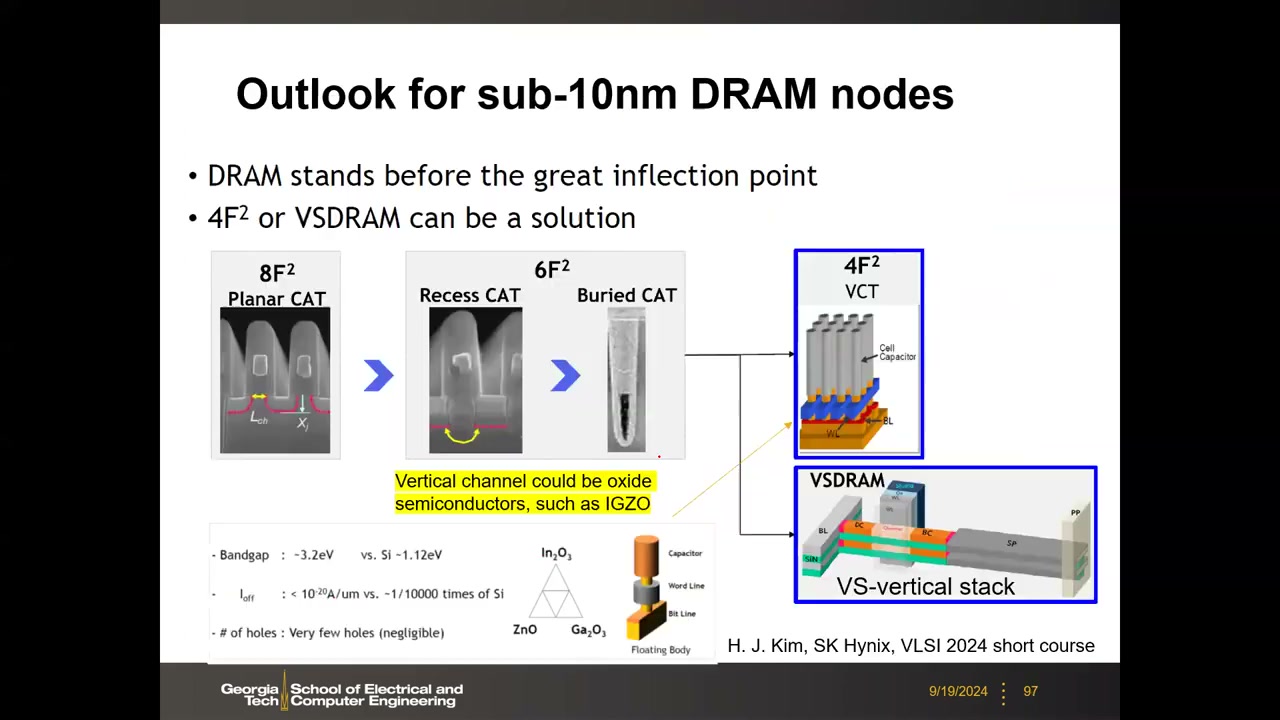
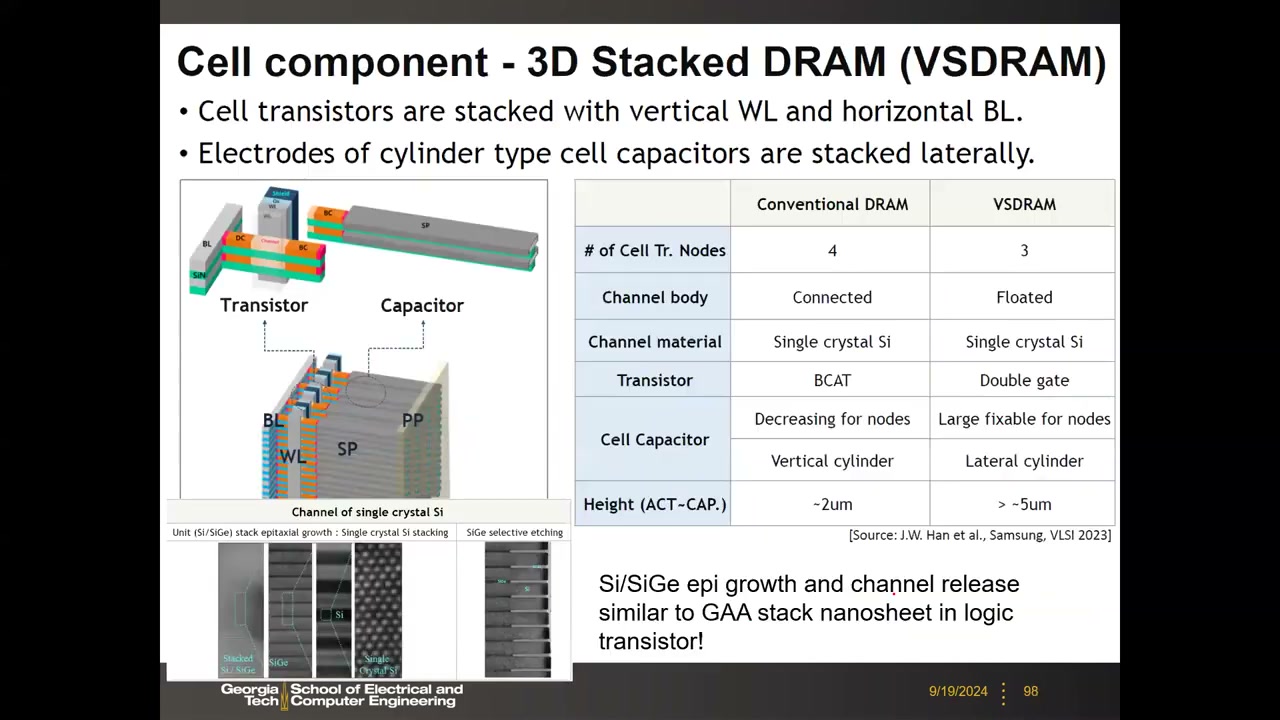
13. 2D 微缩极限与 sub-10nm 路线:4F² 垂直晶体管与 3D VSDRAM P4 00:21:53
6F² 已经"失效":20 nm 以下,低电压短沟道效应 + Row Hammer 使字线不能靠得太近,有源岛被迫更平行于位线,实际单元面积按 F² 计不降反升——Samsung 单元面积从 D2x 的 ~6.4F² 升到 D1z 的 ~8F²(0.00197 µm²,F≈15.7 nm)。课程约定:作业与考试仍按 6F² 计算,但要知道最新产品并非如此。两条出路:
路线一:4F² 垂直沟道晶体管(VCT) P4 00:27:30:硅柱 + 环栅(GAA),漏极直连上方电容、源极由下方埋位线收集;俯视只剩 1 WL + 1 BL 各占 2F → 2F×2F = 4F²,是 2D 平面 DRAM 的密度终点。Samsung 2009 年已演示但 10 年无后续——垂直晶体管没有凹陷沟道可用,硅沟道漏电难满足 retention。复兴关键:氧化物半导体沟道(IGZO)——带隙 ~3.2 eV(Si 为 1.12 eV)→ Ioff < 10⁻²⁰ A/µm,比硅低约 4 个数量级。sub-10nm 第一代(0a 节点)可能采用。
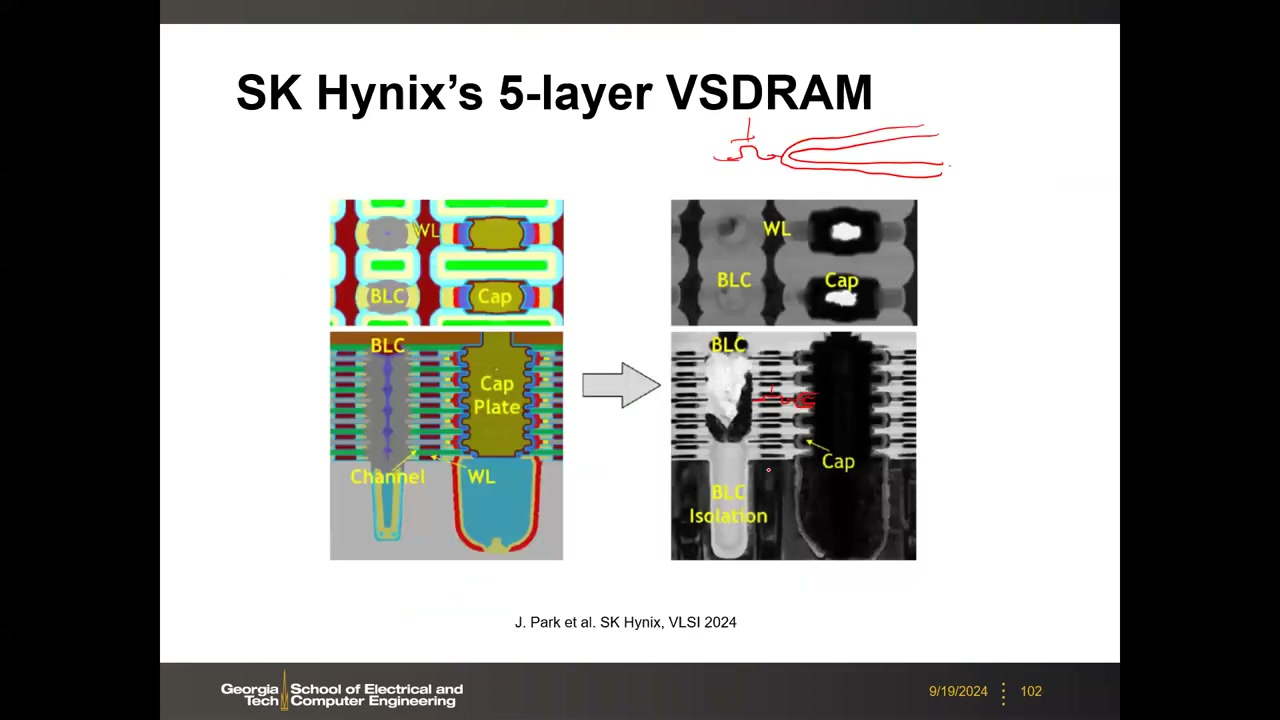
路线二:3D 堆叠 DRAM(VSDRAM) P4 00:32:54:把 1T1C 整体旋转 90° 水平放置、垂直堆叠多层——单片(monolithic)3D DRAM,区别于 HBM 的"键合伪 3D"。借鉴逻辑的 Si/SiGe 堆叠纳米片工艺与 3D NAND 的 bit-cost-scalable 原则(多层一次沉积、一次光刻、一次刻蚀,否则成本随层数线性上升毫无意义)。阵列取向:垂直 BL 优于垂直 WL——阶梯位线使各层 CBL 不同、感测裕量不均。SK Hynix VLSI 2024 已演示 5 层 VSDRAM 原型(垂直位线 + 双栅水平晶体管 + 水平圆柱电容,外围电路另置一片晶圆混合键合)。盈亏平衡分析(教授估算):水平放置的 ~1 µm 长电容占位巨大,需堆叠 64–100 层量级才能在面积上打平 2D;若水平电容能缩到 ~100 nm,平衡点可降到 8–16 层(开放研究问题)。Micron 有上千人投入 3D DRAM——"DRAM 将追随 NAND 走向 3D"。
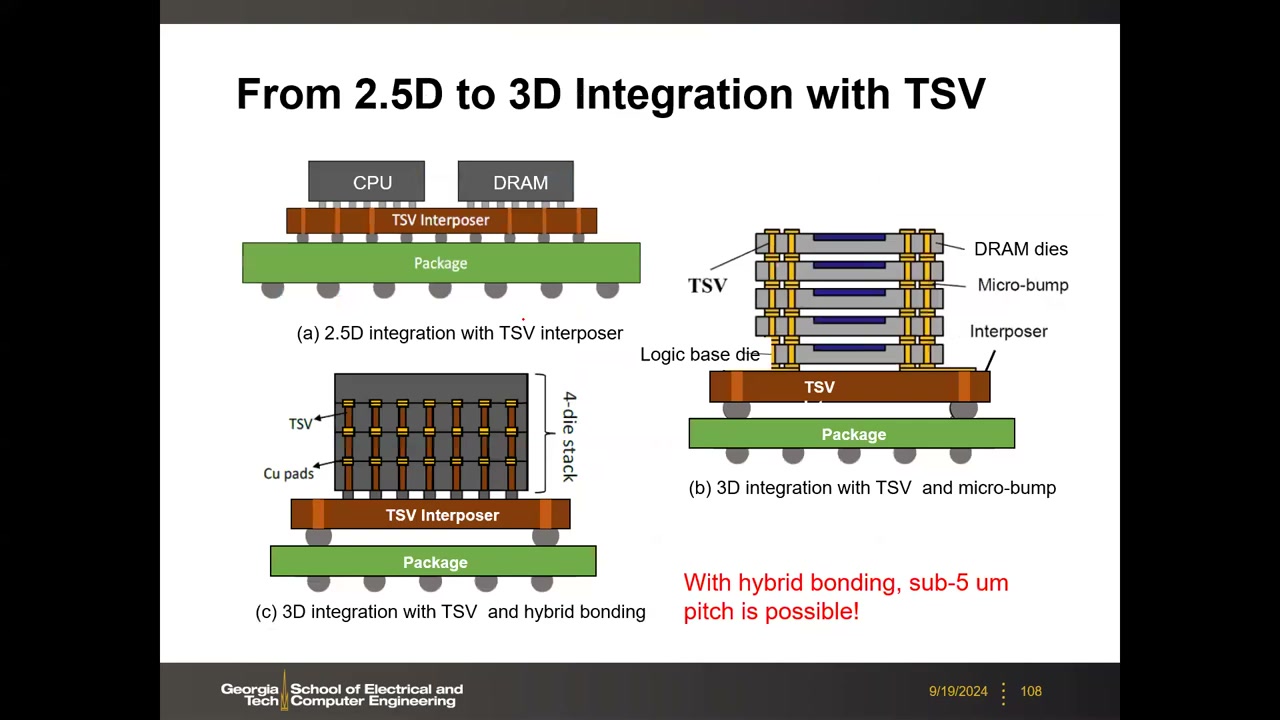
14. 先进封装:TSV、2.5D/3D 集成与混合键合 P4 00:51:24
TSV(硅通孔)取代稀疏的引线键合实现高密度垂直互连。六步简化流程:通孔刻蚀 → 介质层 → 阻挡层(TaN,防铜扩散)+ 种子层 → 电镀铜 → CMP 平坦化 → 背面减薄露出通孔。典型参数 P4 00:53:41:电阻 0.01–0.1 Ω;电容 50–500 fF(显著的 RC 寄生);间距 10–50 µm(典型 ~20 µm);直径 5–25 µm;深宽比 5–20。
集成形态 P4 00:57:01:
- 2.5D:处理器与 DRAM 并排放在硅中介层(interposer)上,中介层内 TSV 供电/信号、表面水平布线互通(HBM 即此形态)。
- 3D(TSV + micro-bump):die 垂直堆叠,层间 SnAg 微凸点,间距约 20–30 µm。
- 3D(TSV + hybrid bonding):无凸点,Cu-Cu 焊盘直接键合 + SiO₂/SiCN 介质键合,间距 <5 µm 甚至亚微米(已演示 400 nm)。机理:CMP(铜盘略凹)→ 等离子活化 → 贴放 → 退火(氧桥粘合 SiO₂、铜膨胀互连)。
系统形态演进 P4 01:06:18:今日 2D(片上 SRAM + 片外 DIMM,64 bit)→ 今日 2.5D(HBM + 中介层,1024 bit 宽接口)→ 明日 3D(DRAM 直接堆在处理器上,尚不存在)。主要障碍是热:处理器热量传入 DRAM 使漏电上升、retention 急剧恶化;3D 系统的永恒矛盾是"如何把电送进去、把热抽出来"(供电自下而上、散热自上而下,中间层最难散热)。
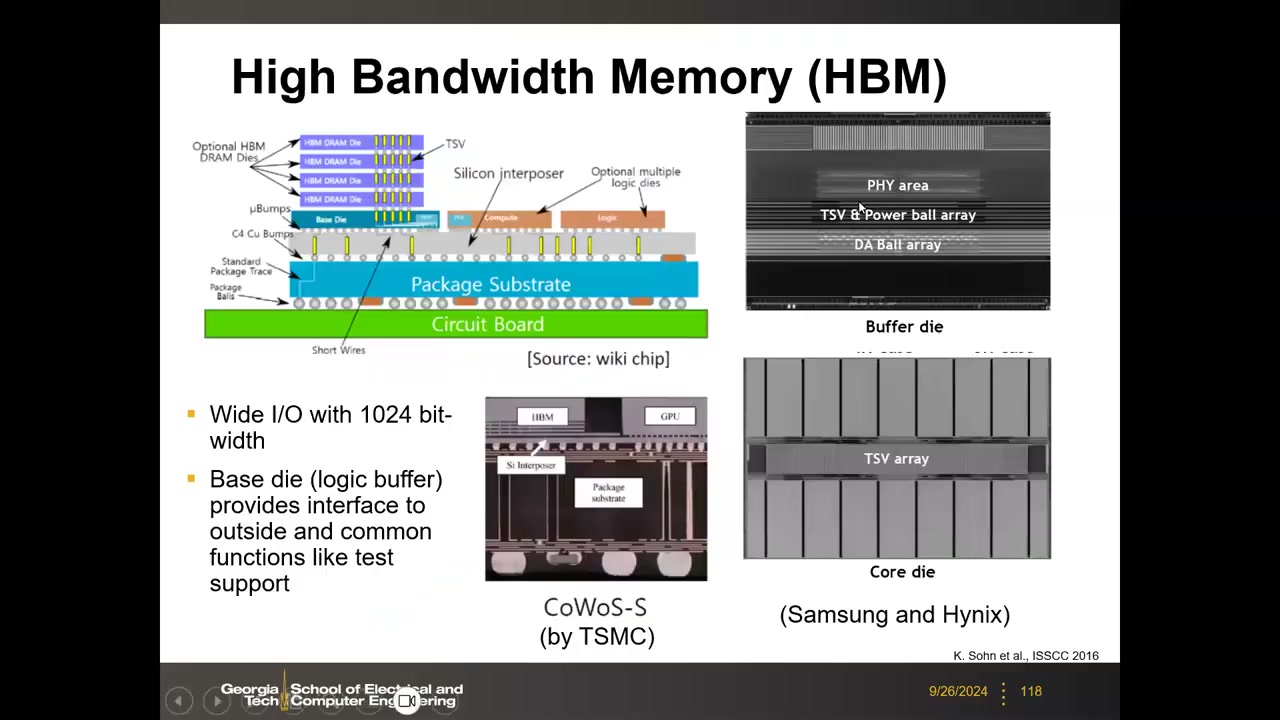
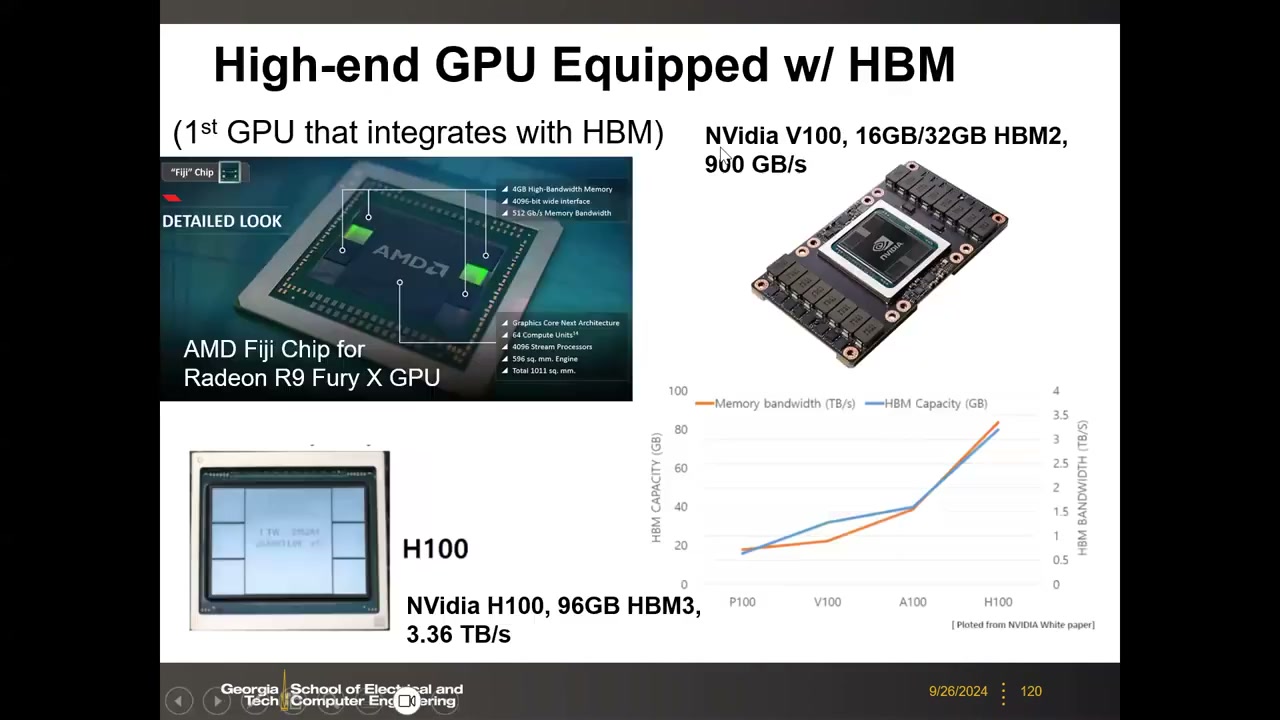
15. HBM 高带宽存储器 P5 00:00:03
结构:HBM = 多层 2D DRAM die 经 TSV + 微凸点垂直堆叠,最底层是 base die(逻辑 die),集成 I/O 接口、PHY、时序与调度电路。HBM 栈与 GPU 经硅中介层水平互连,由 TSMC CoWoS 技术完成集成(存储厂造 HBM 栈、TSMC 造 GPU 并做晶圆级集成)。TSV 三类用途:信号、供电、热 TSV(导热)。核心接口特征:Wide I/O 1024 bit(DDR 仅 64 bit)——走"低速 pin × 超多 pin"路线。
GDDR5 vs HBM 系统级对比(Samsung IEDM 2019)P5 00:06:25:
| 项目 | GDDR5 | HBM |
|---|---|---|
| 系统尺寸 | 60×52 mm(处理器 + 12 颗 G5) | 33×24 mm(处理器 + 4 栈) |
| 封装面积 | 3120 mm² | 792 mm²(约 −75%) |
| 总容量 | 12 GB | 16 GB(1.3×) |
| 带宽 | 384 GB/s | 1024 GB/s(3.6×,约 1 TB/s) |
| 功耗(仅存储) | 18.3 W | 9.1 W(能效 +18%) |
| 每 pin 速率 | 8 Gbps | 2 Gbps |
| I/O 数 | 每芯片 32(共 384) | 每 cube 1024(共 4096) |
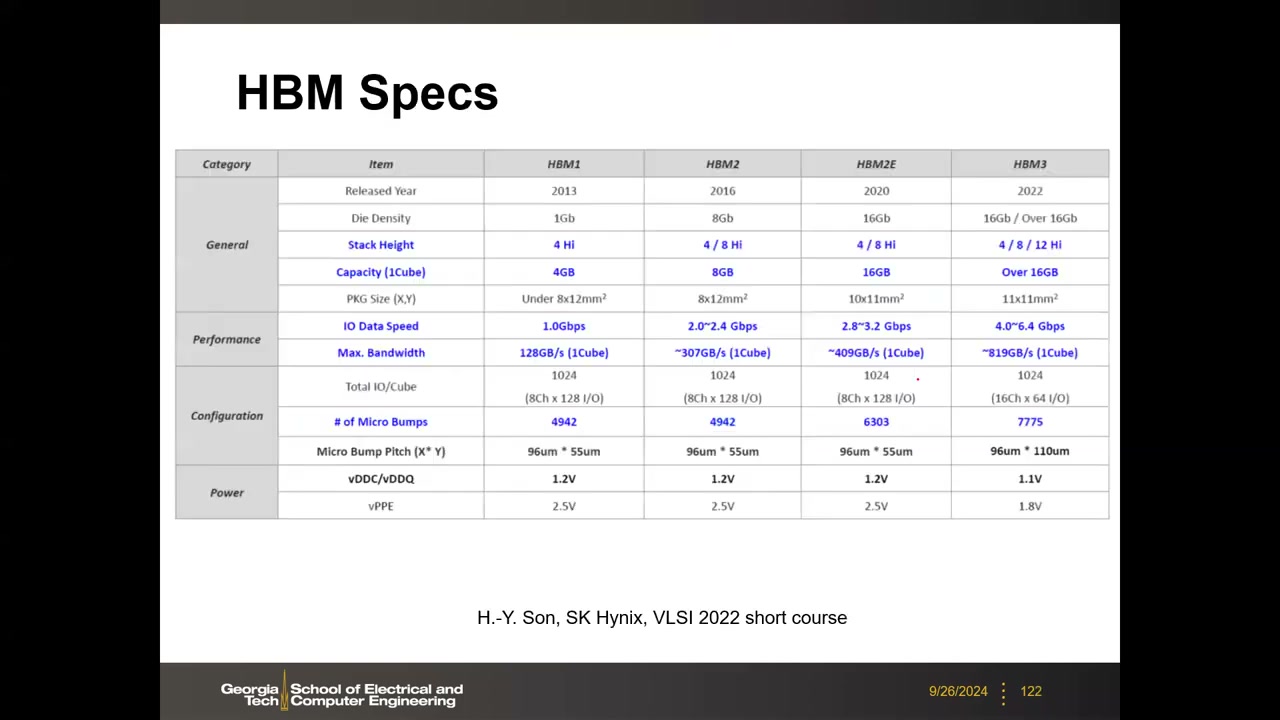
各代规格(SK Hynix VLSI 2022)P5 00:12:18。提升的两条途径:单 die 密度随工艺微缩提升;堆叠层数(Hi)增加(4-Hi → 8-Hi → 12-Hi):
| 项目 | HBM1 | HBM2 | HBM2E | HBM3 |
|---|---|---|---|---|
| 发布年份 | 2013 | 2016 | 2020 | 2022 |
| 单 die 密度 | 1 Gb | 8 Gb | 16 Gb | 16 Gb / >16 Gb |
| 堆叠层数 | 4 Hi | 4/8 Hi | 4/8 Hi | 4/8/12 Hi |
| 单 cube 容量 | 4 GB | 8 GB | 16 GB | >16 GB |
| IO 数据率 | 1.0 Gbps | 2.0–2.4 Gbps | 2.8–3.2 Gbps | 4.0–6.4 Gbps |
| 最大带宽/cube | 128 GB/s | ~307 GB/s | ~409 GB/s | ~819 GB/s |
| 总 I/O 数 | 1024(8Ch×128) | 1024(8Ch×128) | 1024(8Ch×128) | 1024(16Ch×64) |
| 微凸点数 / 间距 | 4942 / 96×55 µm | 4942 / 96×55 µm | 6303 / 96×55 µm | 7775 / 96×110 µm |
| vDDC/vDDQ · vPPE | 1.2 V · 2.5 V | 1.2 V · 2.5 V | 1.2 V · 2.5 V | 1.1 V · 1.8 V |
总趋势:每 2 年容量与带宽各提升约 1.5 倍。HBM4 前瞻 P5 00:18:34:16-Hi 堆叠;I/O 翻倍到 2048;微凸点(~30 µm 间距)改为 Cu-Cu 混合键合(<5 µm)。
封装工艺 P5 00:16:05:via-middle TSV + 双面微凸点 + Chip-to-Wafer 堆叠,晶圆级 KGSD 测试。热管理 P5 00:19:40:热源是 SoC 与 base die(DRAM die 本身发热不多);高温使漏电增大 → retention 随温度退化 → 须更频繁刷新。缓解:裸露硅封装、热假凸点/高导热填充、散热器 + TIM、液冷;"Many TSVs are thermal TSVs",系统级热协同设计至关重要。

16. eDRAM 与无电容 DRAM P5 00:22:31
eDRAM 是集成在处理器芯片上(on-chip)的 DRAM,目标是填补 SRAM 与 DRAM 之间的鸿沟——两者单元面积差 20–30 倍、随机访问速度差 50–100 倍。eDRAM 比 SRAM 小、比 DRAM 快。集成难点:独立 DRAM 的堆叠电容立在器件上方,与需要 15–16 层金属布线的逻辑工艺不兼容。
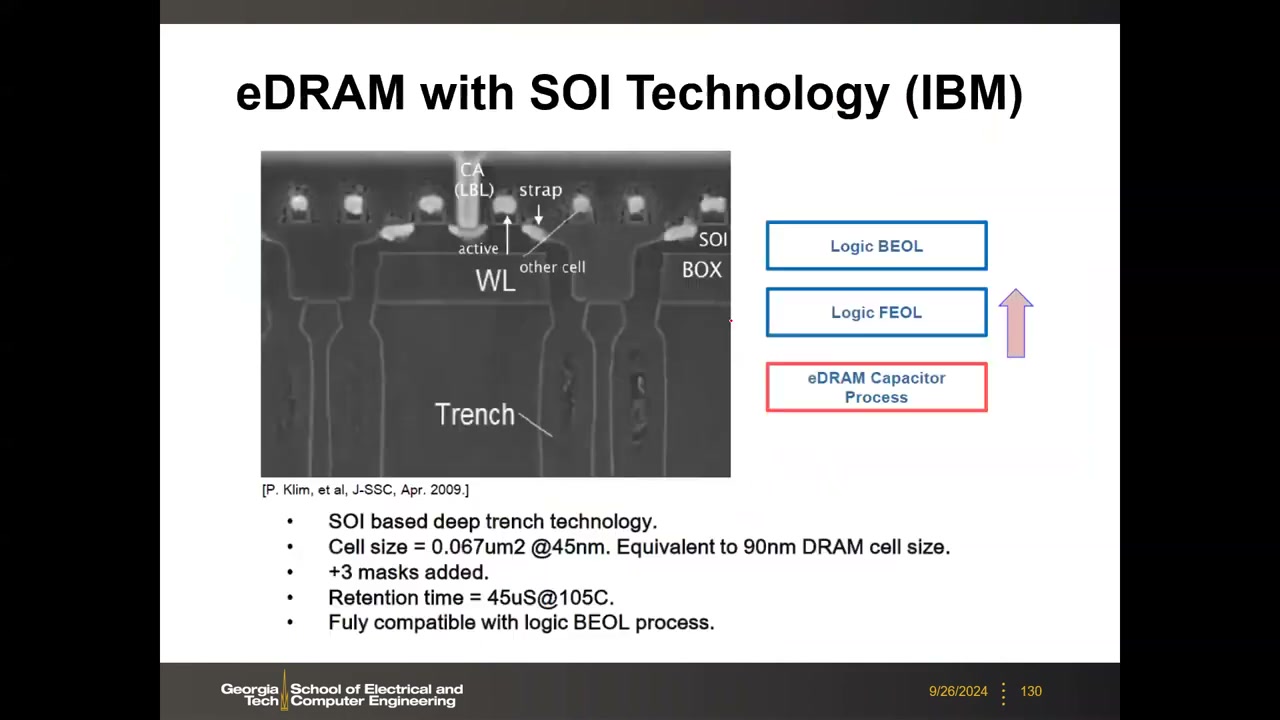
IBM SOI 深沟槽 eDRAM P5 00:25:06:深沟槽电容先做、晶体管后做,与逻辑 FEOL/BEOL 完全兼容,仅 +3 道掩膜。45nm 数据:单元 0.067 µm²(≈32F²,大于独立 DRAM 的 6–8F²,但远小于同节点 SRAM 的 ~160F²);保持时间仅 45 µs @105°C(用的是普通逻辑晶体管而非低漏电存取管,对比独立 DRAM 的 64 ms)。商用于 Power 系列处理器的 L3 缓存(行周期 ~2 ns,达不到 L1/L2 但密度高):
| IBM Power8 | IBM Power9 | |
|---|---|---|
| eDRAM 工艺 | 22nm 平面 HK-MG SOI | 14nm HP FinFET HK-MG SOI |
| 单元面积 / 归一化 | 0.026 µm² / 54F² | 0.0174 µm² / 89F² |
| 存储节点电容(估计) | ~12.2 fF | ~8.1 fF |
| L3 缓存密度 | 11.9 Mb/mm² | 13.28 Mb/mm² |
Intel eDRAM(22nm FinFET + 堆叠电容 COB) P5 00:30:09:单元 0.029 µm²、1.05 V;第 1 代 2 GHz / 随机周期 3 ns / 保持 100 µs @95°C,第 2 代 5 ns / 300 µs。电容纵横比仅 5–8(独立 DRAM 为 50–70)。结局:只发论文、从未用于任何产品。2020 年后已无商用 1T1C eDRAM——保持太短、刷新开销太大。
无电容方案一:1T 浮体 eDRAM P5 00:33:44:SOI 晶体管体区悬浮,写入时碰撞电离/BTBT 产生的空穴积累在浮体中 → 体电位升高 → Vth 下降 → 读电流大("1");空穴复合后消失,需刷新。无电容易集成,但干扰与保持设计难,仅停留在概念。
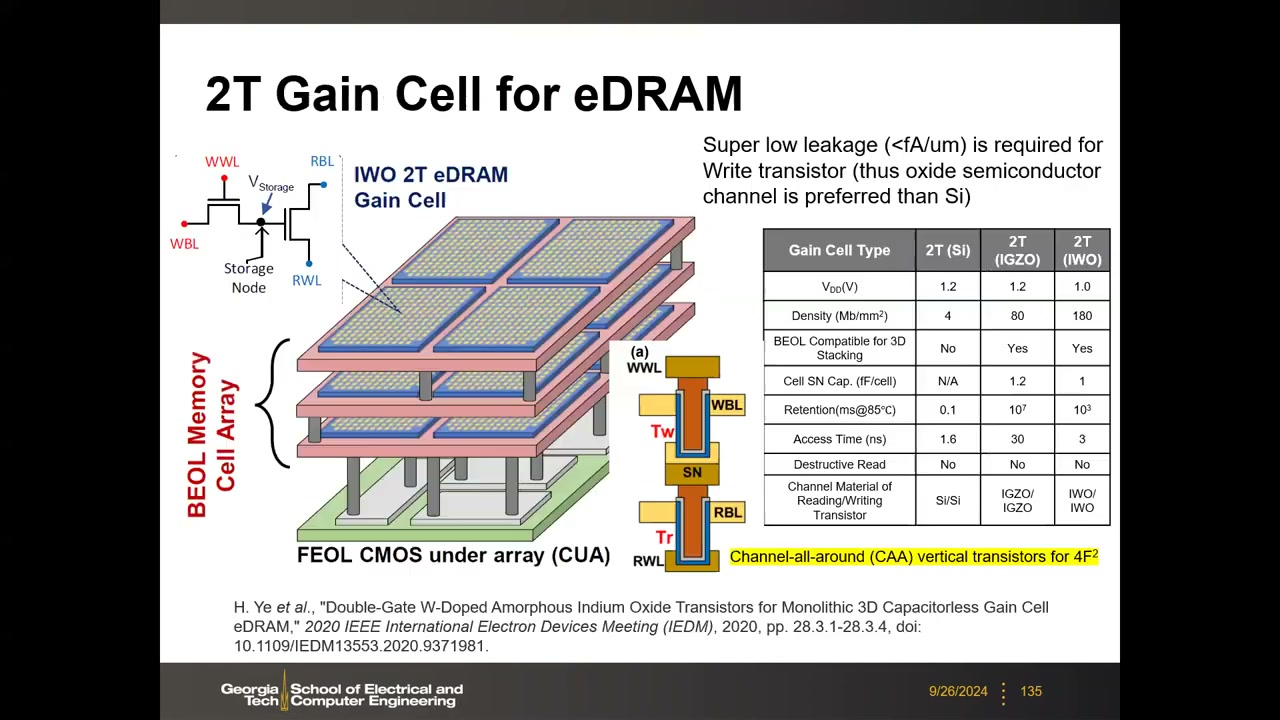
无电容方案二:2T 增益单元(Gain Cell,近年热门) P5 00:37:14:写晶体管向存储节点注入电荷,读晶体管的栅接存储节点,靠读管跨导放大读出(非破坏性读)。突破在于用氧化物半导体(IGZO/IWO)做写管——关态漏电比硅低数个数量级,保持时间从百微秒级跃升到秒级以上:
| Gain Cell 类型 | 2T (Si) | 2T (IGZO) | 2T (IWO) |
|---|---|---|---|
| VDD | 1.2 V | 1.2 V | 1.0 V |
| 密度 (Mb/mm²) | 4 | 80 | 180 |
| BEOL 兼容 3D 堆叠 | 否 | 是 | 是 |
| 保持时间 (ms @85°C) | 0.1 | 10⁷ | 10³ |
| 访问时间 (ns) | 1.6 | 30 | 3 |
| 破坏性读出 | 否 | 否 | 否 |
作为最后一级缓存(LLC)时数据本来就频繁更新,秒~分钟级保持意味着几乎不需要刷新。垂直 CAA 双管堆叠可缩到 4F²,密度甚至可超 3nm 节点 SRAM;挑战是氧化物晶体管的稳定性/可靠性。Macronix 还提出 2T 增益单元 3D 堆叠 DRAM(VLSI 2024)与栅控晶闸管(GCT)3D DRAM(IEDM 2022/2023)——"这是 DRAM 研究的黄金时代"。
17. DRAM 展望(章节总结) P5 00:46:25
- DRAM 不可替代:没有任何现有或新兴存储器能同时具备 DRAM 的访问速度(几 ns 至几十 ns)、低成本(6–8F² + 单 die ~32 Gb)与无限耐久三者;可预见的未来 DRAM 无法被取代。
- HBM 是 GPU 与 AI 硬件的使能者:更大容量与更高带宽靠多层 DRAM 的 3D TSV 集成(HBM)解决。
- sub-10nm DRAM 处于转折点:沿 3D NAND 路径的 3D 垂直堆叠 DRAM 预计 3–5 年内出现技术突破;过渡步骤可能是用垂直沟道晶体管(或 IGZO)把 6F² 缩到 4F²。
- eDRAM 新形态(如 2T 增益单元)有望实现与逻辑工艺兼容的 GB 级最后一级缓存。

本讲要点总结
- DRAM 三属性:Dynamic(需刷新)、Random Access、Volatile;单元面积 6–8F²(SRAM ~140F²),漏电要求 <1 fA/cell(SRAM >1 pA/cell),破坏性读、读后必须写回。
- 子系统层级 Channel→DIMM→Rank(64-bit)→Chip(×8)→Bank(16k×16k=256 Mb,带 Row-buffer)→Mat(1k×1k=1 Mb,含 BLSA/SWD)。
- DRAM 内部时钟恒为 ~200 MHz(CSL 5 ns 节拍);DDR 靠 Prefetch 2/4/8 + 双沿传输把每引脚速率提到 400/800/1600 Mbps;系统带宽 BW = Gbps/pin × #pins(算例:12.8 GB/s ÷ 64 pin = 1600 Mb/s/pin → DDR3 8:1 串行化)。
- 电荷分享感测裕量(必考):ΔV_BL = [1/(1+C_BL/C_SN)]·(½VDD);考虑泄漏:ΔV_BL = [1/(1+C_B/C_S)]·(½VDD − I_L·t_RET/C_S),设计要求 ≥200 mV;延迟 τ = R_T·C_S·C_B/(C_S+C_B),T_d ≈ 2.3τ。
- BL 预充 ½VDD 使读 0/1 对称;WL 用 VPP(~1.8 V)升压降低导通电阻、待机用负压 V_BBW 抑制亚阈值泄漏;完整读 = 电荷分享 → 写回 → 预充三阶段,t_RCD ≈ 15 ns、t_RC ≈ 40–50 ns。
- 存 "1" 比存 "0" 难保持(结泄漏 + GIDL + 亚阈值三路放电);GIDL 源于栅漏交叠区带带隧穿,负字线会加剧它。
- JEDEC 刷新周期 64 ms 由极少数尾部位决定;刷新由"读"完成;16k 行/40 ns/64 ms → 行间隔 4 µs、开销约 1%(大容量芯片现约 8–10%,能量 ~15%)。
- Row Hammer:反复访问同一行经字线耦合使邻行(victim cell)数据翻转,是安全攻击手段,也限制字线间距微缩。
- 沟槽电容 70 nm 后停产(仅存于 eDRAM);堆叠电容 + 开放位线 6F²(斜沟道)为现行主流;8F²(折叠位线)已停产、4F²(垂直晶体管)在研。
- C_BL 跨代不缩放 ⇒ C_SN 必须维持 5–10 fF:靠高 K(ZrO₂,k≈40,EOT 3–5 Å)+ 越堆越高(柱状电容,A/R 逼近 100,需机械支撑层)。
- 存取晶体管为低漏电而生(I_off < 1 fA/µm):RCAT(90nm)→ Saddle FinFET(45nm)→ 埋入式字线 BCAT(32nm,WL 电容降至 1/3);air gap(ε≈1)削减 BL-SN 寄生。
- 20 nm 以下实际单元面积已偏离 6F²(D1z 实际 ~8F²);sub-10nm 两条路线:4F² 垂直沟道晶体管(IGZO,I_off < 10⁻²⁰ A/µm)与单片 3D VSDRAM(水平 1T1C 堆叠,SK Hynix 已演示 5 层,盈亏平衡约需 64–100 层)。
- HBM 走"低速 pin × 1024 宽接口"路线:对比 GDDR5 带宽 3.6×(~1 TB/s)、封装面积 −75%、能效 +18%;每 2 年容量与带宽 ~1.5×;HBM4 将上 16-Hi、2048 I/O、Cu-Cu 混合键合;首款 HBM GPU 是 AMD Fiji。
- 3D 堆叠的根本矛盾是供电与散热(retention 随温度退化);TSV(C 50–500 fF、间距 10–50 µm)→ micro-bump(20–30 µm)→ hybrid bonding(<5 µm)是互连密度演进主线。
- eDRAM 定位于 SRAM 与 DRAM 之间(面积差 20–30×、速度差 50–100×):IBM 深沟槽方案曾商用于 Power L3,Intel COB 方案未量产;2T 增益单元 + 氧化物半导体(IGZO/IWO)保持时间达秒级、几乎免刷新,是 GB 级 LLC 的有力候选。
术语表
| 英文术语 | 中文 | 解释 |
|---|---|---|
| DRAM (Dynamic Random Access Memory) | 动态随机存取存储器 | 用 1T1C 单元存数据、需周期性刷新的易失性主存。 |
| 1T1C | 一晶体管一电容 | DRAM 基本存储单元:1 个 NMOS 存取管 + 1 个存储电容 = 1 bit。 |
| Refresh | 刷新 | 周期性(JEDEC 64 ms)对每行执行读操作以恢复单元电荷,开销约 1%。 |
| Destructive read | 破坏性读 | 电荷分享感测会破坏单元原数据,必须随后写回。 |
| Write-back / Restore | 写回 / 恢复 | 灵敏放大器把 SN 电压充回 VDD 的过程,属于读操作的一部分。 |
| Retention time | 数据保持时间 | 泄漏导致数据丢失前可保持的时间,几十 ms 至秒级,随温度升高退化。 |
| Tail bits | 尾部位 | 保持时间分布中最差的极少数单元,决定 64 ms 刷新规格。 |
| F² (feature size squared) | 特征尺寸平方 | 以特征尺寸 F 的平方衡量单元面积:SRAM ~140F²,DRAM 6–8F²。DRAM 的 F = M1 半节距,是真实尺寸。 |
| Channel / DIMM / Rank / Bank / Mat | 通道 / 内存条 / 列组 / 存储库 / 子阵列 | DRAM 子系统自顶向下的组织层级;Bank 是可独立传输数据的最小单位,Mat 为 Bank 内约 1k×1k 的基本阵列块。 |
| Row buffer | 行缓冲 | 阵列边缘的灵敏放大器阵列,暂存被激活整行(如 2kB)数据。 |
| BLSA / SWD | 位线灵敏放大器 / 子字线驱动器 | Mat 的组成电路:感测放大位线信号 / 驱动局部字线。 |
| DDR (Double Data Rate) | 双倍数据速率 | 时钟上升、下降沿都传数据的 DRAM I/O 协议,每代 I/O 时钟翻倍。 |
| Prefetch / Burst | 预取 / 突发 | 内部以 200 MHz 并行取出 2/4/8 倍数据,I/O 端高速串行突发输出。 |
| CSL (Column Select Line) | 列选择线 | 列访问选通脉冲(2.5 ns 脉宽 + 2.5 ns 间隔 = 5 ns),决定 ~200 MHz 内部时钟。 |
| JEDEC | 联合电子器件工程委员会 | 制定 DRAM 接口/刷新等行业标准的组织。 |
| IDM (Integrated Device Manufacturer) | 整合器件制造商 | 设计到制造全自营的厂商模式;DRAM 三大厂均如此,无 DRAM 代工厂。 |
| LPDDR / GDDR | 低功耗 DDR / 图形 DDR | 分别面向移动(功耗优先)与图形(性能优先,短位线短字线)的 DRAM 产品。 |
| Word Line (WL) / Bit Line (BL) | 字线 / 位线 | 行选择线(控制存取管栅)/ 单元与灵敏放大器间数据通路(DRAM 单元只接一条 BL)。 |
| Storage Node (SN) / Plate Line | 存储节点 / 公共板 | 电容存电荷的一端(VDD=1,0V=0)/ 所有单元共享、电位恒定的另一端。 |
| Charge Sharing | 电荷分享 | 读操作中 SN 与位线寄生电容间的电荷再分配,产生感测信号 ΔV。 |
| Sense Margin (ΔV_BL) | 感测裕量 | 电荷分享后位线偏离 ½VDD 的电压 = ½VDD/(1+C_BL/C_SN),需 ≥200 mV。 |
| Sense Amplifier / SAEN | 灵敏放大器 / 使能信号 | 交叉耦合锁存,差分放大 ΔV 并完成写回;SAEN 开启前锁存浮空。 |
| Offset Cancellation | 失调消除 | 最新节点灵敏放大器增加的两对晶体管,补偿差分对失配。 |
| VPP / V_BBW | 字线升压 / 负字线电压 | 激活时字线升至高于 VDD 的电压(~1.8 V,降低导通电阻);待机时低于地(抑制亚阈值泄漏)。 |
| Equalizer / Precharge | 均衡 / 预充电路 | EQL 控制的 3 管电路,把 BLt/BLc 短接并预充到 ½VDD。 |
| t_RCD / t_RC | 行到列延迟 / 行周期时间 | WL 开启到可开灵敏放大器(~15 ns)/ 完整读+写回+预充周期(40–50 ns)。 |
| GIDL (Gate-Induced Drain Leakage) | 栅致漏极泄漏 | V_GD<0 时栅漏交叠区能带强弯导致带带隧穿(BTBT)产生的泄漏,负字线会加剧。 |
| Subthreshold Leakage (I_off) | 亚阈值泄漏 | 晶体管关断时仍流过沟道的微弱电流;DRAM 存取管要求 <1 fA/µm。 |
| Row Hammer / Victim Cell | 行锤攻击 / 受害单元 | 反复访问同一行借字线耦合使相邻行数据翻转的攻击;被干扰的单元。 |
| Trench / Stacked Capacitor (STC) | 沟槽 / 堆叠电容 | 埋入硅内的电容(70 nm 后仅存于 eDRAM)/ 晶体管上方堆叠的圆筒或柱状电容(现行主流)。 |
| Folded / Open Bit-line | 折叠 / 开放位线 | 差分位线对取自同一阵列(8F²,噪声免疫好)/ 相邻两个子阵列(6F²,当今主流)。 |
| Passing Word Line / Staggered Cell | 穿越字线 / 交错单元 | 折叠架构中仅穿过不接单元的字线(导致 8F²)/ 隔交点放置单元的布局。 |
| Buried Wordline (bWL / BCAT) | 埋入式字线 | 金属(TiN)字线埋入硅衬底(Qimonda 提出,32 nm 起现役),WL 总电容降至约 1/3。 |
| RCAT / Saddle FinFET | 凹陷沟道晶体管 / 马鞍形鳍式晶体管 | U 形凹槽栅增大 L_eff 降漏电(90nm)/ Recess Gate+FinFET 组合,导通电流 +30%(45nm)。 |
| SIS / MIS / MIM | 电容电极结构三代 | 双多晶硅 → 金属顶电极+HSG 底电极 → 双金属(TiN)电极,MIM 为现行结构。 |
| High-k Dielectric / ZrO₂ | 高介电常数介质 | k 远高于 SiO₂(=4) 的介质;现行主流 ZrO₂(k≈40);k 与带隙 Eg 成反比折衷。 |
| EOT (Equivalent Oxide Thickness) | 等效氧化层厚度 | 把高 K 介质折算为等效 SiO₂ 厚度,今日 DRAM 电容约 3–5 Å。 |
| Aspect Ratio (AR) | 深宽比 | 电容柱高度 ÷ 直径,今日柱状电容逼近 100,需机械支撑层(MESH)。 |
| Cylinder / Pillar Capacitor | 圆筒 / 柱状电容 | U 形薄壁 / 实心柱存储节点;柱状省去 SN 电极厚度项,支持继续缩放。 |
| ALD (Atomic Layer Deposition) | 原子层沉积 | 能均匀覆盖超高深宽比结构的逐原子层薄膜工艺。 |
| Air Gap / Air Spacer | 空气隙 | 位线侧壁空洞(ε≈1,介电常数下限),sub-20nm 起用于削减位线寄生电容。 |
| VCT (Vertical Channel Transistor) | 垂直沟道晶体管 | 沟道垂直于衬底的环栅硅柱晶体管,是实现 4F²(2F×2F)的唯一途径。 |
| IGZO / IWO | 铟镓锌氧化物 / 铟钨氧化物 | 宽带隙(~3.2 eV)氧化物半导体沟道,I_off 可低于 10⁻²⁰ A/µm,使 4F² 与增益单元复兴。 |
| VSDRAM (Vertically Stacked DRAM) | 垂直堆叠 DRAM | 把 1T1C 旋转 90° 水平放置并单片堆叠多层的 3D DRAM 架构。 |
| Bit-cost scalable (BiCS) | 位成本可微缩 | 源自 3D NAND:多层一次沉积、一次光刻、一次刻蚀,每位成本不随层数线性上升。 |
| Monolithic 3D | 单片三维集成 | 同一 die 上逐层顺序制造存储阵列,区别于键合堆叠的"伪 3D"(如 HBM)。 |
| TSV (Through-Silicon Via) | 硅通孔 | 穿透硅片的铜垂直互连:R 0.01–0.1 Ω、C 50–500 fF、间距 10–50 µm、A/R 5–20;含专司导热的热 TSV。 |
| Interposer / CoWoS | 硅中介层 / TSMC 2.5D 封装 | 承载 GPU 与 HBM 并提供高密度水平布线的硅基板;CoWoS 是其主流集成方案。 |
| Micro-bump / Hybrid bonding | 微凸点 / 混合键合 | SnAg 微焊点(20–40 µm 间距)/ 无凸点 Cu-Cu + 介质直接键合(<5 µm,HBM4 采用)。 |
| HBM (High Bandwidth Memory) | 高带宽存储器 | 多层 DRAM die 经 TSV 堆叠在逻辑 base die 上,1024-bit 宽接口,系统带宽 >1 TB/s。 |
| Base die / Buffer die / PHY | 基底 die / 物理层 | HBM 栈底部的逻辑 die,集成 I/O 接口、PHY、时序与调度电路。 |
| eDRAM (Embedded DRAM) | 嵌入式 DRAM | 集成在处理器上、与逻辑工艺兼容的 DRAM,定位在 SRAM 与独立 DRAM 之间(曾用作 IBM Power L3)。 |
| COB (Capacitor over Bit-line) | 位线上方电容 | 电容置于位线之上的单元架构(Intel 22nm eDRAM 采用,未量产)。 |
| Floating body effect | 浮体效应 | SOI 体区悬浮、空穴积累抬高体电位使 V_th 漂移;可作 1T 无电容 DRAM,也需 VSDRAM 抑制。 |
| Gain Cell | 增益单元 | 2T 无电容 DRAM:写管注入电荷、读管跨导放大读出(非破坏性);配 IGZO/IWO 后保持达秒级。 |
| LLC (Last Level Cache) | 最后一级缓存 | 片上缓存最末级(L3/L4),eDRAM/增益单元的目标应用。 |
| ECC (Error Correction Code) | 纠错码 | 纠正失效位的冗余编码;尾部失效位数可能超出其能力,故仍需 64 ms 刷新。 |