Lecture 5:FLASH 闪存
1. FLASH 概览:历史、应用与市场格局 P1 00:02:06
FLASH 闪存是数字时代的存储基石:SSD、USB 盘、手机和 SD 卡背后都是它。存储(storage)区别于内存(memory)的关键是非易失性——掉电后数据长期保持。存储介质按机理分三类:磁存储(磁带 1928、IBM 硬盘 1956、软盘)、半导体存储与光存储(CD/DVD/蓝光,本课不展开)。半导体非易失存储的演进链条为:PROM(1956,周文俊)→ DRAM(1966)→ EPROM(1971,UV 擦除)→ EEPROM(1978,电擦除)→ Flash(1984,Toshiba 舛冈富士雄) → NAND Flash(1987,Toshiba)→ NOR Flash(1988,Intel)→ 首个 TB 级 SSD(2003)。"Flash" 一词即由舛冈富士雄博士提出;而浮栅存储器概念更早,由贝尔实验室 Kahng 与 Sze(施敏)于 1967 年提出并申请专利(US 3,500,142)。
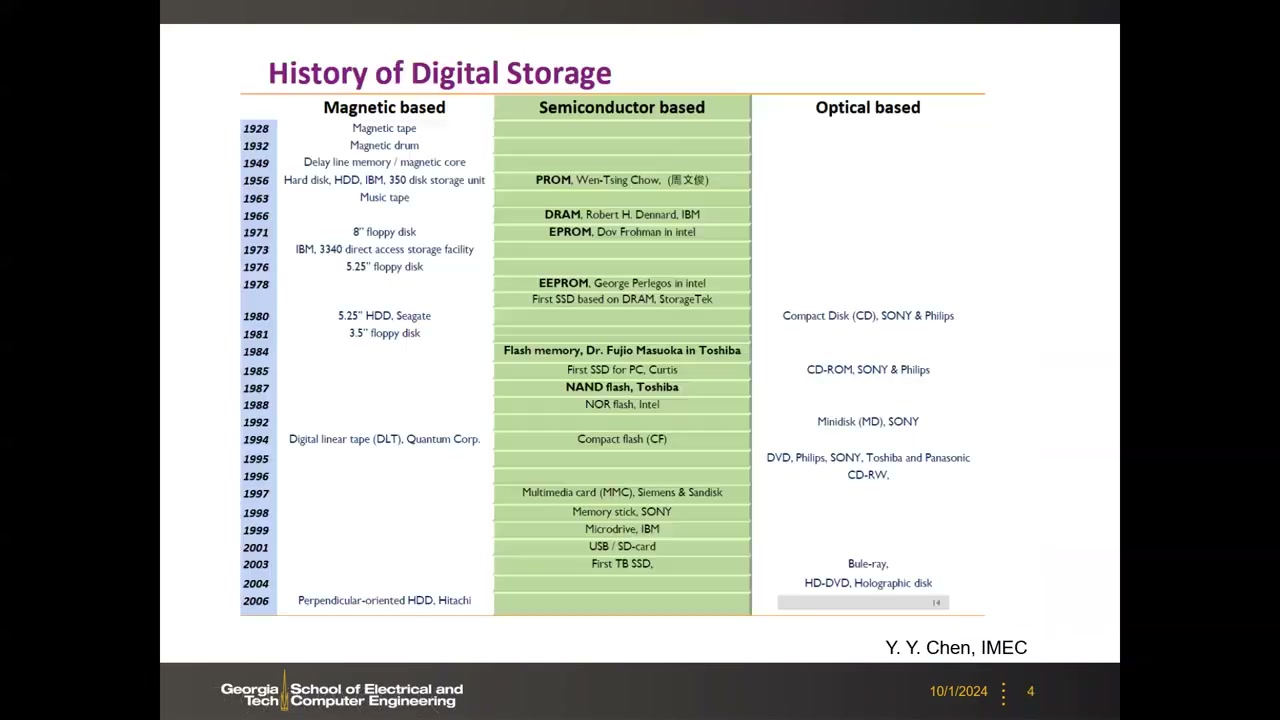
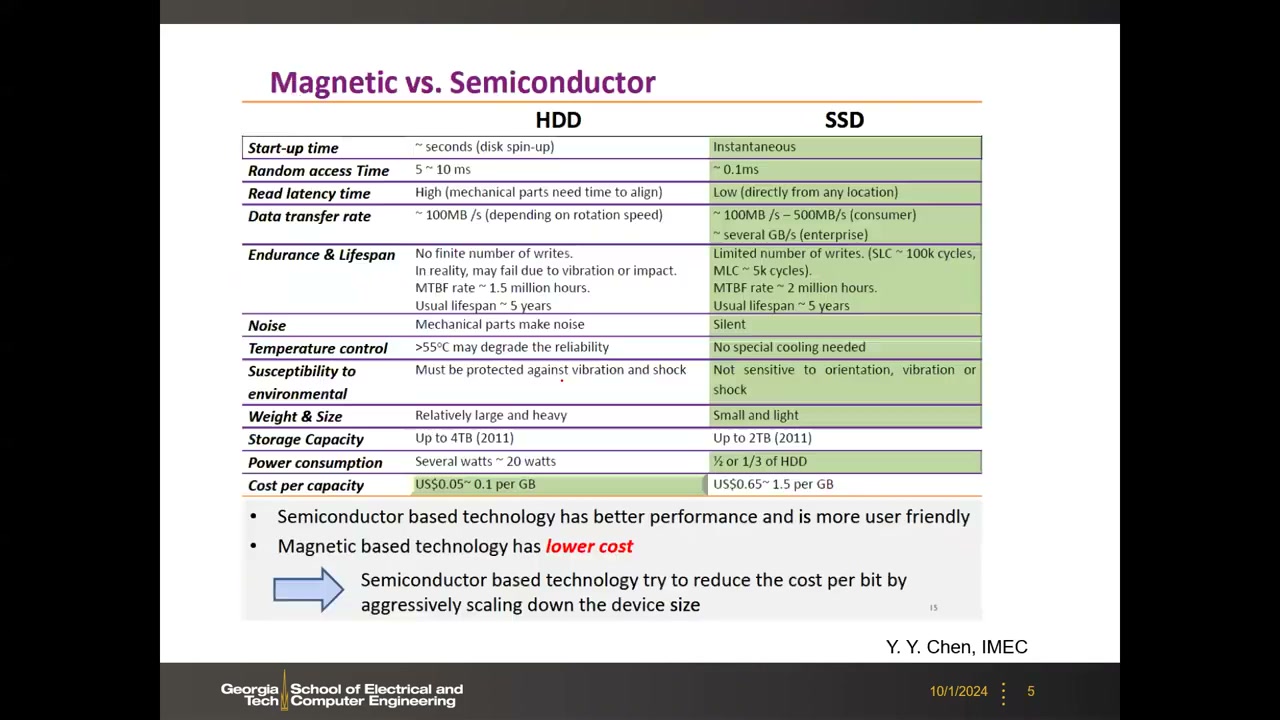
SSD 与 HDD 的对比 P1 00:09:09:HDD 寻址完全是机械的(约 7200 RPM + 磁头定位,读出靠巨磁阻 GMR 效应),随机访问 5–10 ms 且怕震动;SSD 随机访问约 0.1 ms、即时启动、静音抗震,但写入次数有限(SLC 约 10 万次、MLC 约 5 千次)。值得注意的是 HDD 的数据保持远好于 Flash——百年量级归档仍需 HDD,SSD 数年到十年即可能退化。结论:半导体方案性能好,磁存储成本低,半导体靠激进微缩降低每 bit 成本。
工艺微缩 30 余年:1986 年 1.5 µm 一路缩到 2011 年 2x nm;NAND 单 die 容量从 2001 年 1 Gb(160 nm)增至约 2015 年的 128 Gb(1Z nm,第三代 sub-20 nm 节点),随后 2D 微缩走到尽头,业界转向 3D NAND(见第 14 节)。接口方面,SATA 兼容 HDD、带宽受限约 600 MB/s;NVMe 走 PCIe 可达约 7000 MB/s,是现代 SSD 与手机的主流 P1 00:14:53。
市场格局 P1 00:17:31:NAND 年营收超 600 亿美元,2023 年份额为 Samsung 34.1%、Kioxia(前 Toshiba Memory)18.8%、Western Digital(2015–16 收购 SanDisk)13.9%、SK Hynix 13.2%、Micron 10.9%、Intel 6.2%(NAND 部门已售予 SK Hynix 组建 Solidigm)。历史上 DRAM 市场比 NAND 大约 10–20%;近年因 HBM/AI 需求 DRAM 营收显著领先——NAND 离 GPU 较远,没分到多少 AI 红利。
2. 浮栅晶体管:结构与存储原理 P1 00:24:09
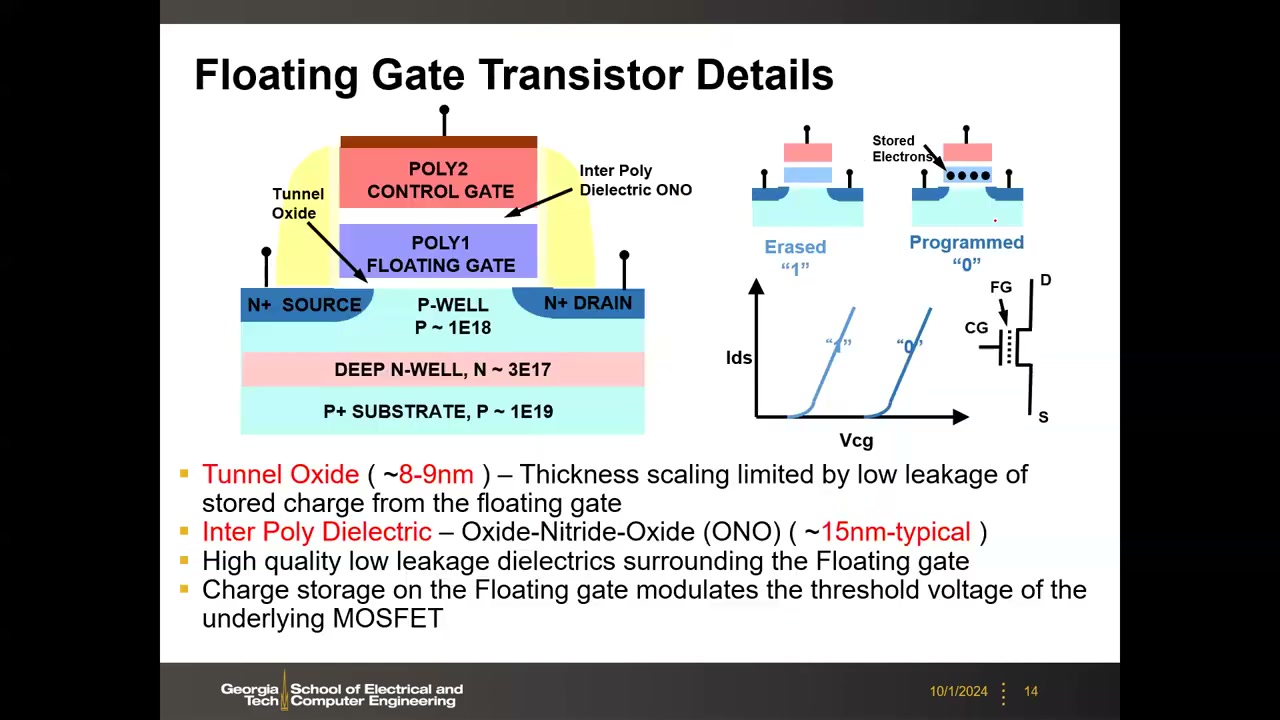
浮栅晶体管 = 常规 MOSFET 的栅叠层中插入一层浮置栅(Floating Gate,FG):两层氧化物夹住浮栅,上方为控制栅(Control Gate,CG),早期 FG 与 CG 均为多晶硅。存储机理:以浮栅中是否存有电子表示数据——有电子 → Programmed(编程)态,数据 "0";电子被移除 → Erased(擦除)态,数据 "1"。浮栅无外部电极,只能对控制栅、源漏施加电压;IDS–VCG 特性中编程态相对擦除态阈值电压右移 ΔVT。

实际剖面结构 P1 00:28:22(自上而下):POLY2 控制栅 / Inter-Poly Dielectric(IPD,ONO 三明治,总厚约 15 nm)/ POLY1 浮栅 / 隧穿氧化层(Tunnel Oxide,SiO₂ 约 8–9 nm) / 沟道。隧穿氧化层远厚于逻辑晶体管的栅氧(2–3 nm),其厚度微缩受"低泄漏保持存储电荷"要求限制;浮栅周围必须是高质量低泄漏介质。
3. 电容耦合模型与耦合比 P1 00:30:38
浮栅不可电学访问,分析采用简单电容模型:把器件抽象为连接到浮栅节点的 4 个电容——Ck(控制栅–浮栅,即 IPD 电容)、Cs(浮栅–源)、Cd(浮栅–漏)、Cg(浮栅–沟道),总电容 Ct = Ck + Cs + Cg + Cd。设 VS = VD = VB = 0,只加 VCG:
- 电荷守恒:QFG = (VFG − VCG)·Ck + VFG·(Cs + Cg + Cd) = VFG·Ct − VCG·Ck
- 编程态:VFG = (Ck/Ct)·VCG + QFG/Ct;擦除态(QFG=0):VFG = (Ck/Ct)·VCG′
- 阈值偏移:ΔVT = QFG / Ck(即 ΔVth = ΔQ/CIPD)
- 栅耦合比:αCG = Ck / Ct——控制栅电压只有 αCG 这一比例落到浮栅上(容性分压)。

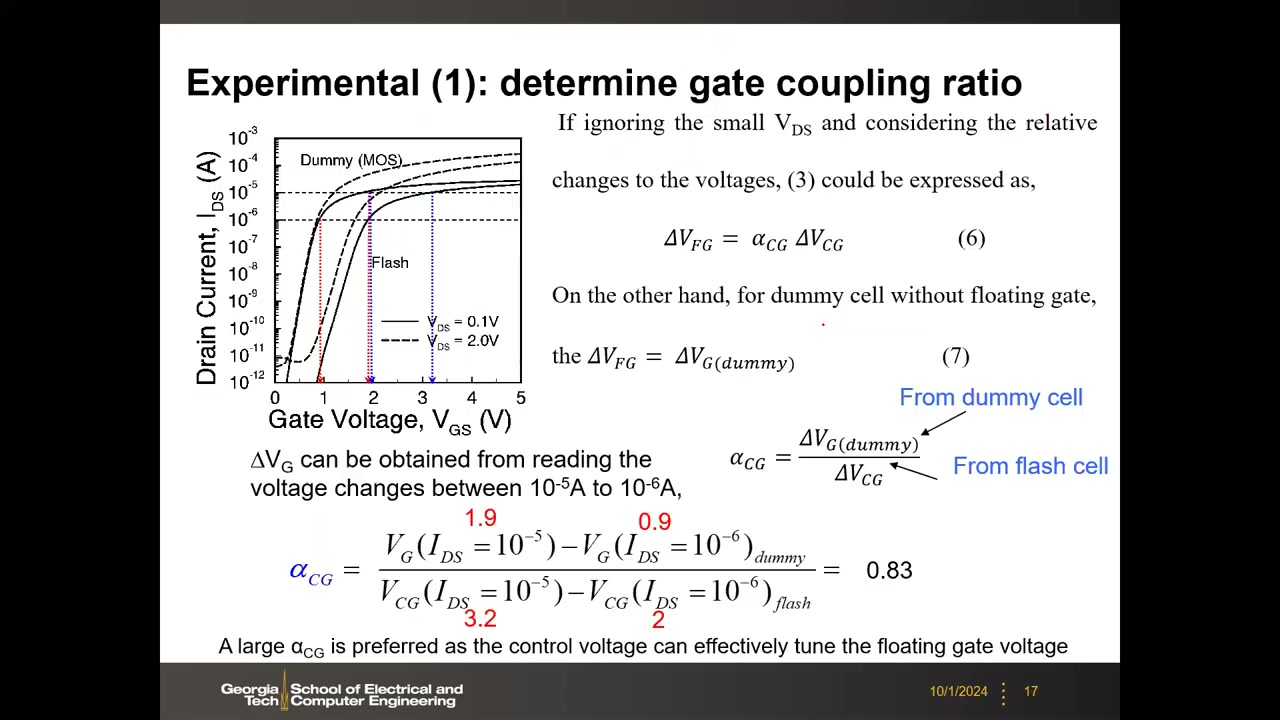
实验测定耦合比 P1 00:39:27:制作同尺寸的 flash 管与 dummy 常规 MOSFET(无浮栅),在线性区(VDS=0.1 V)测 ID–VG。由 ΔVFG = αCG·ΔVCG,且 dummy 单元的栅即"浮栅",故 αCG = ΔVG(dummy)/ΔVCG(flash):读电流从 10⁻⁶ 变到 10⁻⁵ A 时,dummy 需 1.0 V、flash 需 1.2 V,αCG = 1.0/1.2 ≈ 0.83——控制栅每加 1 V 约有 0.83 V 落到浮栅,希望它大。同法比较不同漏压下的曲线偏移可得漏耦合比 αD ≈ 0.12 P1 00:46:22:αD = [(1.1−1.7) − 0.83×(2.1−3.1)]/1.9 ≈ 0.12,远小于 αCG——MOSFET 应是栅控器件而非漏控器件,希望 αD 小。
4. 编程/擦除机理:FN 隧穿与沟道热电子 P1 00:53:27
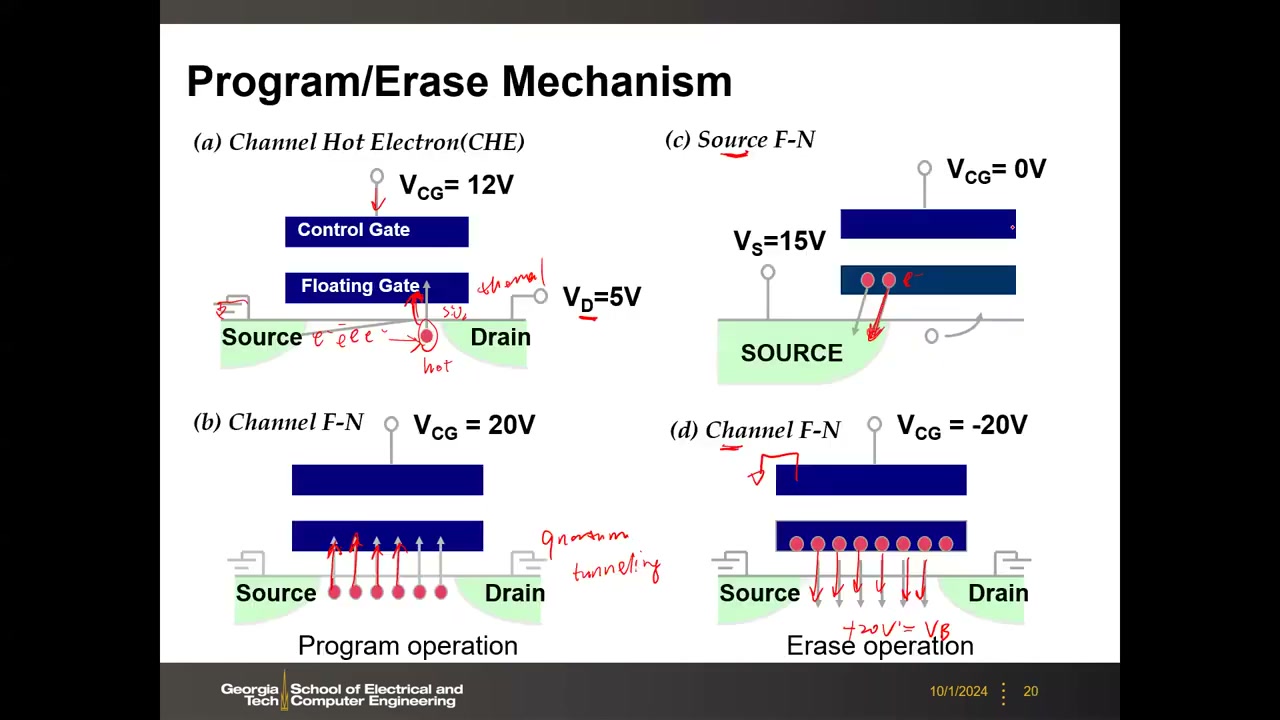
Flash 工作电压很高(12–20 V,对比逻辑管约 1 V)。编程(注入电子)两种机理:(a) 沟道热电子 CHE——典型 VCG=12 V、VD=5 V,大漏电流中少数电子获得足够动能"变热",热跃过 SiO₂ 势垒进入浮栅(热过程,NOR 采用);(b) 沟道 FN 隧穿——VCG=20 V,沟道电子量子隧穿穿过隧穿氧化层(NAND 采用)。擦除(移出电子)均为 FN 隧穿:(c) 源端 FN(VS=15 V、栅接地);(d) 沟道 FN(VCG=−20 V,或等价地栅接地、衬底 +20 V)。

Fowler–Nordheim 隧穿 P1 00:58:23:场助隧穿,特指势垒为三角形的情形。SiO₂ 带隙约 9 eV,对硅导带的电子势垒 ΦB = 3.1 eV、空穴势垒 3.8 eV——隧穿对势垒高度指数敏感,故电子主导。电流密度公式:
JFN = α·Eox²·exp(−β/Eox),其中 α = q³m₀/(16π²ħΦBm*),β = 4√(2m*)·ΦB3/2/(3ħq),Eox ≈ Vox/tox 为氧化层电场。实验验证画 log(J/E²) vs 1/E 得直线,斜率 = −β。氧化层薄于约 2 nm 时势垒呈梯形 → 直接隧穿(逻辑器件要避免的栅漏电);Flash 隧穿氧化层约 9 nm,工作在 FN 区——逻辑器件中有害的隧穿,在 Flash 中恰是编程/擦除所依赖的机制。
隧穿氧化层的极端要求 P1 01:05:50:保持 10 年要求泄漏 <10⁻¹⁶ A/cm²,编程(约 1 µs、20 V)要求 >1 A/cm²——小电压窗口内电流需变化 16 个数量级,FN 隧穿的指数特性恰好满足。估算注入电子数:1 A/cm² × (40 nm)² × 1 µs ÷ q ≈ 100 个电子——先进节点一次编程仅注入约百个电子,这是后续可靠性问题的根源。

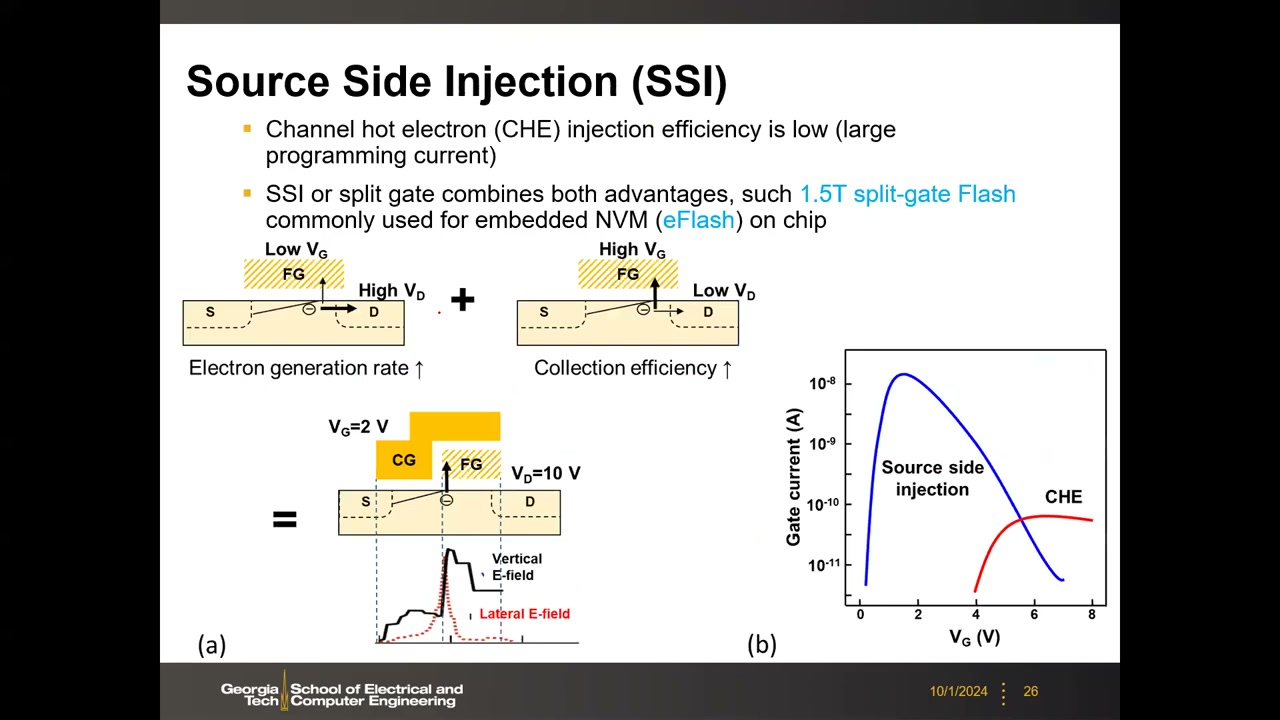
CHE 与幸运电子模型 P1 01:08:31:载流子沿沟道被大漏压加速,能量分布对应高于晶格温度的"温度",漏端附近动能最高;动能高于氧化层势垒的极少数"幸运电子"得以注入浮栅。编程效率 η = IG/ID 仅 10⁻⁶–10⁻⁸(例:ID=2 mA 中只有 50 pA 进入浮栅)。对比:CHE 栅电流大于 FN(编程更快),但 FN 效率接近 100%。改进方案源端注入 SSI / 1.5T 分裂栅 P1 01:12:58:控制栅(VG=2 V)与浮栅(VD=10 V)沿沟道分段,电子先在横向电场峰值处加速、到浮栅下方再被垂直场转向注入,效率大增,广泛用于片上嵌入式 eFlash。
5. NOR 阵列:版图、操作与编程干扰 P2 00:00:03
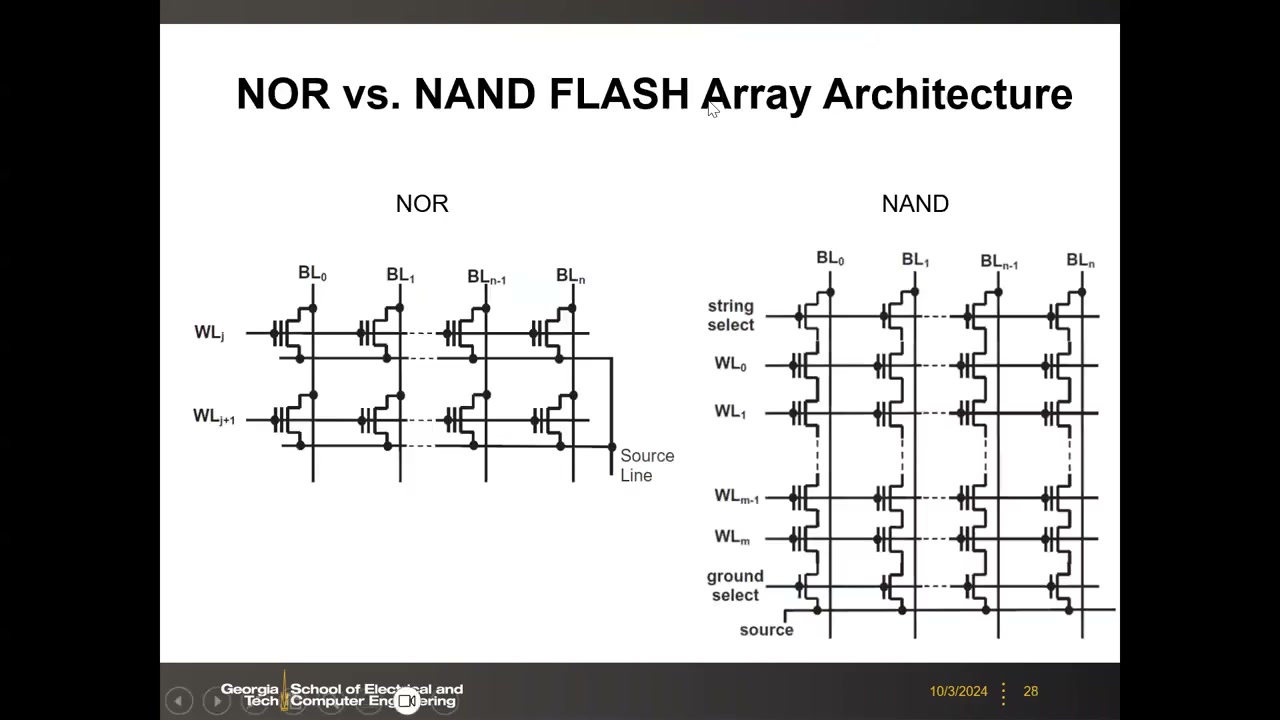
浮栅晶体管组阵列有两种拓扑。NOR 阵列:晶体管并联(似 NOR 门下拉网络),字线接控制栅、位线接漏极、源线共连,每个单元可被字线+位线独立(随机)访问。NAND 阵列:晶体管串联成"串"(string),串顶为串选择管、底为地选择管(均为常规晶体管),分别接位线与公共源线。阵列拓扑直接决定单元尺寸、访问方式、编程机制与应用领域。
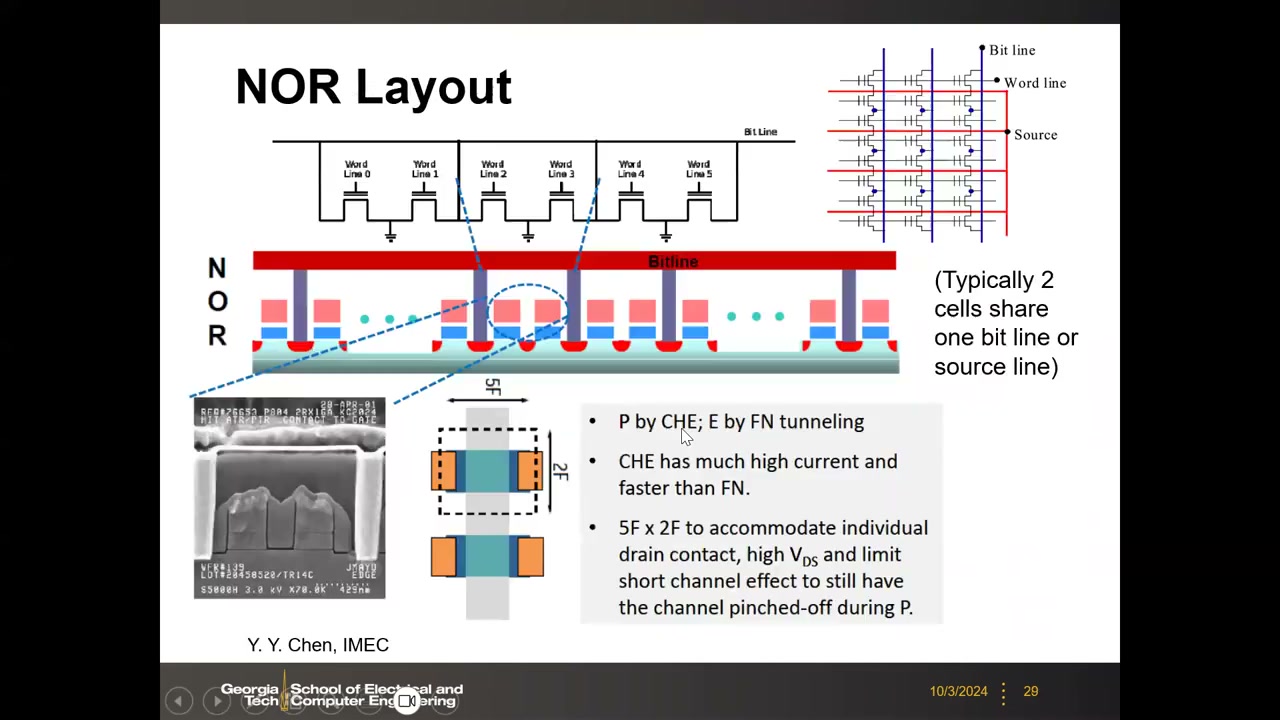
NOR 版图约 10F² P2 00:03:00:相邻两管共享一个位线接触;沿位线方向 = 共享接触 0.5F + 间隔 + 沟道约 2F(CHE 需 5–6 V 高漏压,沟道太短会横向穿通)≈ 5F,垂直方向 2F,单元面积 5F × 2F ≈ 10F²——为实现随机访问必须给每两个晶体管做位线接触,这是 NOR 密度劣于 NAND(4F²)的根本原因。
NOR 单元操作 P2 00:06:54:
| 模式 | 控制栅 CG | 源 Source | 漏 Drain | 机理与特性 |
|---|---|---|---|---|
| 擦除 Erase | 0 V | 12 V | 浮空 | 源端 FN;同一源线上所有单元同时擦除;100 ms–1 s,很慢 |
| 编程 Program | 12 V | 0 V | 6 V / 0 V | CHE,可按位选中;1–10 µs,沟道电流约 600 µA,Vt 漂移 3–5 V |
| 读取 Read | 5 V | 0 V | 1 V | 擦除态有电流 / 编程态无电流;约 50–100 ns,非破坏性;读电压低以防软写入 |
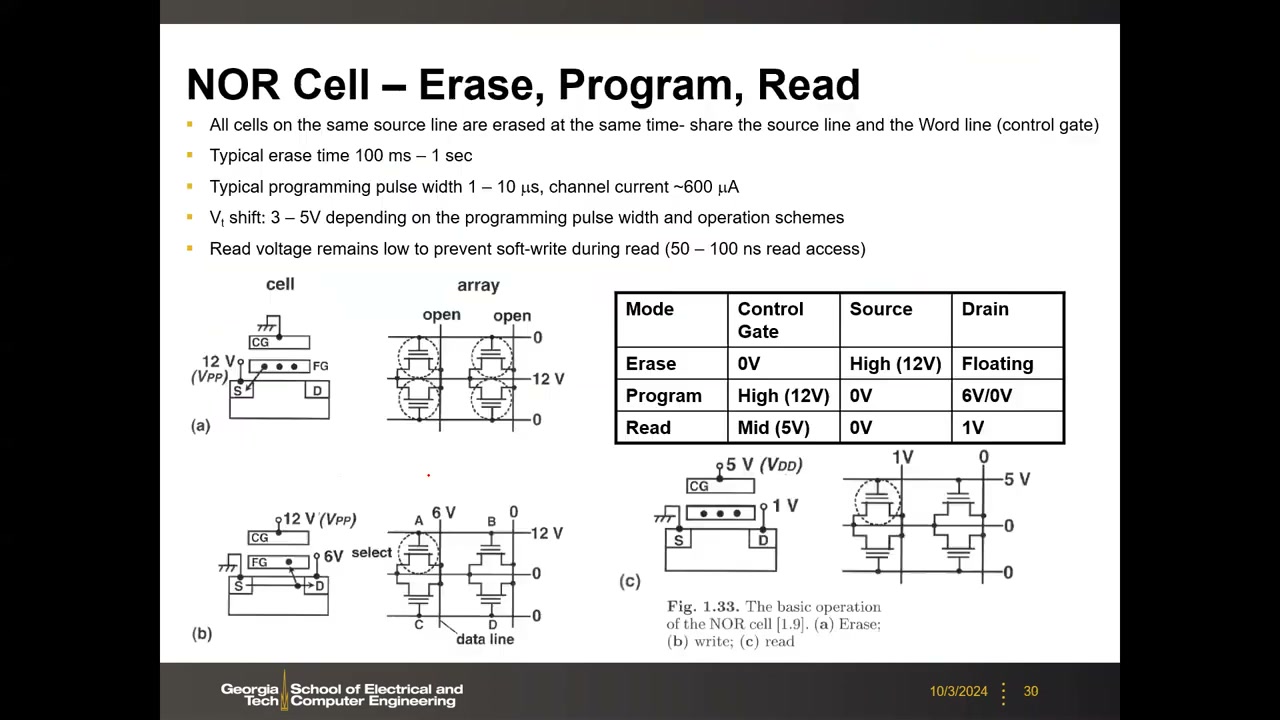
编程干扰 P2 00:14:23:编程单元 A 时,同字线的半选中单元 B(栅 12 V、漏 0 V)仍有少量衬底→浮栅 FN 隧穿,反复编程累积使其 Vt 漂移;同位线的半选中单元 C(字线 0 V、漏 6 V)则可能经漏端 FN 把浮栅电子拉出。只有对角线单元 D 完全未选中。干扰是累积性可靠性问题。
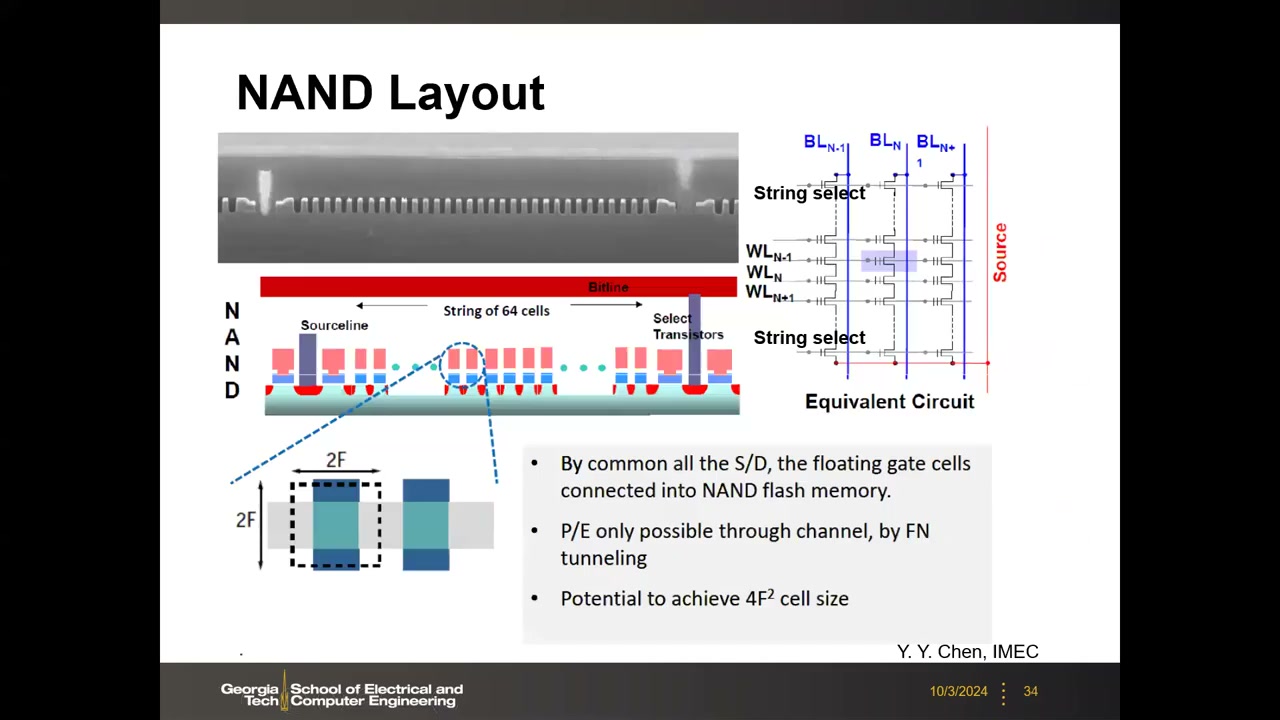
6. NAND 阵列:4F² 单元、页/块组织与块擦除 P2 00:19:28
NAND 串内晶体管源/漏直接共享,串中间没有任何接触孔——只在串两端有位线接触和源线,被约 64 个单元摊薄。每单元沿串方向 2F、垂直方向 2F,单元面积 4F²,是平面晶体管技术的理论最小单元尺寸。一条串典型由 64 个浮栅管(WL0–WL63)加两端选择管组成;因无独立漏接触,编程/擦除只能用沟道 FN 隧穿(不能 CHE)。
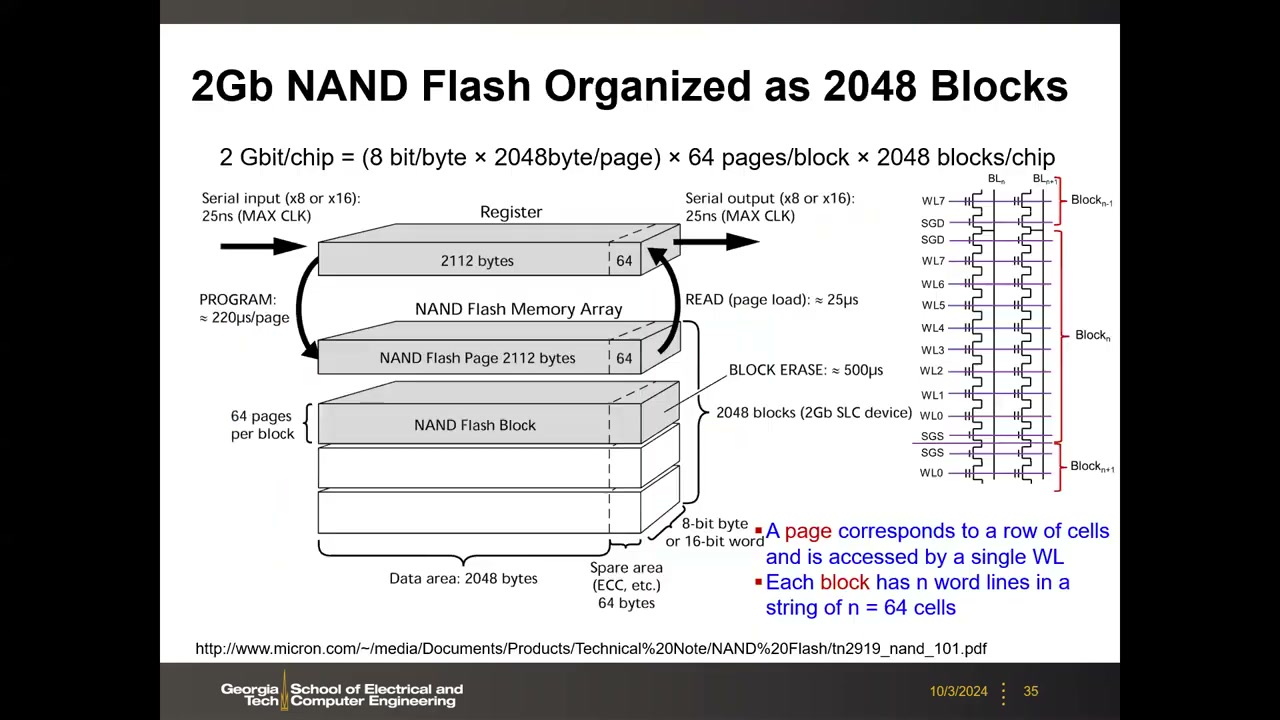
页与块 P2 00:24:16:页 = 一条字线上的所有单元(老一代 2 kB/页,2D 后期可达 16 kB/页,另有 ECC 冗余位);块 = 64 页 × 全部位线,是一个"极扁的矩形"(约 1 MB 量级)。2 Gb SLC 芯片实例(Micron):2 Gbit = (8 bit × 2048 B/页) × 64 页/块 × 2048 块。操作时延:编程 ≈ 220 µs/页、读(页加载)≈ 25 µs、块擦除 ≈ 500 µs。核心规则:读和编程按页执行;擦除按块执行——这是 NAND 一切系统级特性(FTL、垃圾回收)的根源。
块擦除 P2 00:30:23:沟道 FN,按块进行。偏置:选中块所有字线 0 V,P 阱衬底加 20 V;串选/地选栅浮空(不是接地),位线与源线浮空;未选中块字线浮空(无电场不被擦除)。擦除耗时 1–5 ms,是最慢的操作;擦除后所有单元 Vt 变低(耗尽型,Vt<0),数据全为 "1"。
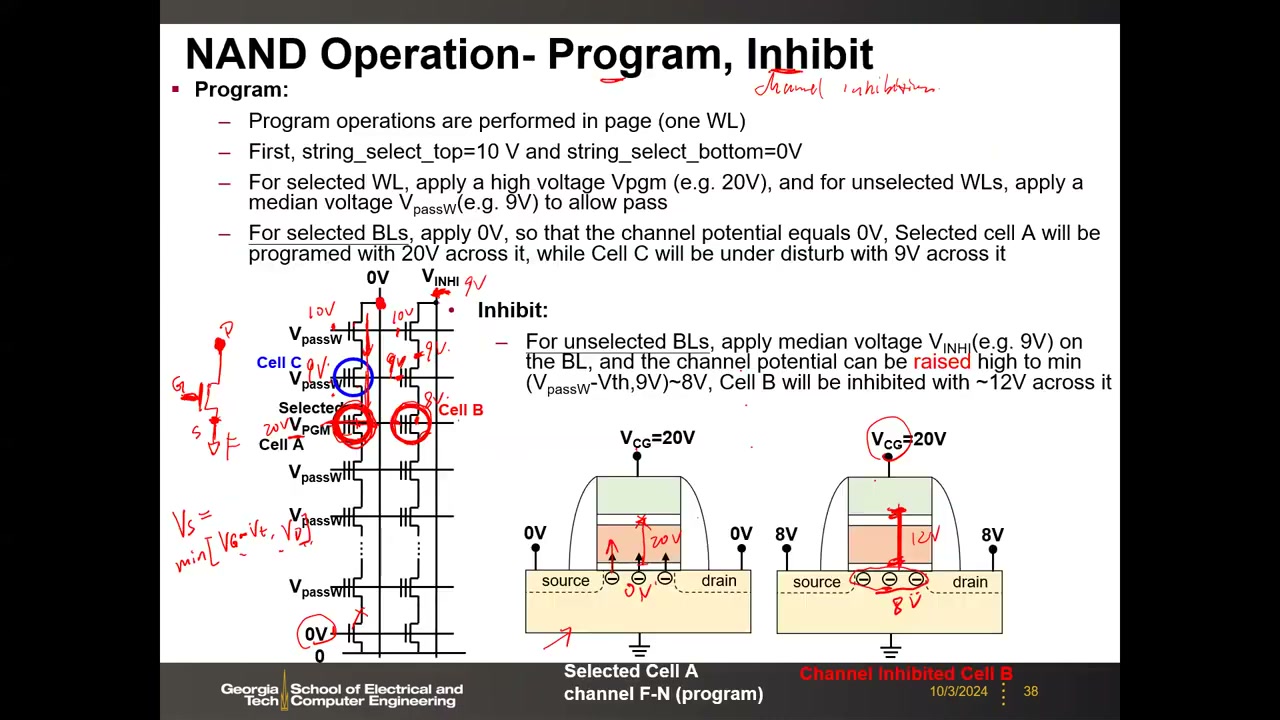
7. NAND 编程与抑制:沟道自举 P2 00:32:44
教授强调这是本讲乃至全课程最难的部分。编程按页执行,但页内只有部分位需要从"1"翻成"0",因此必须同时设计编程与抑制(inhibit)。先记住传输门规则:
早期方案:沟道抑制法。串顶选择管栅 10 V、串底关断;选中字线 VPGM = 20 V,未选字线 VpassW ≈ 9 V。选中位线加 0 V → 0 V 沿串传到选中单元沟道,栅–沟道间 20 V → FN 注入编程。未选位线加 VINH ≈ 9 V → 沟道被抬到约 8 V → 半选中单元上仅约 12 V,不足以编程。缺点:串选管(薄氧常规管)承受 10 V 有可靠性问题,高压位线充放电带来大量 CV² 功耗。
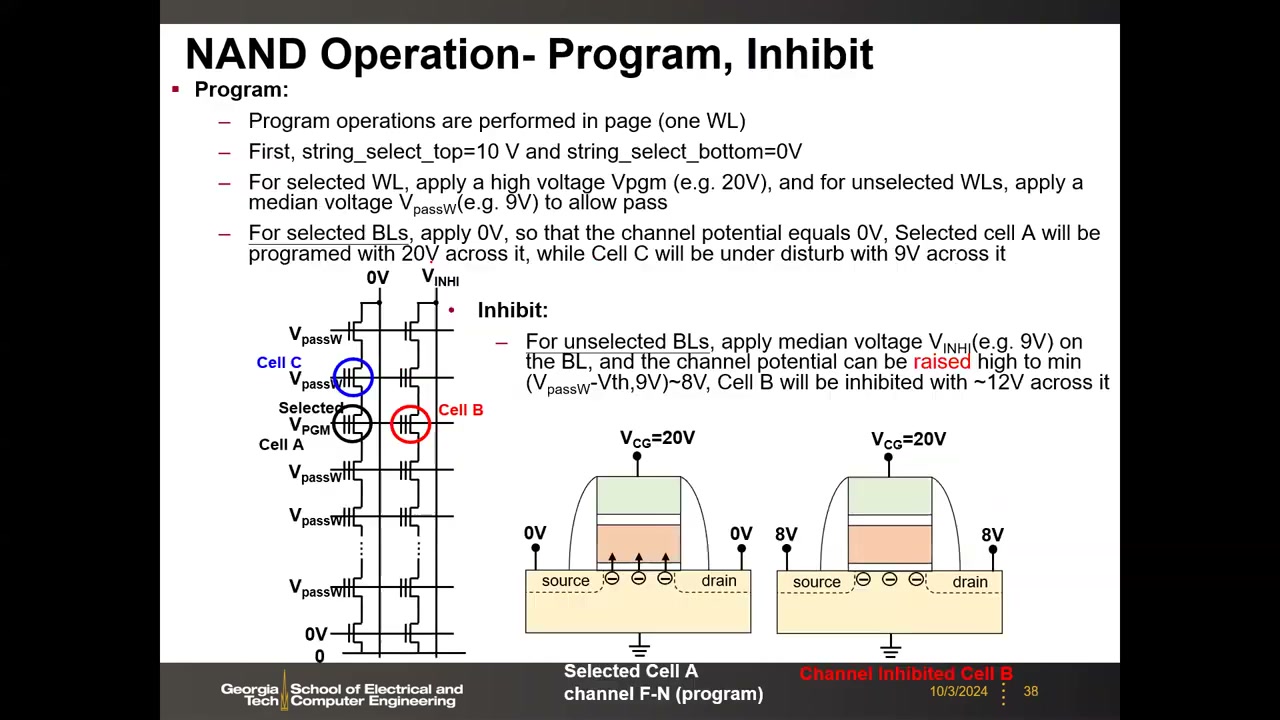
沟道自举(Channel Self-Boost) P2 00:45:48:2D NAND 工业界标准方案。串选管与位线全部只加 VCC = 3 V:抑制串的串选管 VGS ≈ 0 关断 → 沟道两端浮空;时序上先把所有字线抬到 VpassW(约 10 V)让浮空沟道经电容耦合抬升,再把选中字线跳到 VPGM = 20 V。浮空沟道电位由电容分压决定(单元栅电容 Ccell 与沟道–衬底电容 Csub,串长 N):
Vch = [Ccell/(N(Ccell+Csub))]·(N−1)·VpassW + [Ccell/(N(Ccell+Csub))]·VPGM
一阶估算:VPGM 项被 N(如 64)摊薄到可忽略,主导项是 VpassW;若 Ccell ≈ Csub 则分压比约 1/2,Vch ≈ 10 V/2 ≈ 5 V——抑制效率不算高,是该方案的不足。变体 P2 00:53:37:局部自举——选中字线上下相邻字线置 0 V 切断沟道,浮空区只剩选中格,Vch = [Ccell/(Ccell+Csub)]·VPGM ≈ 20 V/2 = 10 V,抑制最强,但 0 V 字线同样切断选中串、影响编程;非对称自举——仅选中单元下方相邻字线置 0 V(上方仍加 VpassW 保证 0 V 传输),沟道共享范围从 N 缩到 M(选中单元位置),Vch = [Ccell/(M(Ccell+Csub))]·[(M−1)·VpassW + VPGM],介于两者之间且不影响编程路径。
8. NAND 读操作与高压外围电路 P2 00:57:51
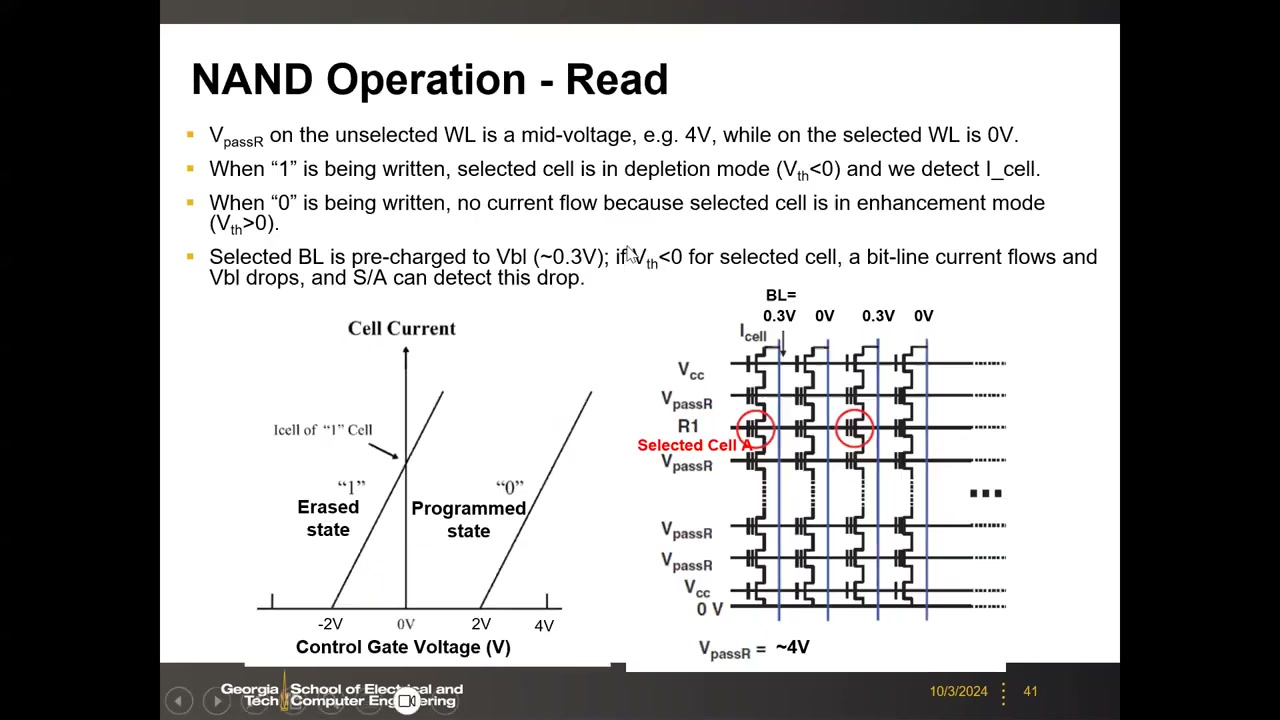
NAND 单元的 I–V 窗口:擦除态 Vt < 0(耗尽型,数据"1");编程态 Vt ≈ +2 V(增强型,数据"0"),约 4 V 存储窗口。读按页进行:选中字线加读电压 VR = 0 V(窗口中间),位线预充到约 0.3 V——"1"单元导通使位线放电,灵敏放大器检测压降。串内其余字线必须加 VpassR(≈4 V),且两端选择管导通。
高压外围系统 P2 01:02:10:NAND 依赖 20–30 V 高压而芯片 I/O 只有 2.5–3 V → 片上电荷泵(电容堆叠升压)产生约 30 V / 12 V,电压发生器产生 VPGM ≈ 20 V 与 VPASS ≈ 8 V;地址译码后经电平移位器(供电约 30 V,每条字线一个)把高压分配到选中/未选字线。高压外围电路占 NAND 芯片面积与设计复杂度的大头。
9. NAND vs NOR 全面对比与闪存转换层 FTL P2 01:03:50
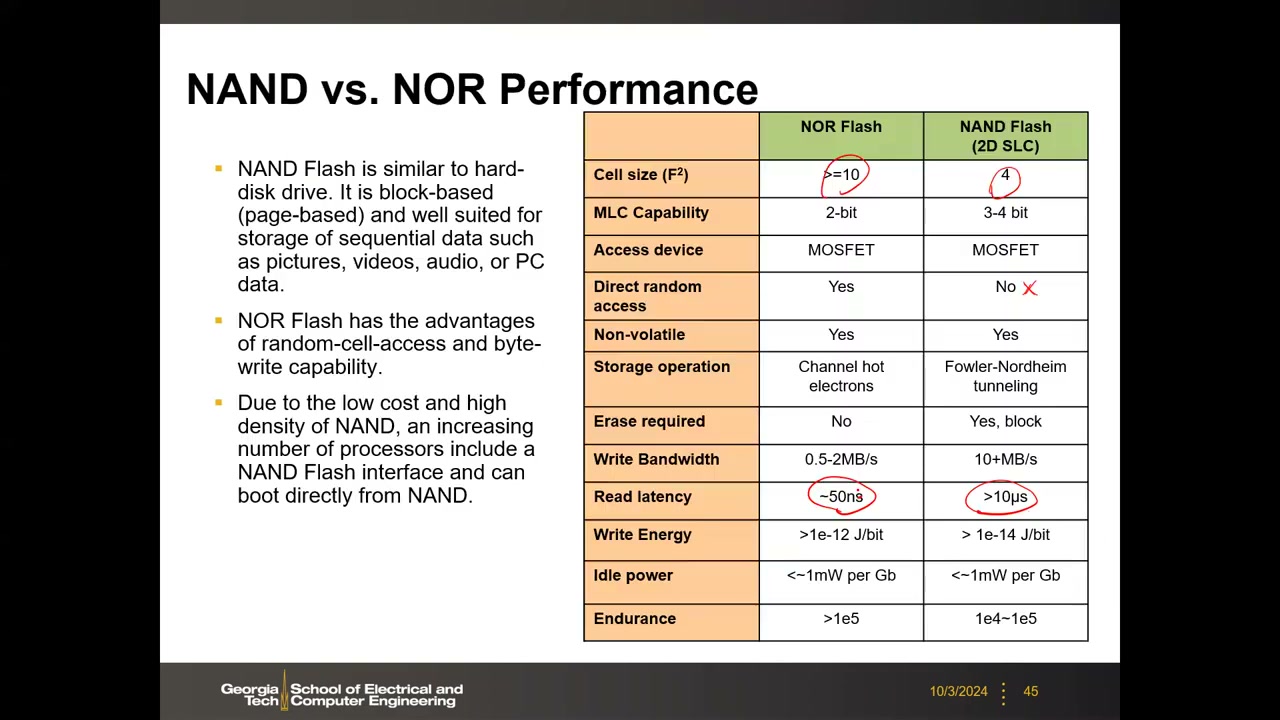
应用定位:NAND 密度高 → 存海量数据(SSD、手机、存储卡);NOR 读延迟低且随机访问 → 存关键代码(启动代码、固件)。如今 NAND 主导市场(单芯片可达 1 Tb),NOR 停留在单位数 Gb 量级。
| 指标 | NOR Flash | NAND Flash(2D SLC) |
|---|---|---|
| 单元尺寸 | ≥10F² | 4F² |
| MLC 能力 | 2-bit | 3–4 bit |
| 直接随机访问 | 是 | 否 |
| 编程机制 | 沟道热电子 CHE | FN 隧穿 |
| 需要先擦除 | 否 | 是(按块) |
| 写带宽 | 0.5–2 MB/s | 10+ MB/s |
| 读延迟 | ~50 ns | >10 µs |
| 写能耗 | >1e-12 J/bit | >1e-14 J/bit |
| 耐久性 | >1e5 | 1e4–1e5 |
机理解释:NOR 编程电流 ∝ 沟道电流,仅约 1/100,000 的电子进浮栅;NAND 编程电流 ∝ 单元位移电流(~1 pA@90 nm),效率 100%。读方面 NOR 单元直连位线、寄生电阻小 → 初始随机读快;NAND 电流要串过 32–64 个单元、串联电阻大 → 首次访问慢,但整页并行使带宽反而更高——"密度+带宽 vs 随机访问延迟"是两者的本质权衡。
闪存转换层 FTL P2 01:09:25:NAND 按页读写、按块擦除且不可原地覆写,系统必须用 FTL 管理逻辑地址→物理地址映射、磨损均衡(wear leveling)、垃圾回收(garbage collection)。物理层有一个只能顺序前进的写指针:更新数据时在写指针处写新页、更新映射表,旧页变为无效(invalid/garbage);当某块无效页比例足够高时触发垃圾回收——先把残余有效页搬到写指针处,再整块擦除(Erase count +1,用于磨损均衡)。块信息表字段:Erased、Erase count、Valid Page Count、Sequence Number、Bad Block Indicator。FTL 是 SSD 工作原理的核心。

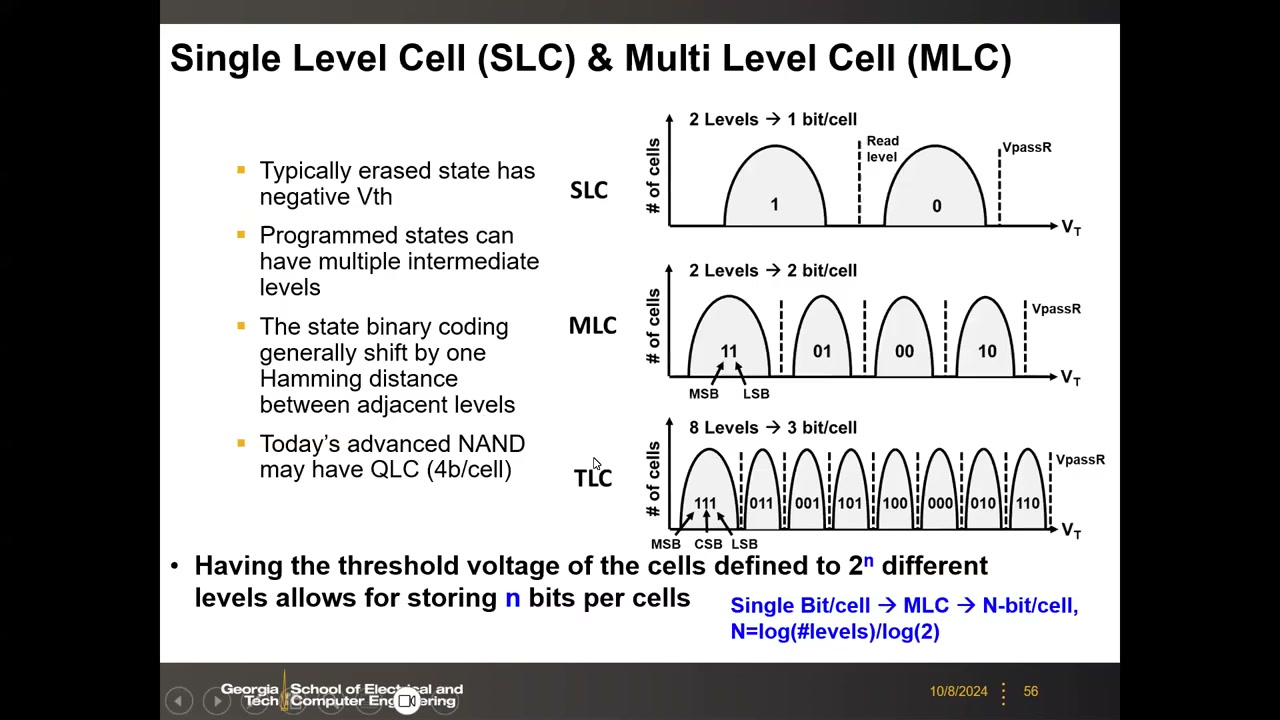
10. 多值存储:MLC/TLC/QLC 与 ISPP 编程 P3 00:00:36
在同一浮栅管中存多于 1 bit:注入不同数量的电子精细调制 VTH,在擦除态(约 −2 V)与最高编程态之间插入中间电平。由于器件间与循环间变差,每个电平实际是统计分布,只要相邻分布尾部有间隙即可区分。n bit/cell 需要 2ⁿ 个电平(N = log(#levels)/log 2):2 bit = MLC、3 bit = TLC、4 bit = QLC(已量产)、5 bit = PLC(研究中)、6 bit = HLC(77 K 低温演示)。NAND 记忆窗口典型仅约 8 V,TLC 的 8 个电平间距只剩约 1 V,而单个分布展宽就有几百 mV。读出用参考电流多次比较(二叉树搜索),MLC 需 3 个参考电流。
ISPP 增量步进脉冲编程 P3 00:16:14:每打一个编程脉冲后读回验证(program & verify),未达标则继续且脉冲幅度逐步递增(约 15 V 起按 ΔVpgm 步进到 19 V),避免过编程。对比:ISPP 只需 2–6 个循环、SLC 约 300 µs/页、分布最紧;恒压 18 V 分布展宽 >1.5 V 不可接受;恒压 16.5 V 分布紧但需 11–37 个循环太慢。ISPP 是编程速度与 VT 分布的最佳折中,是当今 NAND 的标准编程方法。
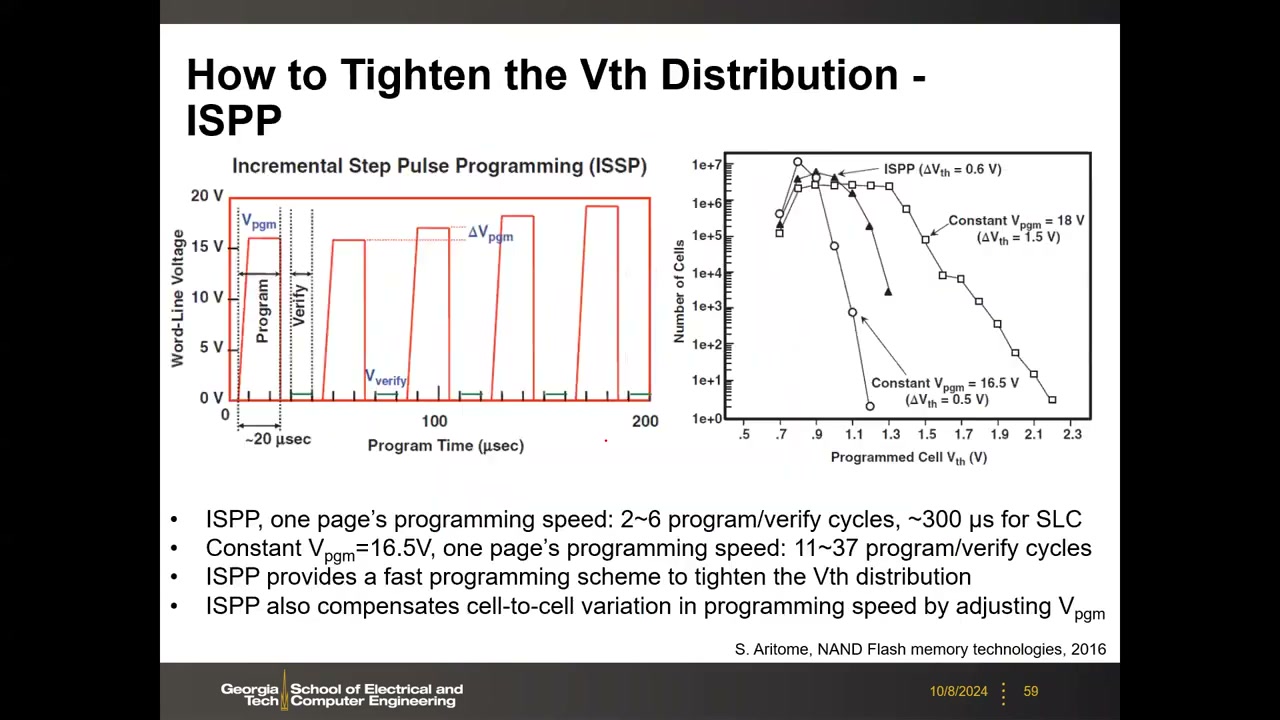
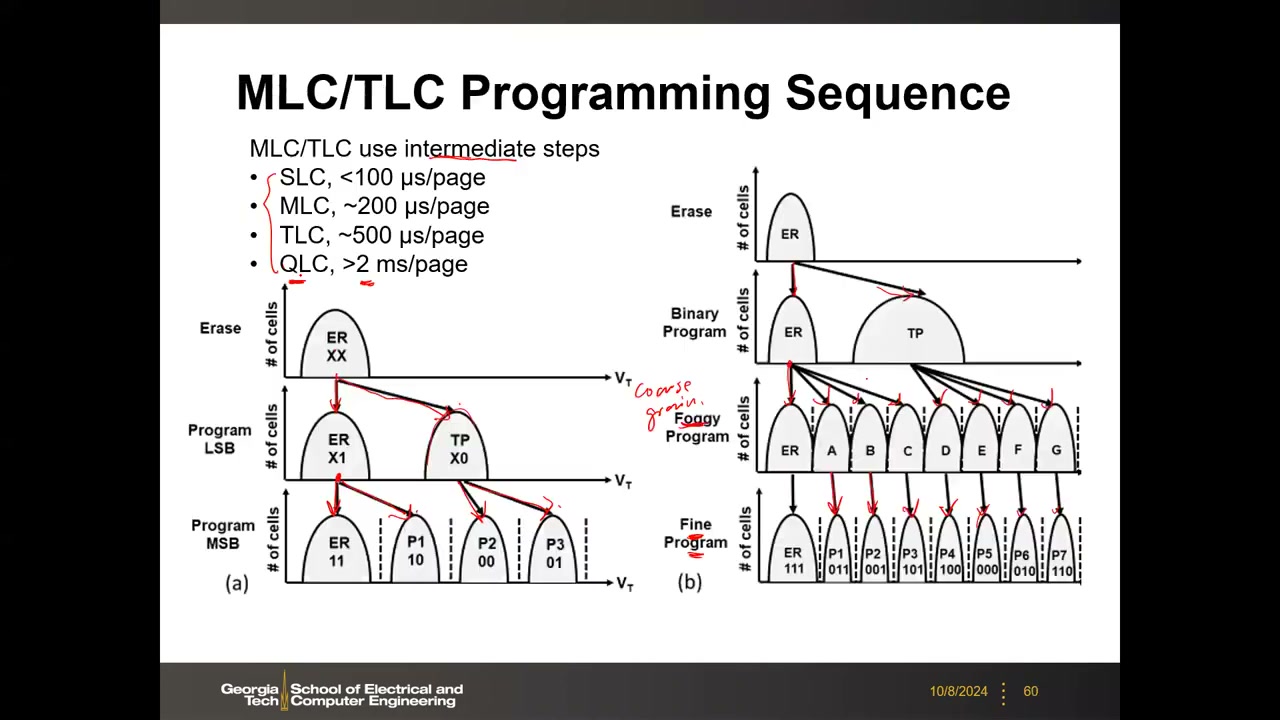
MLC/TLC 编程序列与速度代价 P3 00:20:37:MLC 两步(先 LSB 分裂出中间态,再 MSB 细分 4 态);TLC 用 foggy-fine(粗调–细调):二分 → foggy 粗分 8 态(少 verify)→ fine 小步微调。单页编程速度:SLC <100 µs、MLC ~200 µs、TLC ~500 µs、QLC >2 ms——每单元位数越多,verify 越多写越慢。工业插曲:Samsung Z-NAND(SLC 高速产品线,编程 1–3 µs)逼近 Intel Optane(3D XPoint)的性能定位,是 Optane 失败的原因之一——成熟 NAND 的定制化很容易"杀死"新兴技术。
11. 可靠性:耐久、保持与干扰 P3 00:26:28
可靠性是非易失存储器的核心议题,三大定义(同样适用于后续 RRAM/PCM):Endurance(耐久)——记忆窗口塌缩前能承受的 P/E 循环次数;Retention(保持)——浮栅电荷维持记忆窗口的时间,尤其高温下(产品等级:商用 85°C / 工业 ~125°C / 车规 ~150°C);Program/Read Disturb(干扰)——操作选中单元时邻近单元 VTH 漂移。
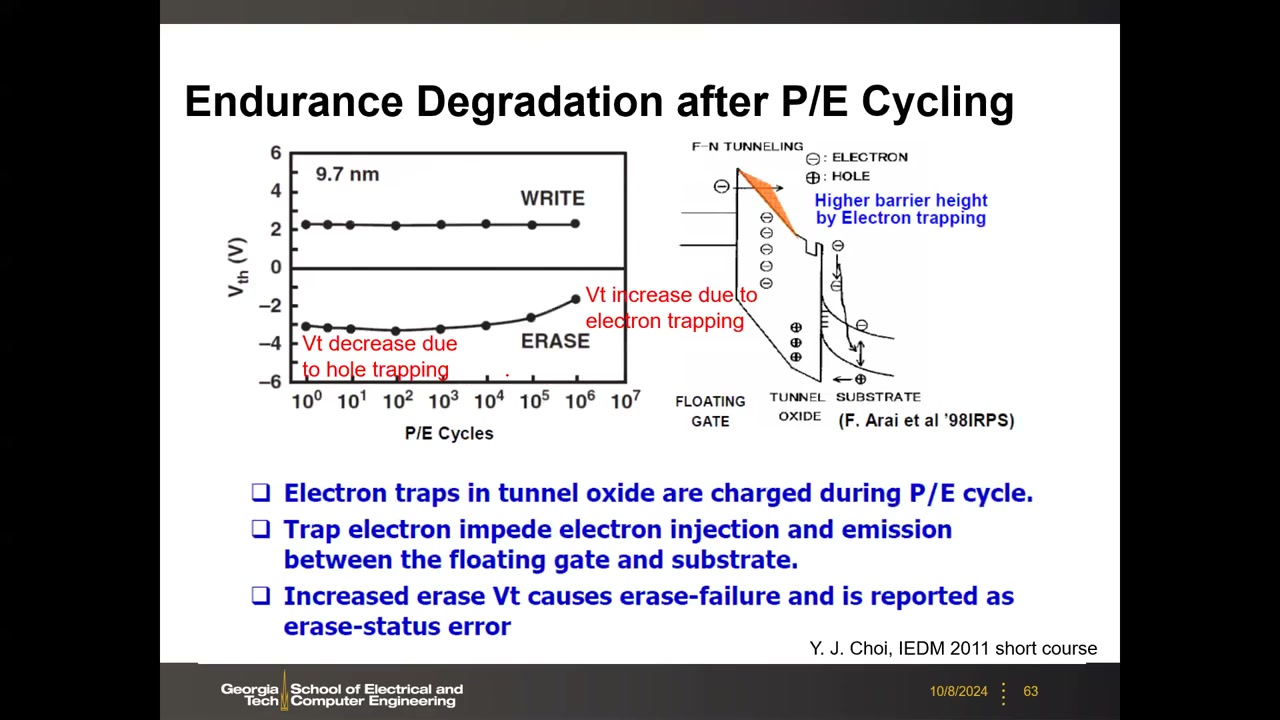
耐久退化 P3 00:30:11:P/E 循环中部分电子被陷在隧穿氧化层/界面陷阱,擦除无法完全移除 → 擦除态 VTH 随循环数(10⁰–10⁷)逐渐升高、记忆窗口收窄,对电平间隙小的多值单元更致命,最终成硬错误。测量方法学(实用建议):不可能每循环读一次(模式切换每次约 1 s),应连续打脉冲后按对数刻度取点(10, 20, 50, 100, 200, 500, 1000……),这是文献标准画法。
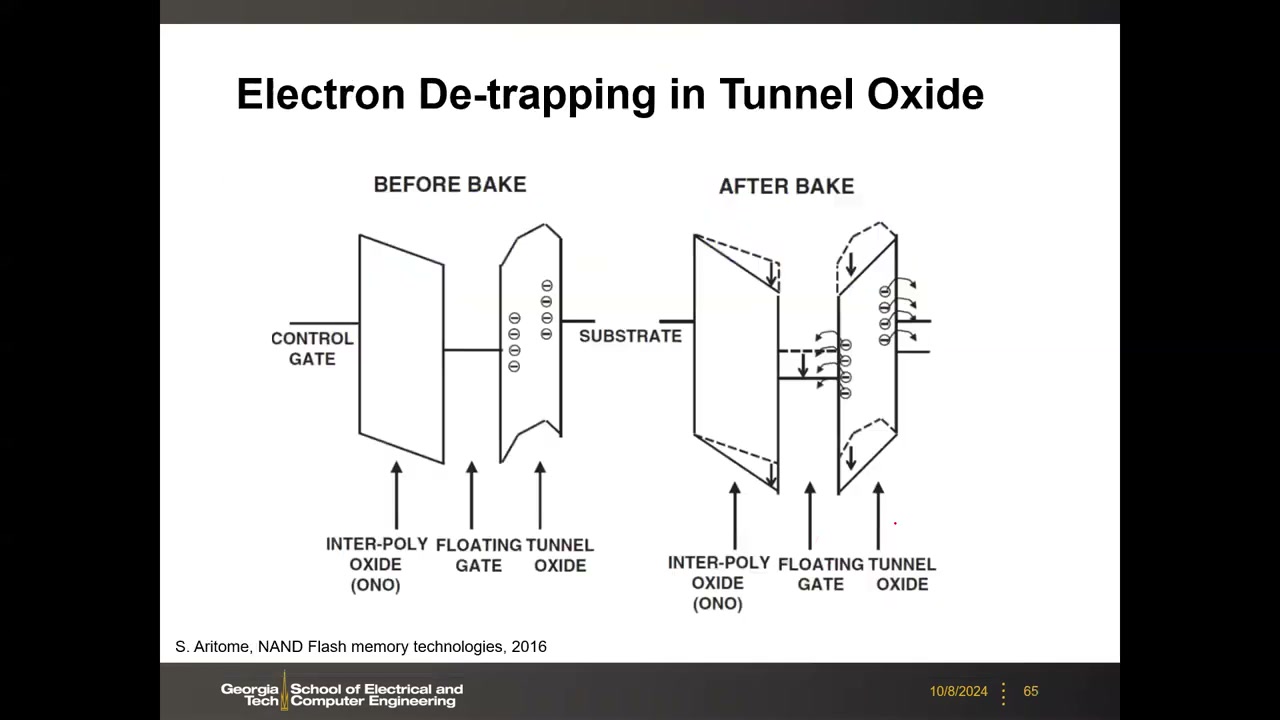
保持失效机制 P3 00:35:31:保持与循环耦合——循环后的保持更差。本征损失:高温下陷阱电子去陷阱(de-trapping)与浮栅电子热发射越过势垒逃逸,使各分布中位值整体左移;外在损失:SILC(应力诱发漏电流)——循环损伤产生氧化层陷阱,电子经陷阱辅助隧穿("垫脚石"把一步隧穿变两步)泄漏,尾部随电场极性双向延展。
温度加速测试与 Arrhenius 外推 P3 00:41:04:在 200/250/300°C 烘烤监测 VTH 衰减,按失效判据记录各温度 time-to-failure;热激活过程服从 exp(−EA/kT),画 log(失效时间) vs 1/kT 直线,斜率即激活能 EA(本例 0.66 eV),外推 10 年寿命:新鲜器件可在约 140–150°C 保 10 年,10⁶ 次循环后退化到约 114–115°C——"retention degrades post-cycling"。这是工业界标准寿命评估方法。
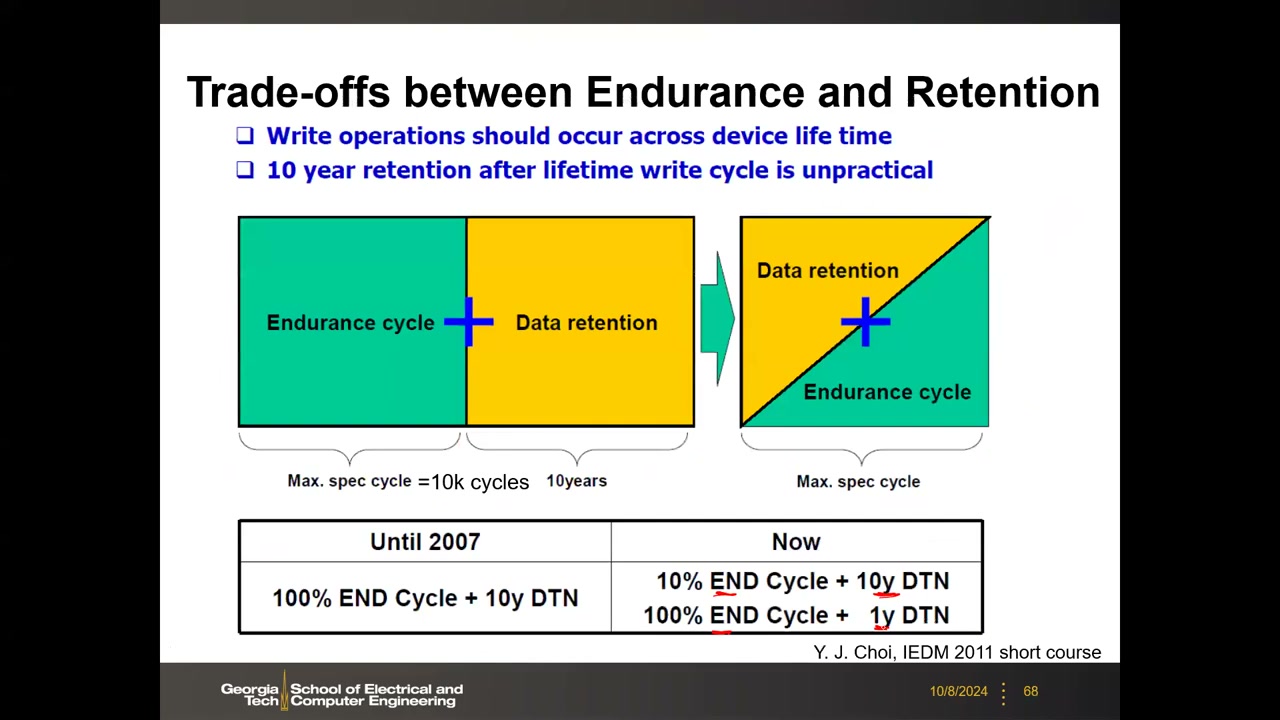
耐久–保持权衡与产品指标 P3 00:48:15:2007 年前规格为"100% 耐久循环(~10k 次)+ 10 年保持";现在是"10% 循环 + 10 年保持,或 100% 循环 + 1 年保持"的滑动分配。典型数字:SLC 可达 10⁵–10⁶ 次、保持 10 年@85°C;MLC/TLC ≤10⁴ 次;QLC <1000 次,TLC/QLC 保持约 3 年@85°C。大容量靠磨损均衡弥补低耐久。
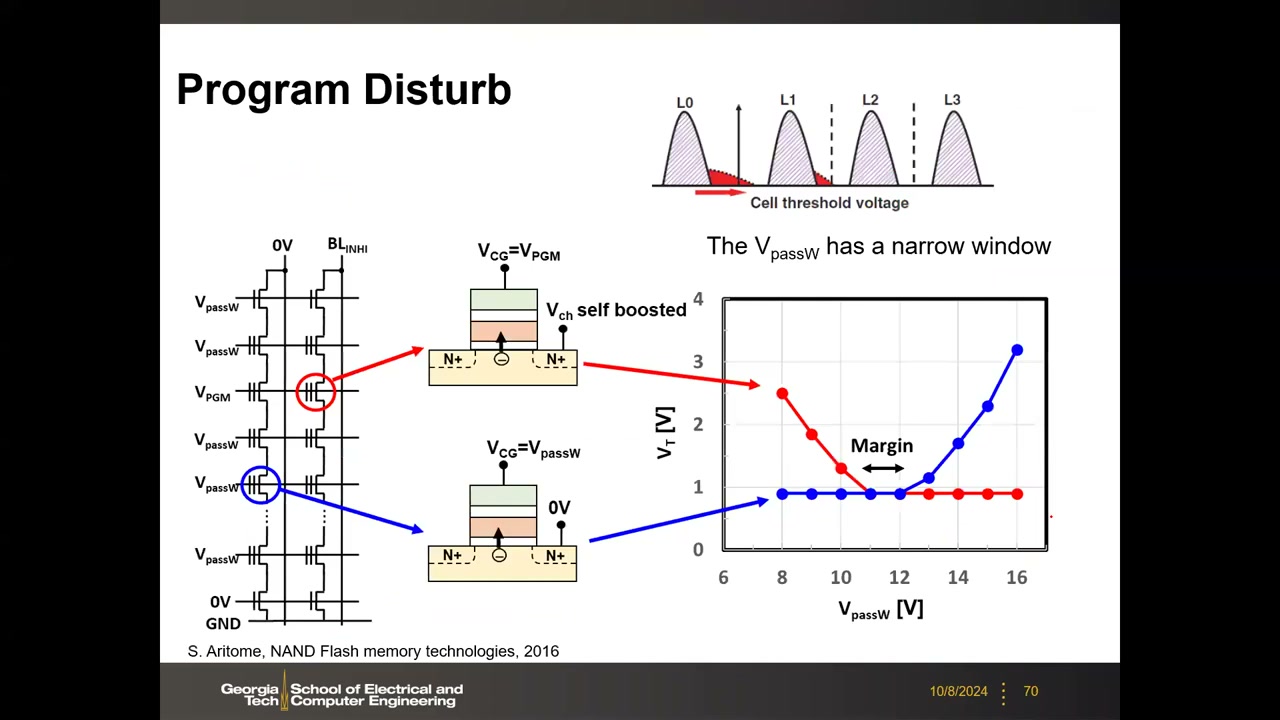
Program Disturb 与 VpassW 窗口 P3 00:51:56:两类半选单元(同字线者承受 VPGM、同位线者承受 VpassW)的 VTH 都可能上移;擦除态(L0)受扰最重(VTH 低、有效电场最大)。VpassW 只有窄工作窗口:太低(<10 V)自举不足、被抑制单元误编程;太高(>12 V)pass 单元自身被编程——VPGM≈20 V 时取约 10 V。
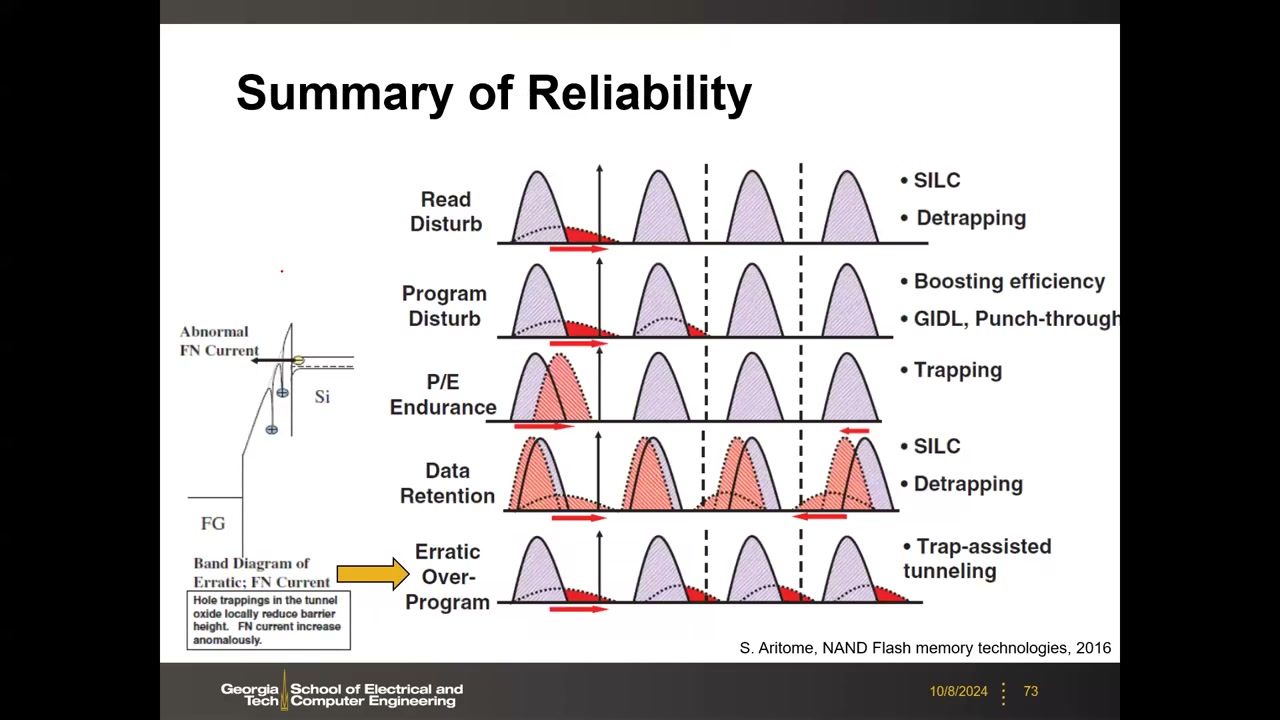
Read Disturb P3 00:57:31:读时未选单元加 VpassR(约 6 V),长期反复读仍会缓慢注入电子使 VTH 上移(可被下次擦除恢复,非永久);P/E 循环后显著加剧(陷阱增多、SILC 增强):无预循环需 ~10⁷–10⁸ 次读才达一定失效率,10K 次预循环后 ~10⁵ 次读即达 ~10⁻⁶ 失效率。1e-6 错误率 × Gb 级容量 → 错误绝对数可观,必须用 ECC 保护数据。可靠性总结图 P3 01:01:05:五类机制(Read/Program Disturb、P/E Endurance、Retention、Erratic Over-Program——氧化层空穴陷阱局部压低势垒导致编程过冲)对 VT 分布的漂移方向各不相同,教授强调此图对理解 NAND 可靠性非常重要。
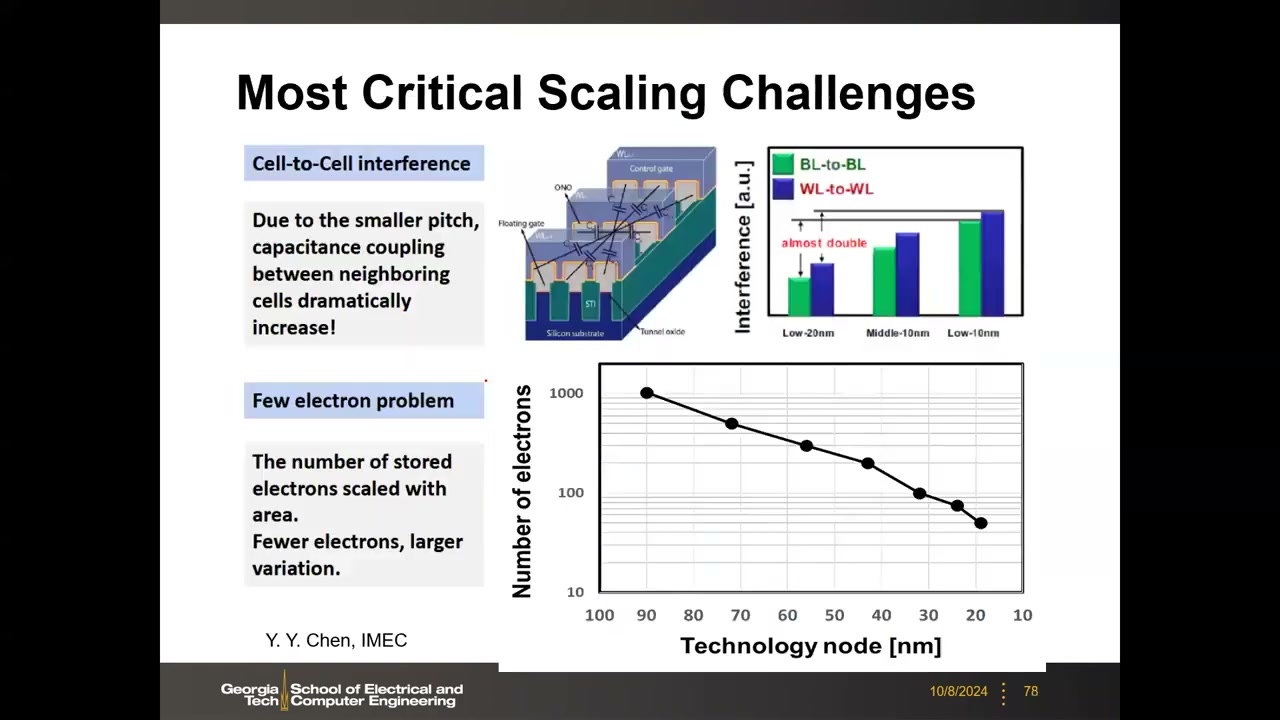
12. 2D NAND 微缩极限:单元间干扰与少电子问题 P3 01:03:50
按最小半节距看,2D NAND 微缩曾领先 DRAM 和逻辑——是工业界造过的最小晶体管,约 2013–2015 年进入 sub-20 nm、接近 10 nm;有效单元面积 20 多年缩小约 1/3000(1.5 年/代),关键工艺包括自对准 STI(SA-STI)、双重图形化、空气隙。最后一代 2D NAND 有效单元约 10×10–12×12 nm²,单 die 约 128 Gb。此后无法继续微缩,约 2014–2016 年转向 3D NAND(XY 平面尺寸反而放松,靠垂直堆叠提密度:24 → 32 → 64 → 128 → 如今约 300 层)。止步的两大根本原因 P3 01:08:43:
(1) 单元间干扰(FG-FG 耦合) P4 00:00:03:相邻浮栅寄生电容随间距缩到 10–12 nm 急剧增大(BL-BL、WL-WL、对角三类相加,sub-20 nm 总干扰可超所加电压的 20%);编程顺序中先编的单元被后编的邻元耦合干扰,VT 分布展宽、MLC 裕量收窄。对策:降低浮栅高度(但 αCG 下降、编程电压被迫从 20 V 升到约 30 V,最终走向平面 FG + 高 k IPD)、气隙(空气 ε≈1,最低介电常数,已用于 sub-20 nm 产品)。
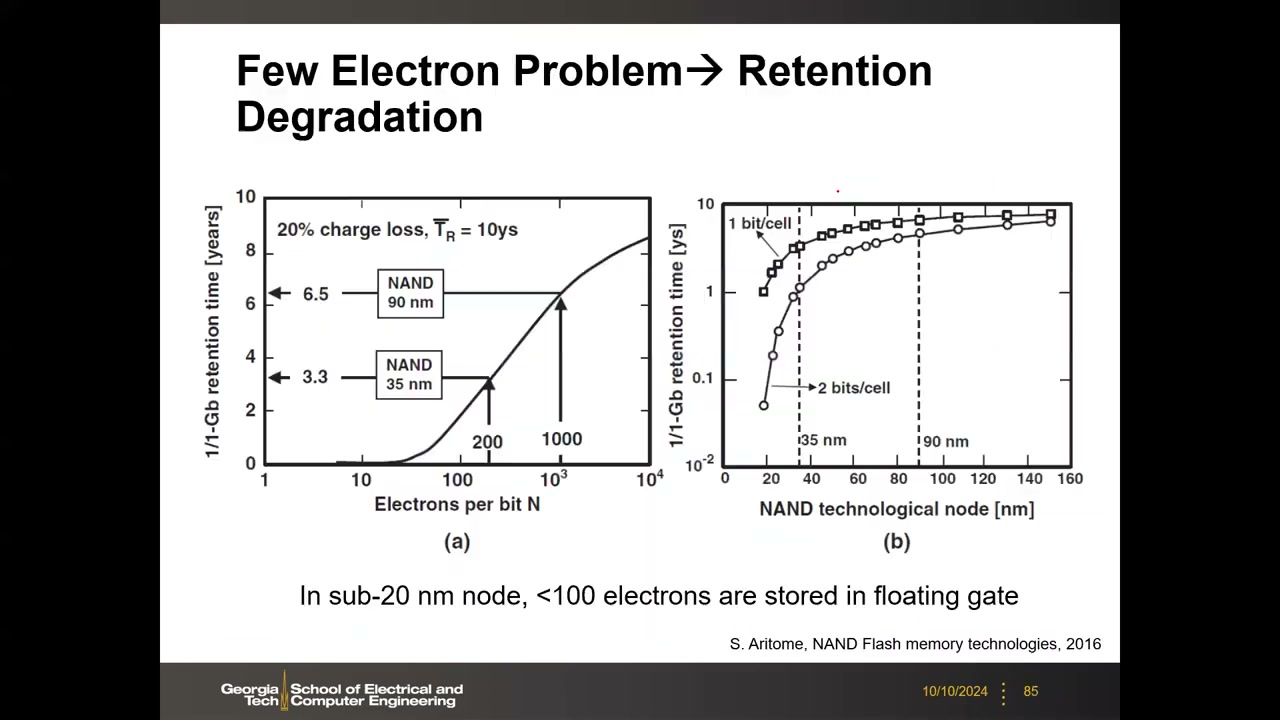
(2) 少电子问题 P4 00:10:08:由 ΔVth = ΔQ/CIPD,电子数随面积缩小——90 nm 约 1000 个电子(保持约 6.5 年)、35 nm 约 200 个(约 3.3 年)、sub-20 nm 仅约 20–40 个。另有随机电报噪声 RTN:界面陷阱随机俘获/释放电子造成 Vth 时间跳变,尺寸越小幅度越大(可达数百 mV),进一步压缩多电平裕度。
13. 电荷俘获单元:SONOS 与 CTF P4 00:13:26
电荷俘获(Charge-Trap)晶体管的操作原理与浮栅相同,关键差异是把存储层从导电的多晶硅换成绝缘的氮化硅(Si₃N₄):栅叠层为 poly-Si/Oxide/Nitride/Oxide/Si,即 SONOS。多晶硅 FG 中电子可动——一条漏电路径会让所有电子逐个流失;氮化硅中电子被各自独立的局域陷阱束缚——单点漏电只丢失附近少量电荷。SONOS 的动机:低编程电压(<10 V,典型 5–7 V)、更好的耐久/保持、对单缺陷电荷损失免疫。能带数值:SiO₂ 电子势垒 3.1 eV / 价带侧 4.75 eV;Si₃N₄ 导带阶 1.05 eV / 价带阶 2.85 eV——氮化物势垒低且陷阱能级深。
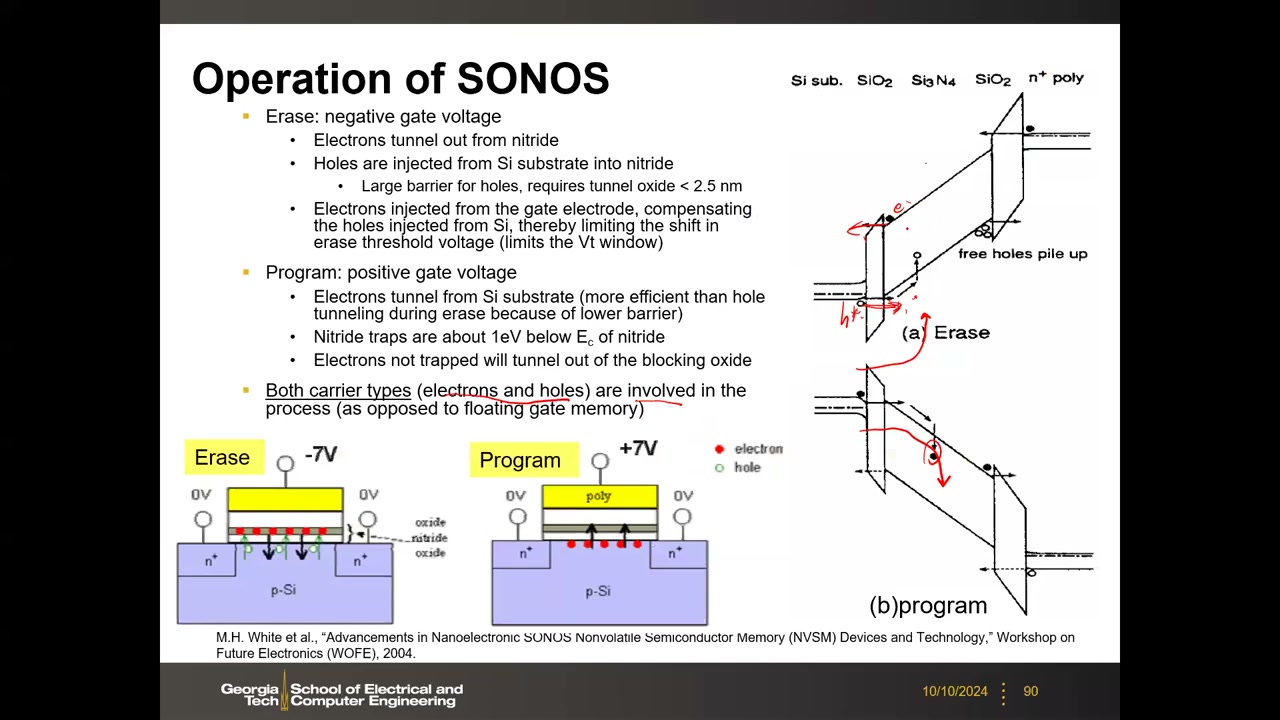
操作与空穴的作用 P4 00:17:42:编程加约 +7 V,电子 FN 隧穿注入氮化物陷阱;擦除加约 −7 V(或衬底 +7 V)时,电子隧穿出去的同时空穴从衬底注入氮化物、与电子复合等效移走电子,使擦除更高效(要求隧穿氧化层较薄)。即 SONOS 中电子与空穴两种载流子都参与(浮栅器件基本只有电子)——这一点对 3D NAND 至关重要:3D NAND 的擦除依赖空穴注入。器件演进 P4 00:20:56:MNOS(1970) → SNOS(1975) → SONOS(1985) → NROM(2000) → TANOS(2005,TaN 栅 + Al₂O₃ 高 k 阻挡层) → MONOS(2014,W 金属栅 + poly-Si 沟道)——3D 垂直 NAND 的主流单元技术。
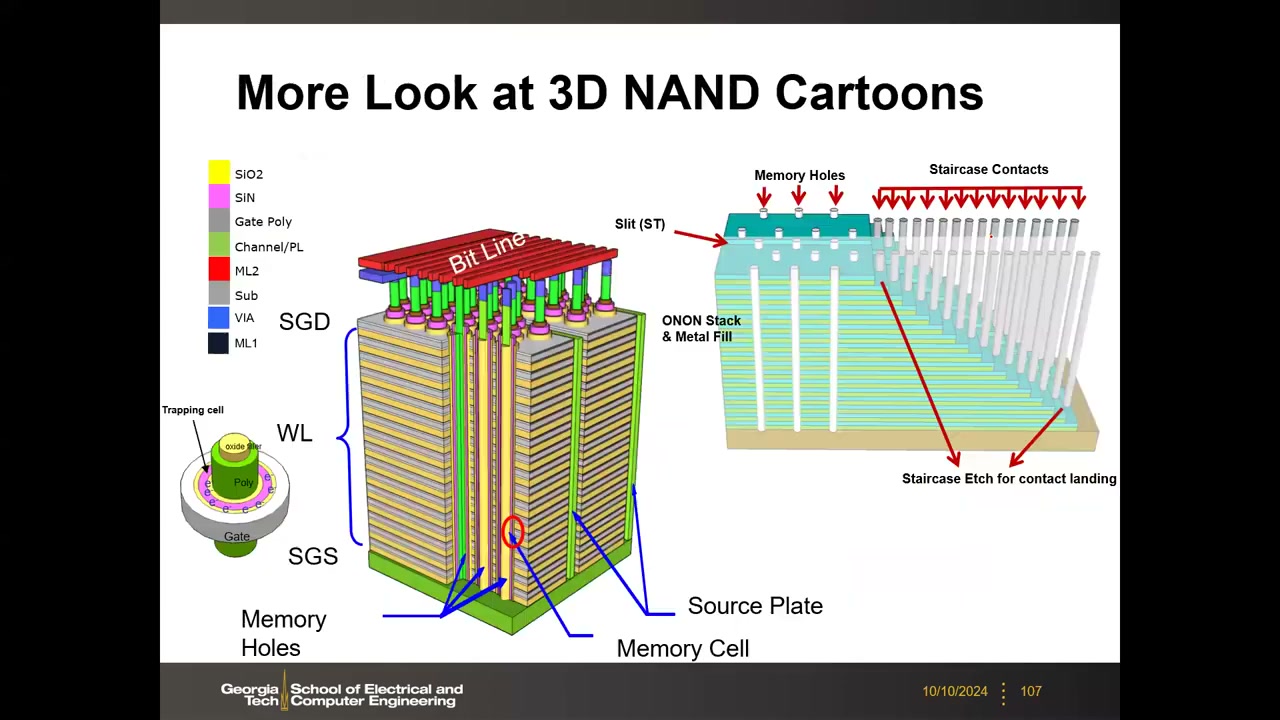
14. 3D NAND 架构与工艺:BiCS、共享光刻与替换栅 P4 00:22:00
R&D 早于商用近 7–10 年:Toshiba BiCS(VLSI 2007)是公认的 3D NAND 里程碑;2009 年 Toshiba P-BiCS(U 形串、源线上移用金属)与 Samsung TCAT(钨栅、体擦除)跟进;Samsung 于 ISSCC 2014 率先商用化。成本逻辑 P4 00:24:44:制造最贵的环节是光刻(约占成本 80%)。"简单堆叠"(重复 2D 工艺逐层做)不省光刻——1 层 10 步、3 层 30 步,不可取。
BiCS(Bit-Cost Scalable)架构 P4 00:34:28:环形栅串垂直站立——中心 poly-Si 沟道(3D 改用多晶硅 TFT 沟道,2D 是单晶硅),外包 O/N/O 电荷俘获层,再外是栅;字线是水平平面层。编程用常规 FN;擦除靠 GIDL 产生带带隧穿空穴注入俘获层。每一水平面共享一条字线,定位单元需 XYZ 三维译码:位线(X)+ 字线平面(Z)+ 上串选择管(Y,各串独立);直观理解:取 3D 网表的一个竖直切片,它与一条 2D NAND 完全相同——3D NAND 就是把 2D 立起来再并排许多片。
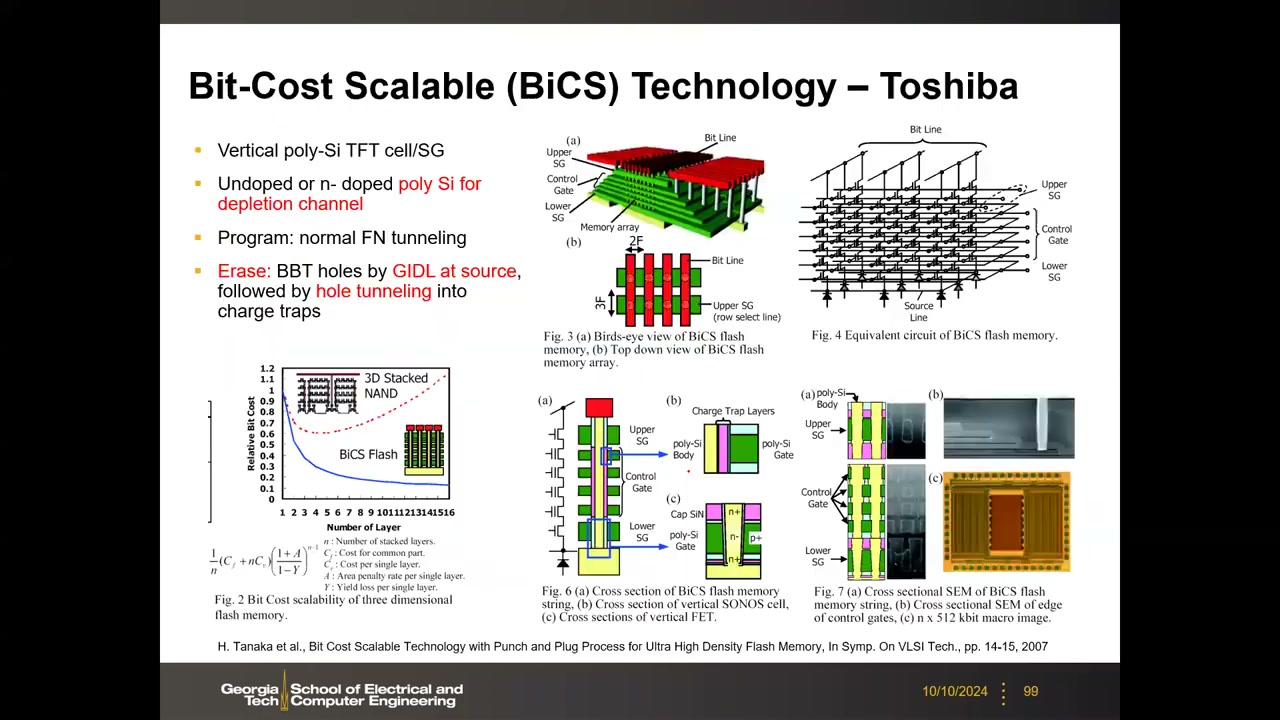
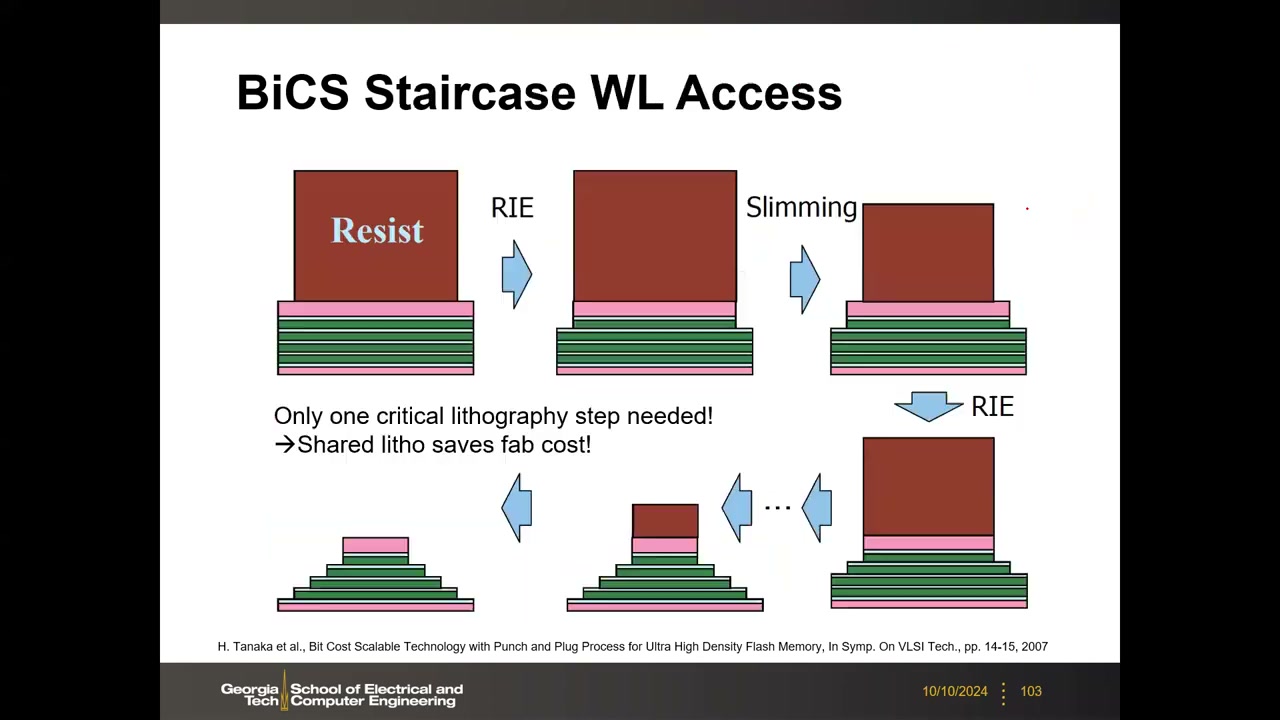
共享光刻与阶梯工艺 P4 00:42:24:先沉积多层 O/N 交替叠层,再用一次关键光刻刻穿所有层打出 memory hole,一次成形所有串。字线阶梯(staircase)也只需一次光刻:光刻胶修剪法——RIE 刻一层 → 化学法横向收缩光刻胶一圈 → 再刻一层,循环逐层暴露阶梯。代价:阶梯接触消耗大量外围面积(64 层要 64 个落点);制造瓶颈从光刻转移到多层沉积与高深宽比刻蚀。
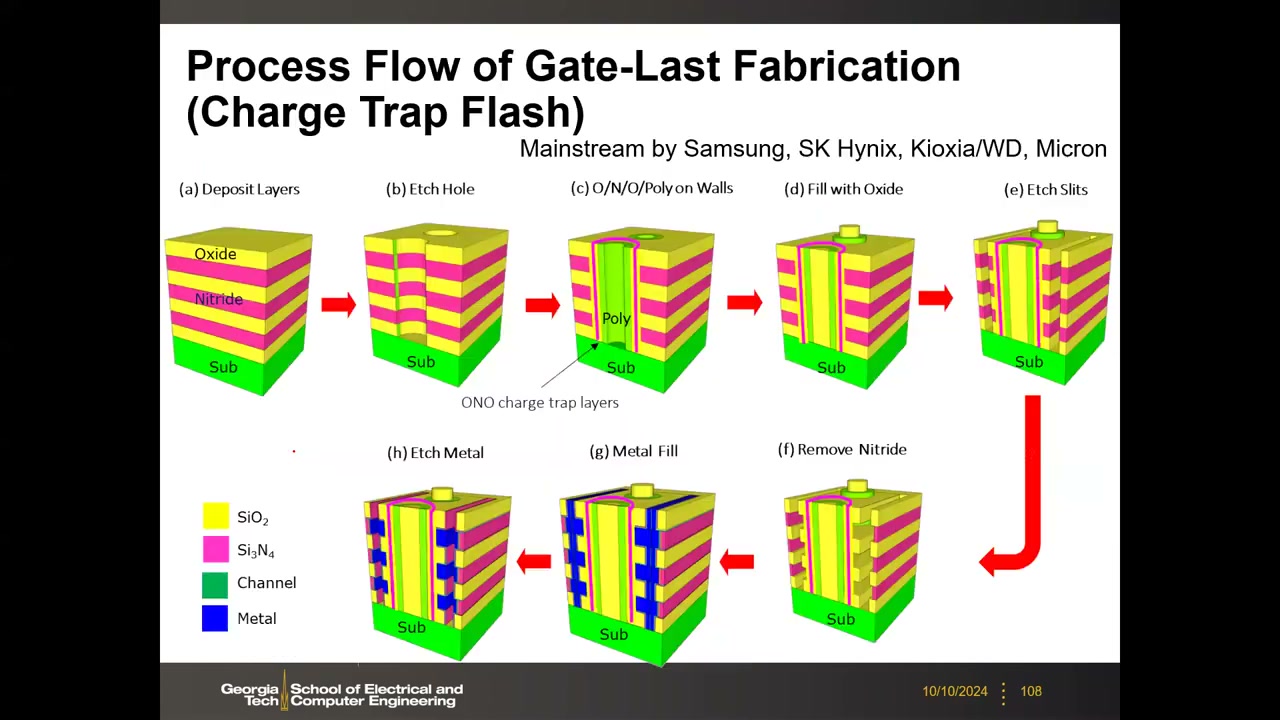
栅后(CTF)主流工艺流程 P4 00:50:44:(a) 交替沉积 Oxide/Nitride(ONON)→ (b) 一次光刻刻 memory hole → (c) 孔壁沉积 O/N/O 俘获层 + poly-Si 沟道 → (d) 孔芯填氧化物(core-shell:SiO₂ 芯 + poly-Si 沟道壳)→ (e) 刻 slit 分隔字线 → (f) 经 slit 各向同性去除牺牲氮化物(替换栅)→ (g) 钨回填 → (h) 刻除多余金属。Intel 浮栅路线则为 gate-first(CG recess → IPD → FG 沉积隔离)。
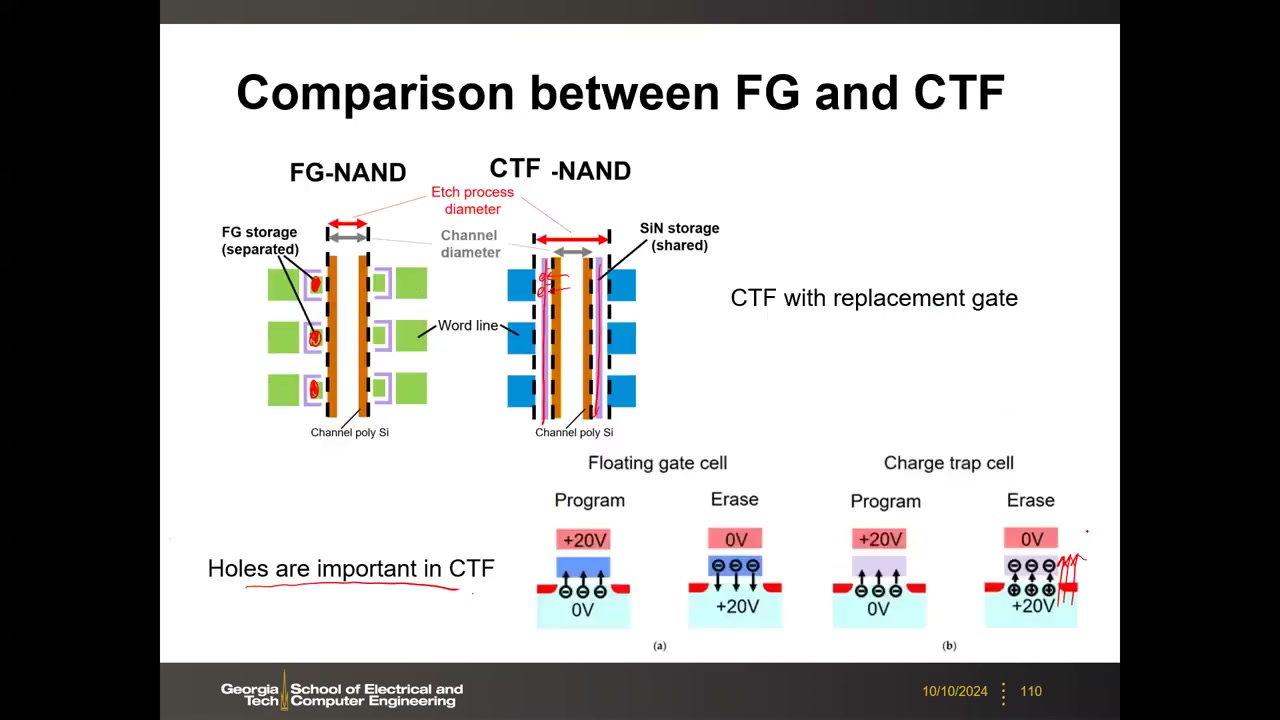
FG vs CTF 关键差异 P4 00:54:17:(1) FG 存储节点必须逐单元分隔(电子可动);CTF 的 SiN 层可整串连续共享(电荷局域不动)。(2) CTF 叠层远薄于高大的导电 FG,孔径可更小。(3) 空穴在 CTF 中重要:擦除(栅 0 V、沟道 +20 V)时 CTF 靠空穴注入帮助擦除。
15. 3D NAND 操作与首代 V-NAND P4 00:55:56
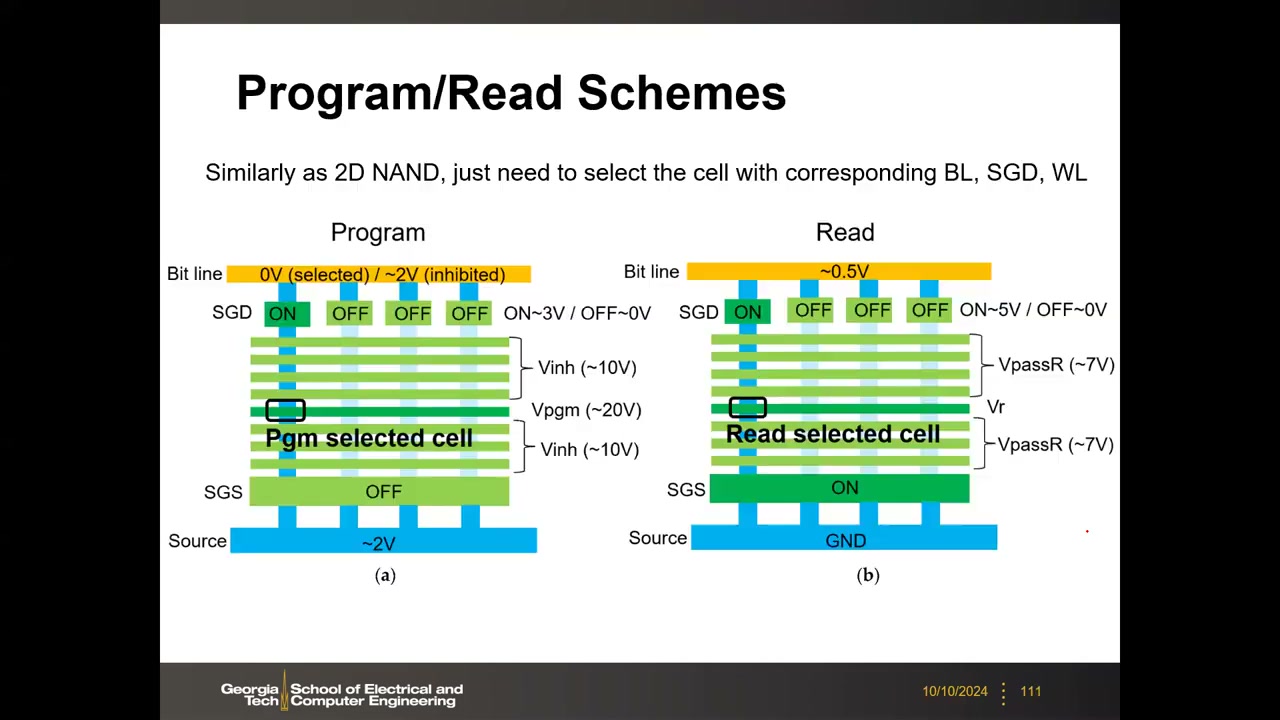
编程/读取沿用 2D 方案(取一个 slice 即 2D NAND):编程——选中 BL 加 0 V(禁止位线约 2 V,自举抑制),SGD 选中串导通(约 3 V)其余关断,选中 WL 加 Vpgm ≈ 20 V,同串其它 WL 加 Vinh ≈ 10 V;读取——BL ≈ 0.5 V,选中 WL 加 Vr,其余 WL 加 VpassR ≈ 7 V 全开。关键是用上串选择管(SGD/SSL)选中具体 slice。
两种擦除机制 P4 00:57:28:擦除需要供给空穴。(1) 体擦除(Body Erase):沟道仍连接 p 阱衬底时,衬底加 20 V、WL 0 V、选择管栅约 15 V,空穴由衬底直接供给(早期 TCAT)。(2) GIDL 擦除:CMOS under Array 结构中阵列坐在介质上、沟道无体接触——BL/SL 加 20 V、选择管栅约 15 V,在选择管边缘强能带弯曲下由 GIDL(带带隧穿)产生电子–空穴对供给空穴。GIDL 擦除因 CuA 普及而成为主流。

Samsung 首代商用 V-NAND 128 Gb(ISSCC 2014) P4 00:59:53:24 层 WL(串 = 24 WL + 2 dummy + 2 选择管),MLC 2 bit/cell,133 mm² → 0.96 Gb/mm²;环栅 + CTF + 大马士革金属栅。逆向工程 TEM 可逐层辨认 W 字线/TiN/Al₂O₃(高 k 阻挡)/SiO/SiN(俘获层)/SiO/poly-Si 沟道/SiO₂ 芯——"没有秘密"。3D 单元的定量优势 P4 01:04:11(作业相关):环栅单元有效栅面积 = 侧面积 2πrH ≫ F²(r≈60 nm、H≈50 nm,远大于 2D 末代的 15×15 nm²)——可存远更多电子,解决少电子问题;单元间距由层厚决定(数十至上百 nm)且 FG 换成 CTF 薄层——实测自然 Vth 分布收窄 33%、单元耦合减小 84%。代价:单串占地大,必须堆足够多层才能在面积密度上反超。芯片级对比 1x nm 平面 MLC:密度 ×1.64、IO 533→667 Mbps;系统级 512 GB SSD:顺序写 +22%、随机写 +20%、平均功耗 −27%。

16. 历代芯片演进与展望:层数竞赛、CuA 与 Xtacking P4 01:10:33
Samsung 自 2014 年起每年在 ISSCC 发布新一代(2014–2017 几乎无竞争者),几乎每代密度翻倍:
| 世代 | 发布 | 层数 | 容量 / bit数 | die 面积 | 密度(Gb/mm²) | 备注 |
|---|---|---|---|---|---|---|
| 第 1 代 | ISSCC 2014 | 24 层 | 128 Gb · MLC | 133 mm² | 0.96 | 世界首颗商用 3D V-NAND |
| 第 2 代 | ISSCC 2015 | 32 层 | 128 Gb · TLC | 68.9 mm² | 1.86 | 密度 +93%,超当时 HDD;tPROG 700 µs |
| 第 3 代 | ISSCC 2016 | 48 层 | 256 Gb · TLC | 97.6 mm² | 2.62 | tPROG 660 µs |
| 第 4 代 | ISSCC 2017 | 64 层 | 512 Gb · TLC | 128.5 mm² | 3.98 | VccQ 1.8/1.2 V |
层数竞赛与 two-deck P4 01:12:09:2017 年后各家全面跟进,2019 年普遍达 96–128 层(叠层物理高度数 µm),2024 年约 300 层。3D NAND 是刻蚀驱动的工艺:刻蚀孔侧壁有倾角(实测约 87.6–89°,非 90°)时顶部单元占更大面积,层数越多有效单元尺寸不再下降——因此业界转向 two-deck(双甲板):柱光刻/刻蚀拆成两段(如 96 层 = 2×48),Micron 最早引入,Samsung 最后(约 2021–2022)。
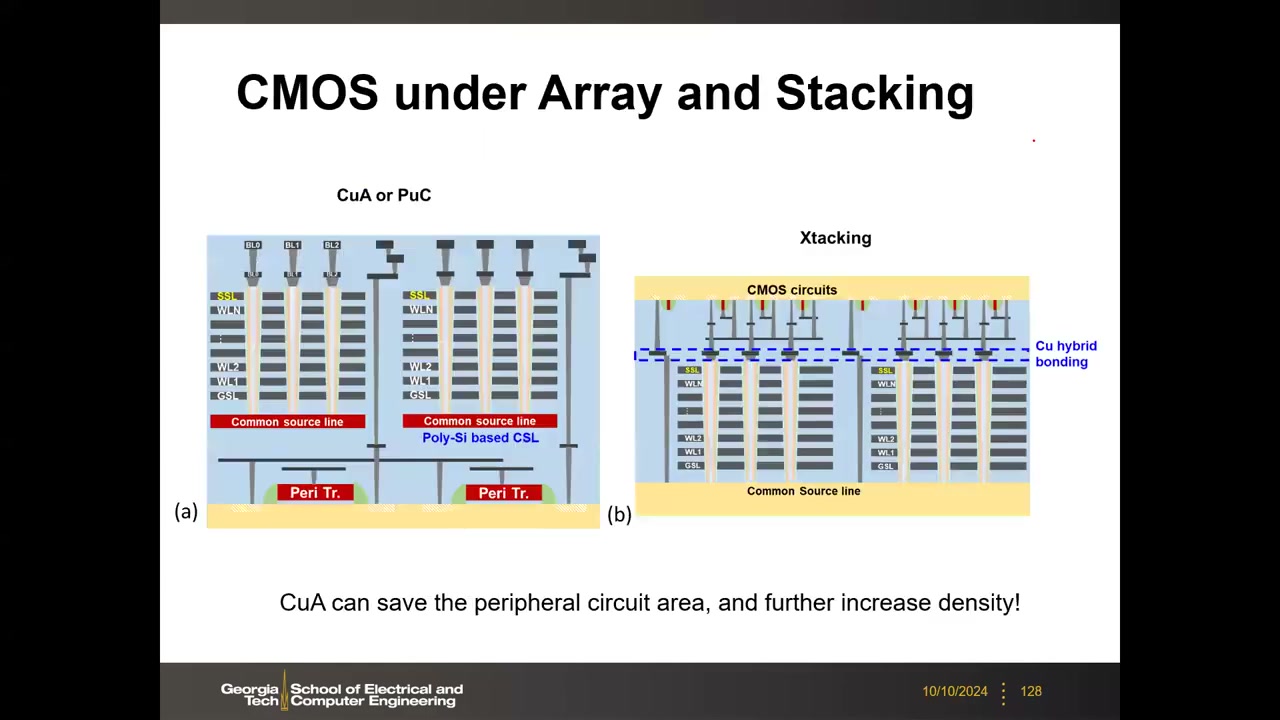
CuA 与 Xtacking P4 01:14:17:(1) CMOS under Array(CuA/PuC)——外围电路做在单晶硅衬底里,3D 阵列(poly-Si 沟道无需单晶衬底)整体叠其上方,省外围面积提密度(这也使 GIDL 擦除成为必需);(2) Xtacking(YMTC 长江存储)——外围 CMOS 晶圆与 NAND 阵列晶圆分别制造后 Cu 混合键合(hybrid bonding),预计主要厂商未来也会跟进键合方案。
最新芯片汇总(均 1 Tb,均用 CuA/PuC) P4 01:15:01——对比第一代约 1 Gb/mm²,10 年间密度提升超过 20 倍:
| 类型 | 厂商 / 发布 | 层数 | die 面积 | 密度(Gb/mm²) | 编程吞吐 |
|---|---|---|---|---|---|
| TLC(3 bit/cell) | Kioxia/WDC · ISSCC 2021 | >170 | 98 mm² | 10.4 | 160 MB/s |
| Samsung · ISSCC 2022 | >220 | 88.6 mm² | 11.55 | 164 MB/s | |
| Kioxia/WDC · VLSI 2023 | >210 | <60.2 mm² | >17 | 205 MB/s(8 平面) | |
| SK Hynix · ISSCC 2023 | >300 | <51.2 mm² | >20 | 194 MB/s | |
| Micron · ISSCC 2024 | 2YY 层 | <51.2 mm² | >20 | 205 MB/s(6 平面) | |
| QLC(4 bit/cell) | Samsung · ISSCC 2024 | 280 | 35.9 mm² | 28.5 | tPROG >1 ms,仅 30–60 MB/s |
TLC 编程延迟典型数百 µs(tPROG 312–468 µs)、读延迟 32–50 µs;QLC 层数更少即达同容量(4 bit/cell),但 4 bit 校验更难——tPROG 超 1 ms(1561–2133 µs)、读延迟 65–90 µs。本讲总结 P4 01:17:13:NAND 在市场上压倒 NOR;2D NAND 微缩在约 14 nm 止步;MLC/TLC/QLC 持续推高容量但可靠性随之退化;3D NAND 已是主流,未来十年靠更多层数延续等效微缩;CuA 与 X-stacking 进一步提升集成密度。
本讲要点总结
- 浮栅存储器 1967 年由 Kahng & Sze 提出,1984 年 Toshiba 舛冈富士雄商业化为 Flash,1987 年发明 NAND;以浮栅中是否存有电子表示数据(有电子 = 编程态 "0",VT 升高)。
- 电容模型核心公式:阈值偏移 ΔVT = QFG/Ck(只与 IPD 电容有关);栅耦合比 αCG = Ck/Ct(实验值约 0.83,越大越好),漏耦合比 αD ≈ 0.12(越小越好)。
- 编程/擦除两大机理:FN 隧穿 JFN = αE²exp(−β/E)(三角势垒,ΦB=3.1 eV,效率近 100%,NAND 用)与沟道热电子 CHE(快但效率仅 10⁻⁶–10⁻⁸,NOR 用)。
- 隧穿氧化层(8–9 nm)需在保持(<10⁻¹⁶ A/cm²)与编程(>1 A/cm²)间提供 16 个数量级的电流非线性;先进节点一次编程仅注入约 100 个电子。
- NOR 阵列约 10F²、随机访问、CHE 编程,存代码;NAND 串联无接触孔,4F² 平面最小单元,FN 编程/擦除,存数据——读/编程按页(25 µs/220 µs),擦除按块(约 500 µs–5 ms)。
- NAND 编程抑制靠沟道自举:串选管关断使沟道浮空,先抬 VpassW 再加 VPGM,沟道被电容耦合抬到约 VpassW/2 ≈ 5 V;传输门规则 VS = min(VG−Vth, VD)。
- NAND 不可原地覆写,系统靠 FTL(地址映射、写指针、垃圾回收、磨损均衡)管理;高压(20–30 V)由片上电荷泵+电平移位器产生。
- 多值存储用 Gray 码(相邻电平 Hamming 距离 1)+ ISPP(增量步进脉冲 + program-verify)收紧 VT 分布;页编程速度 SLC <100 µs → QLC >2 ms,密度与速度互为代价。
- 可靠性三大问题:耐久(P/E 循环使氧化层俘获电子、擦除态 VTH 上升,SLC ~10⁵⁻⁶ 次 / TLC ≤10⁴ / QLC <10³);保持(去陷阱、热发射、SILC,用 Arrhenius 1/kT 图外推 10 年寿命,EA≈0.66 eV,T 必须用开尔文);编程/读取干扰(VpassW 只有约 10–12 V 的窄窗口,擦除态受扰最重,必须配 ECC)。
- 2D NAND 止步约 14 nm 的两大根因:FG-FG 单元间耦合干扰(sub-20 nm 总干扰超 20%)与少电子问题(仅 20–30 个电子,丢 1 个移约 500 mV)。
- 电荷俘获单元(SONOS→MONOS)用绝缘氮化硅局域陷阱替代导电浮栅,抗单点漏电、叠层薄;擦除依赖空穴注入——3D NAND 采用 CTF + gate-last(替换栅)成为绝对主流。
- 3D NAND(Toshiba BiCS 2007 首创)的成本关键是共享光刻:一次光刻打穿全部叠层成形 memory hole,阶梯用光刻胶修剪法一次光刻完成;瓶颈转移到多层沉积与高深宽比刻蚀(two-deck 应对)。
- 3D 环栅单元有效面积 2πrH ≫ F²,解决少电子问题;Vth 分布收窄 33%、单元耦合减小 84%;擦除由体擦除走向 GIDL 擦除(CuA 结构必需)。
- 密度演进:0.96(24 层,2014)→ 1.86 → 2.62 → 3.98(64 层,2017)→ >20 Gb/mm²(300+ 层 TLC,2023–24)→ 28.5 Gb/mm²(QLC,2024),十年超 20 倍;CuA/PuC 与 YMTC Xtacking(混合键合)进一步提升集成密度。
术语表
| 术语 | 中文 | 释义 |
|---|---|---|
| Flash | 闪存 | 基于浮栅/电荷俘获晶体管的非易失存储技术,名称由 Toshiba 舛冈富士雄提出。 |
| ROM / PROM / EPROM / EEPROM | 只读存储器及变体 | Flash 的技术前身:PROM 一次性编程、EPROM 用 UV 擦除、EEPROM 电擦除。 |
| Floating Gate (FG) | 浮栅 | 被介质完全包裹、无外部电极的多晶硅栅,存储电子的位置。 |
| Control Gate (CG) | 控制栅 | 浮栅上方的可外接电极,通过电容耦合控制浮栅电位。 |
| Tunnel Oxide | 隧穿氧化层 | 浮栅与沟道间的 SiO₂(约 8–9 nm),编程/擦除的隧穿通道。 |
| IPD / ONO | 多晶硅间介质 | 控制栅与浮栅间介质,典型为氧化物–氮化物–氧化物三明治,约 15 nm。 |
| ΔVT = QFG/Ck | 阈值电压偏移 | 编程态相对擦除态的 VT 增量,只取决于存储电荷与 IPD 电容。 |
| Gate Coupling Ratio (αCG) | 栅耦合比 | αCG = Ck/Ct,控制栅电压耦合到浮栅的比例(例中 0.83),越大越好。 |
| Drain Coupling Ratio (αD) | 漏耦合比 | 漏压耦合到浮栅的比例(例中 0.12),栅控器件希望其小。 |
| FN Tunneling | FN 隧穿 | 强场下三角势垒的量子隧穿,JFN = αE²exp(−β/E);NAND 编程/擦除机理,效率近 100%。 |
| Direct Tunneling | 直接隧穿 | 氧化层 <约 2 nm、梯形势垒时的隧穿;逻辑器件栅漏电来源,Flash 中避免。 |
| CHE | 沟道热电子注入 | 大漏流中少数高能"幸运电子"越过势垒注入浮栅;NOR 编程机理,效率仅 10⁻⁶–10⁻⁸。 |
| SSI / 1.5T Split-gate | 源端注入 / 分裂栅 | 控制栅与浮栅沿沟道分段、先横向加速再垂直注入的高效编程方式,用于嵌入式 eFlash。 |
| NOR / NAND array | NOR / NAND 阵列 | 浮栅管并联(随机访问,≥10F²)vs 串联成串(最高密度,4F²,串行访问)。 |
| NAND String / SSL / GSL | NAND 串与选择管 | 32–64 个串联浮栅管加串顶(接位线)/串底(接源线)两个常规选择管。 |
| Page / Block | 页 / 块 | 页 = 一条字线(2–16 kB),读/编程最小单位;块 = 64 页(约 1 MB),擦除最小单位。 |
| Half-selected cell | 半选中单元 | 与选中单元共享字线或位线的单元,编程/读取干扰的受害者。 |
| Pass gate condition | 传输门条件 | 浮空源端电位 VS = min(VG − Vth, VD)。 |
| Channel Self-Boost | 沟道自举 | 关断串选管使沟道浮空、靠字线电容耦合抬升沟道电位(≈VpassW/2)的标准编程抑制方案;变体有局部自举(≈VPGM/2)与非对称自举。 |
| VPGM / VpassW / VpassR | 编程 / 写通 / 读通电压 | 选中字线约 20 V;编程时未选字线约 9–10 V(窄窗口);读取时未选字线约 4–7 V,须高于编程态 Vt。 |
| Memory window | 存储/记忆窗口 | 擦除态与最高编程态 Vt 之差(SLC 约 4 V,多值总窗口约 8 V)。 |
| Charge pump / Level shifter | 电荷泵 / 电平移位器 | 片上升压(2.5 V → 20–30 V)与把译码信号转为字线高压驱动的外围电路。 |
| FTL | 闪存转换层 | 管理逻辑→物理地址映射、磨损均衡、垃圾回收的控制器层;含写指针与块信息表。 |
| Garbage collection / Wear leveling | 垃圾回收 / 磨损均衡 | 擦除前搬移有效页;基于擦除计数把写入均匀分摊到各块。 |
| SLC / MLC / TLC / QLC / PLC / HLC | 单/双/三/四/五/六值单元 | 每单元 1/2/3/4/5/6 bit,对应 2–64 个 VTH 电平;市售以 TLC/QLC 为主。 |
| Gray code | 格雷码 | 相邻电平编码 Hamming 距离恒为 1,单次电平漂移最多 1-bit 错误。 |
| ISPP | 增量步进脉冲编程 | 脉冲幅度逐步递增 + 每脉冲后验证(program & verify),收紧 VT 分布的标准方法。 |
| Foggy-fine | 粗调–细调编程 | TLC 先粗分 8 态再小步微调的两阶段编程方案。 |
| Endurance | 耐久性 | 记忆窗口塌缩前可承受的 P/E 循环次数(SLC 10⁵⁻⁶ / TLC ≤10⁴ / QLC <10³)。 |
| Retention | 数据保持 | 电荷维持记忆窗口的时间,尤指高温下;商用 85°C / 工业 125°C / 车规 150°C。 |
| Trapping / De-trapping | 电荷俘获 / 去陷阱 | 电子被氧化层陷阱捕获(耐久退化主因);高温释放使 VTH 下降(保持失效)。 |
| SILC | 应力诱发漏电流 | 循环应力产生氧化层陷阱,电子经陷阱辅助隧穿(两步"垫脚石")泄漏。 |
| Arrhenius plot (1/kT) | 阿伦尼乌斯图 | log(失效时间) vs 1/kT 作图,斜率即激活能 EA(例 0.66 eV);T 必须用开尔文。 |
| Erratic over-programming | 异常过编程 | 氧化层空穴陷阱局部压低势垒、FN 电流异常增大导致 VTH 过冲长尾。 |
| ECC | 纠错码 | 页内冗余位纠正读出错误;Gb 级容量下干扰/噪声错误的必备防线。 |
| Cell-to-cell interference (FG-FG coupling) | 单元间干扰 | 相邻浮栅寄生电容耦合使邻元编程改变本元 VTH,2D NAND 微缩第一大障碍。 |
| Few electron problem | 少电子问题 | 10 nm 级单元仅存约 20–30 个电子,丢 1 个即移约 500 mV,多值数据立即出错。 |
| Air gap | 气隙 | 浮栅间留空气(ε≈1)以最小化寄生电容,已用于 sub-20 nm 2D NAND。 |
| RTN | 随机电报噪声 | 界面陷阱随机俘获/释放载流子造成的 Vth/电流双态时间跳变,尺寸越小越严重。 |
| SONOS / MONOS / TANOS | 电荷俘获叠层 | Si/Oxide/Nitride/Oxide/Si 系列结构;MONOS(W 金属栅)是 3D 垂直 NAND 主流单元。 |
| CTF | 电荷俘获闪存 | 以绝缘氮化物局域陷阱存储电荷的单元,电荷不可流动、抗单点漏电;擦除依赖空穴。 |
| BiCS / P-BiCS / TCAT | 早期 3D NAND 架构 | Toshiba 2007 首创(Bit-Cost Scalable,共享光刻);P-BiCS U 形串源线上移;TCAT(Samsung)钨栅+体擦除。 |
| Gate-first / Gate-last | 栅先 / 栅后(替换栅) | FG 3D NAND 用栅先(Intel/Micron 曾用);CTF 必须栅后——去牺牲氮化物后钨回填,已成绝对主流。 |
| Memory hole / Core-shell | 存储孔 / 芯-壳结构 | 一次光刻刻穿 ONON 叠层的垂直孔;柱体 = SiO₂ 芯 + poly-Si 沟道壳 + O/N/O 俘获层。 |
| Staircase / Resist trimming | 字线阶梯 / 光刻胶修剪 | 逐层暴露字线接触的阶梯结构,靠横向收缩光刻胶循环刻蚀、一次光刻完成。 |
| Body erase / GIDL erase | 体擦除 / GIDL 擦除 | 由衬底直接供空穴 vs 由选择管边缘带带隧穿产生空穴;CuA 普及后 GIDL 为主流。 |
| 2πrH | 环栅有效面积 | 3D 环栅单元侧面积(r 柱半径、H 层厚),远大于 2D 的 F²,解决少电子问题。 |
| Two-deck | 双甲板工艺 | 把柱刻蚀拆成两段(如 96 层 = 2×48)以缓解高深宽比刻蚀难度。 |
| HAR etch | 高深宽比刻蚀 | 3D NAND 制造核心瓶颈;侧壁角偏离 90°(实测约 87.6–89°)会侵蚀密度收益。 |
| CuA / PuC | 外围置于阵列下方 | 外围电路做在硅衬底、3D 阵列叠其上,省面积提密度;使 GIDL 擦除成为必需。 |
| Xtacking | 混合键合方案 | YMTC:外围 CMOS 与 NAND 阵列分别制造后 Cu 混合键合。 |
| V-NAND / Z-NAND | 三星产品名 | 商用 3D 垂直 NAND(首代 24 层 128 Gb);Z-NAND 为高速 SLC 产品线(编程 1–3 µs)。 |
| NVMe / SATA | SSD 接口 | NVMe 走 PCIe 约 7 GB/s;SATA 兼容 HDD 约 600 MB/s。 |
| GMR | 巨磁阻效应 | HDD 读头机理,磁化平行/反平行时电阻不同。 |