Lecture 1:存储器技术概览
1. 开场:VLSI 系统的三大支柱 P1 00:00:03
本讲是课程第 1 节(Section 1: Overview of Memory Technologies),大纲分三块:① 智能手机中的存储器(Memory in a Smartphone);② 存储器层次结构(Memory Hierarchy);③ 阵列效率与芯片实例(Array Efficiency and Chip Examples)。
教授首先给出全课程的立足点:构建 VLSI 系统的三大支柱(three pillars)是 计算(Computation)——处理器/逻辑模块、存储(Memory)——存放数据的各类存储器、通信(Communication)——在计算与存储单元之间搬运数据的互连/IO。幻灯片标题点题:"VLSI System – Don't Forget the Memory":存储器是系统中与计算同等重要的组成部分。

2. 智能手机里的存储器:S20 Ultra 拆解与成本分解 P1 00:01:43
引用逆向工程公司 TechInsights 对 Samsung S20 Ultra(2020 年旗舰机)的拆解(teardown)报告——教授指出其主要组件构成与当今手机并无本质区别。主板正面两个最大的封装都是存储芯片:
- 12GB LPDDR5 DRAM(Low Power Double Data Rate 第 5 代),与 Qualcomm Snapdragon 865 应用处理器以 PoP(Package on Package)共封装;
- 256GB NAND Flash(Samsung KLUEG8UHDB,UFS 3.0 接口),用于数据存储。
其余组件包括电源管理 IC(PMIC,将充电器电压转换/调节后给各芯片供电)、5G modem(Snapdragon X55)、Wi-Fi/BT 模块等;主板背面多为电源管理/稳压与 Wi-Fi 模块。"处理器 + DRAM + NAND"是系统中最大的两类芯片,由真实产品建立实物直觉。

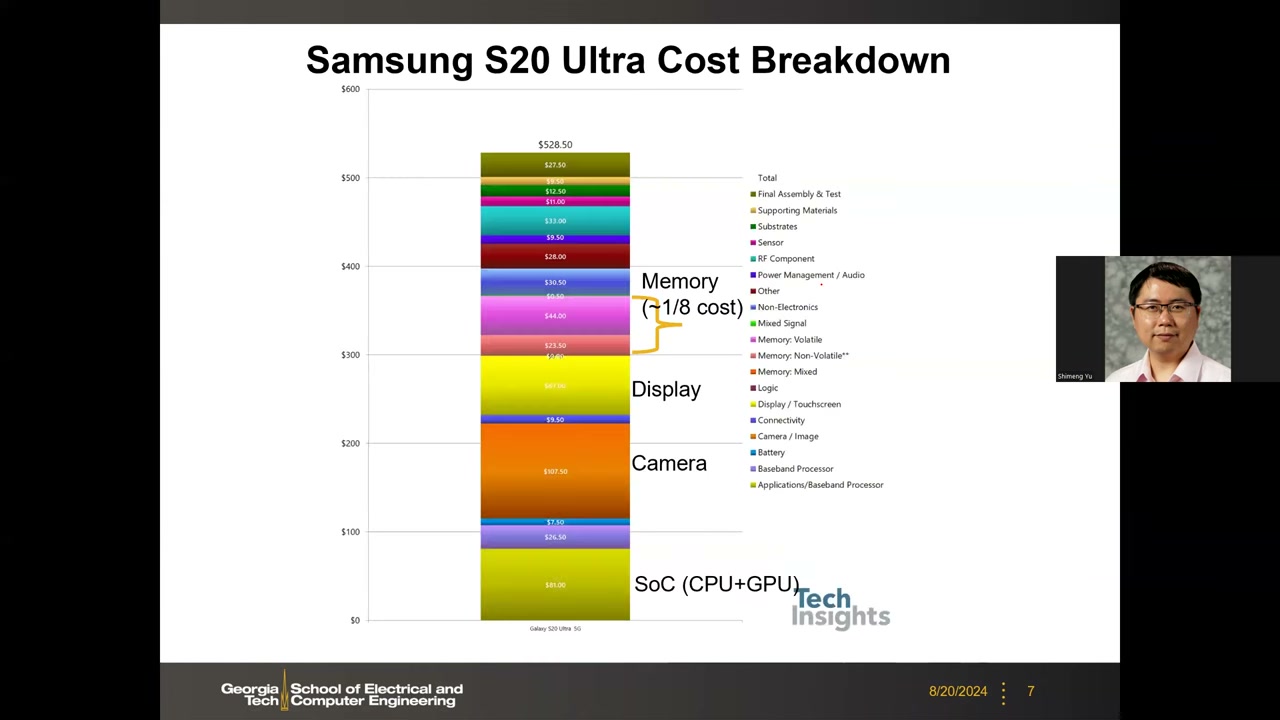
成本分解 P1 00:04:53
据 TechInsights 数据,整机总成本(含材料、设计、制造、测试)约 $528.50(2020 年),而该机售价超过 $1000(约 $1300),可见利润空间。成本大项:SoC(CPU+GPU,约 $81)、三摄相机(约 $107.50)、OLED 显示屏;存储约占整机成本的 1/8,在图中分为 Volatile(DRAM)与 Non-Volatile(NAND)两块独立(standalone)芯片。
3. 存储器层次结构(Memory Hierarchy) P1 00:08:29
存储子系统按金字塔层次组织,金字塔两侧的轴分别是 延迟(Latency) 与 容量(Capacity):
| 层级 | 技术 | 典型容量 | 典型延迟 |
|---|---|---|---|
| L1 Cache | SRAM | ~100 KB | < 1 ns(与处理器同频,1 个时钟周期;3 GHz 时约 0.3 ns) |
| L2 Cache | SRAM | ~MB | ~1 ns(约 2 个周期) |
| L3 Cache | SRAM | ~10 MB | ~1.5 ns(约 4 个周期) |
| Last Level Cache | eDRAM 或新兴存储器 | ~100 MB | ~10 ns |
| 主存(Main Memory) | DRAM | ~10 GB | ~100 ns |
| Storage Class Memory | 新兴存储器 | ~100 GB | 介于 DRAM 与 NAND 之间 |
| SSD | NAND Flash | ~TB 级 | ~10 µs |
| HDD | 磁记录 | > 10 TB | ~ms |
当今处理器 99% 的 cache 都用 SRAM 实现。课堂提问:同为 6T SRAM,为何 L1/L2/L3 特性不同?答案在晶体管的 W/L(宽长比):L1 要求高速,把晶体管尺寸放大(W/L 更大)以提供更大电流、更快充放电,因而同样面积下容量小;L3 追求大容量,用最小尺寸/最小间距的晶体管,速度变慢。每个 bit 都是相同的 6 管结构,差别不在物理距离或金属层。
两组术语对应关系:on-chip memory = embedded memory(片上/嵌入式,与处理器核同片,如 cache);off-chip memory = standalone memory(片外/独立芯片,如 DRAM、NAND)。金字塔上的红线为 易失(volatile)/非易失(non-volatile)分界:线上方(SRAM/eDRAM/DRAM)断电丢数据,线下方(SCM/NAND/HDD)断电保持;习惯上 volatile 称 memory、non-volatile 称 storage,本质区别是数据保持(data retention)。HDD 在消费产品中已少见,但数据中心仍用其做大容量长期归档——仍是最便宜的长期存储方式。

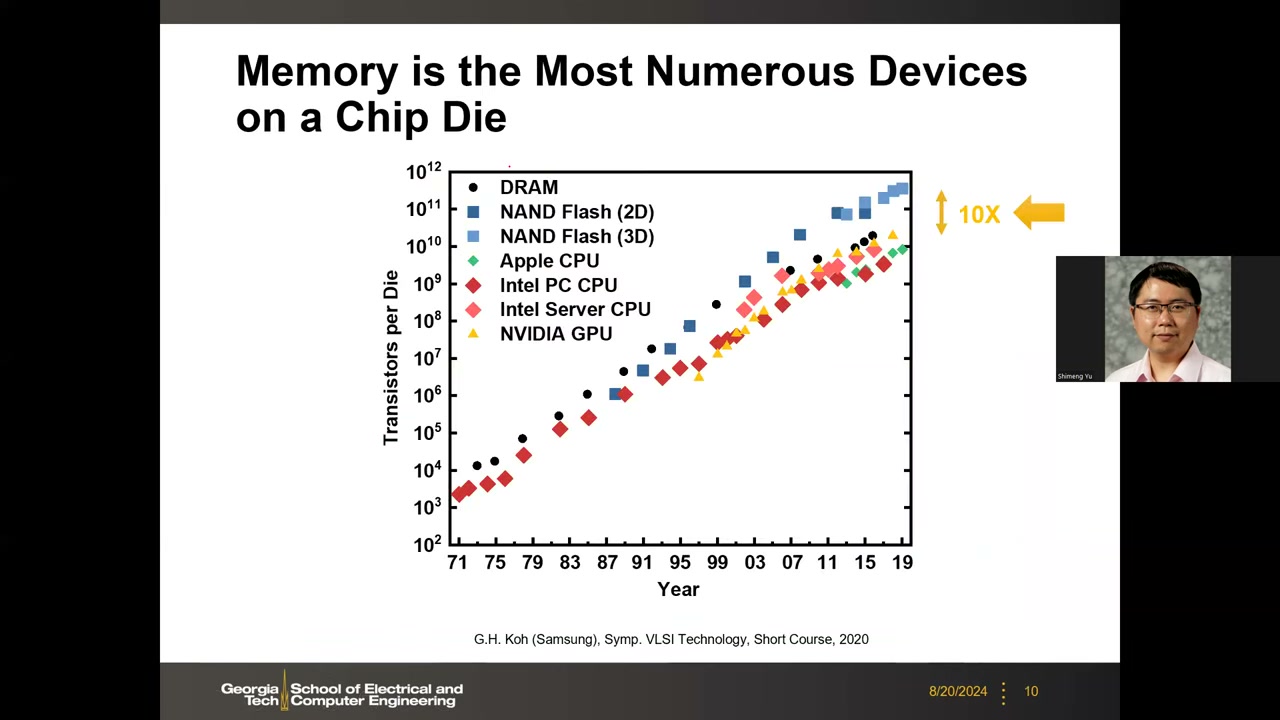
4. 晶体管数量趋势:95% 的硅都在做存储单元 P1 00:17:33
数据来源:G.H. Koh(Samsung),Symp. VLSI Technology Short Course, 2020。纵轴为每 die 晶体管数(10²–10¹²,对数轴),横轴 1971–2019,涵盖 DRAM、2D/3D NAND Flash、Apple CPU、Intel PC/Server CPU、NVIDIA GPU:
- 过去 50–60 年每 die 晶体管数保持指数增长(摩尔定律趋势);图右侧标注 10X——NAND 比 CPU 高约一个数量级。
- 高端 CPU/GPU(含片上 SRAM,超过一半晶体管是 SRAM)每 die 约 10⁹–10¹¹ 个晶体管。
- NAND Flash 每 die 已达 Tb(terabit)级,即每 die 超过 1 万亿个晶体管——芯片上数量最多的器件是存储单元。
5. 大数据、内存墙与能耗瓶颈 P1 00:21:15
引自 Stanford CS 教授 David Cheriton:21 世纪工作负载的特点是海量松散结构化数据(large amounts of loosely-structured data)——流媒体视频/音频、自然语言、实时传感器、上下文环境;手机拍照摄像、车载/监控摄像头持续产生数据,再加上 ChatGPT 类自然语言查询。结论:Big Data means Big Memory——既要容量(capacity)存数据,也要带宽(bandwidth)访问数据。
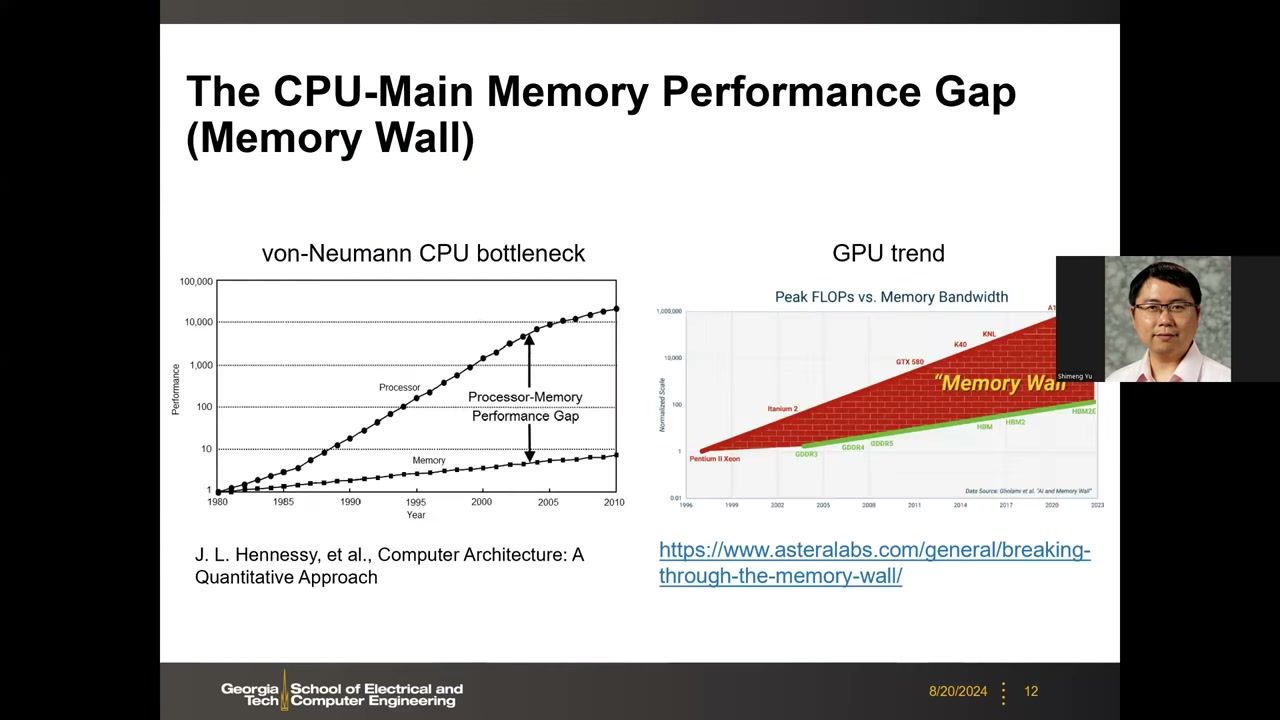
Memory Wall:CPU—主存性能差距 P1 00:22:34
内存墙(Memory Wall)最早指 von Neumann 架构瓶颈。Hennessy 等教材《Computer Architecture: A Quantitative Approach》中的经典图显示:1980–2010 年间处理器与 DRAM 的归一化性能(带宽)差距持续拉大——处理器受益于工艺微缩与多核越算越快,瓶颈在到 DRAM 的 IO 带宽。GPU 趋势图(Peak FLOPs vs Memory Bandwidth,数据源 Gholami et al. "AI and Memory Wall")同样表明:从 Pentium II Xeon 到 H100,算力增长远快于显存带宽(GDDR3→GDDR5→HBM→HBM2E/HBM3),缺口越来越大。这正是学术界研究存内计算(in-memory computing)/近存处理(near-memory processing)的动机:不再在处理器与 DRAM 之间来回搬数据,而是在 DRAM(甚至 NAND)附近或内部做处理。
课堂问答补充:互连是瓶颈——DDR 类 DRAM 经引脚插在主板上、通过真实数据总线传输,RC 与布线损耗大,接口电路高速传输非常耗电;数据一旦跨芯片(板级 cm~十 cm 量级)就很低效,而片内互连只有 mm~十 mm 量级。
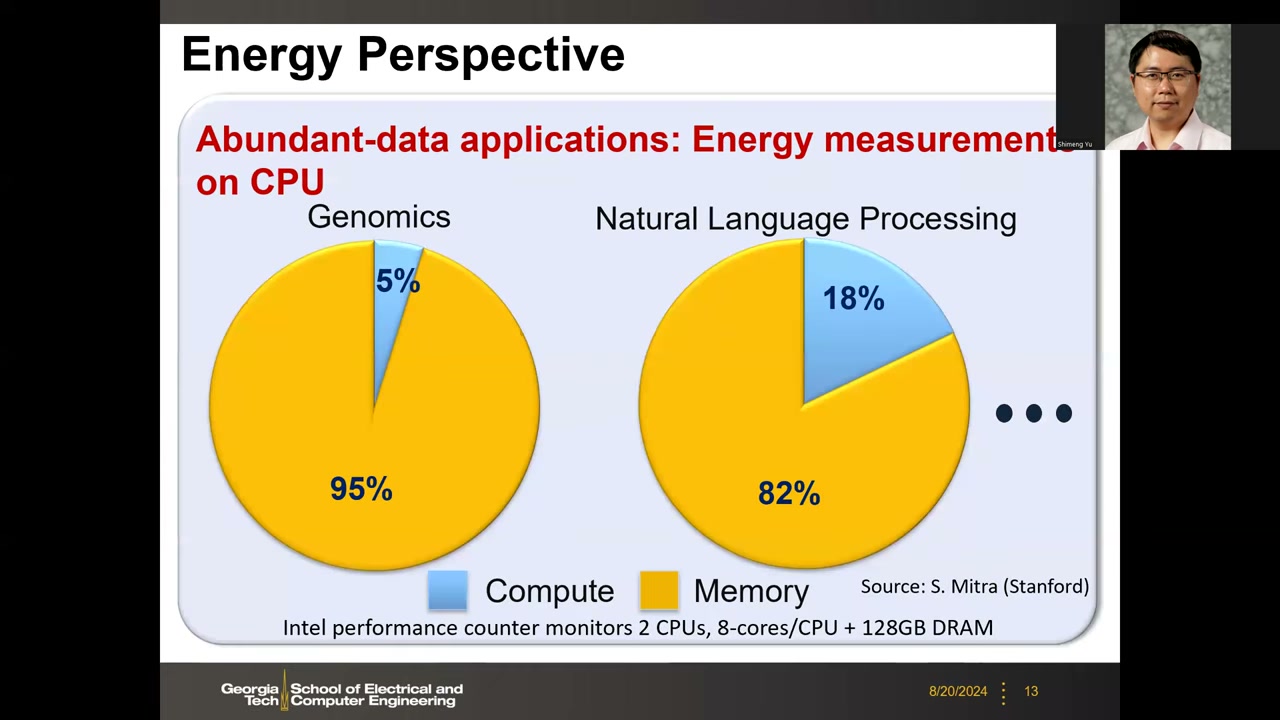
能耗视角:能量花在数据搬移上 P1 00:25:42
数据来源:S. Mitra(Stanford);测量平台为 2 个 CPU(每 CPU 8 核)+ 128 GB DRAM,用 Intel 性能计数器监测。运行真实大数据负载的能耗分解:基因测序(Genomics)95% 能耗在 Memory、仅 5% 在 Compute;自然语言处理(NLP)82% 在 Memory、18% 在 Compute。
6. 训练大语言模型的内存带宽需求 P1 00:27:15
图为 Dense LLM Theoretical Bandwidth Requirements(FP8 量化;来源 SemiAnalysis "GPT-4 architecture & infrastructure"):横轴模型规模 65B→50,000B 参数,纵轴所需内存带宽(1,000–10,000,000 GB/s,对数轴)。
- GPT-4 约 1T(一万亿)参数,对应所需带宽约 100,000 GB/s 量级;而当时能买到的最强 GPU 是 NVIDIA H100(B100 已发布未发货),单卡带宽远低于需求——即使 8×H100 集群仍达不到 1T 参数模型的需求线(图中虚线自下而上:A100、H100、8×H100、256×H100)。
- 因此跑 LLM 极其昂贵:需要成千上万张 H100,单卡价格高昂(教授估计数十万美元级),8 卡即数百万美元,集群投资可达数千万至上亿美元——根源是带宽跟不上工作负载。
课堂问答:8×H100 不是同一封装,而是机架级真实系统(8 块板);DRAM 刷新(refresh)功耗约占 DRAM 总功耗的 10%–20%(依技术而定)。

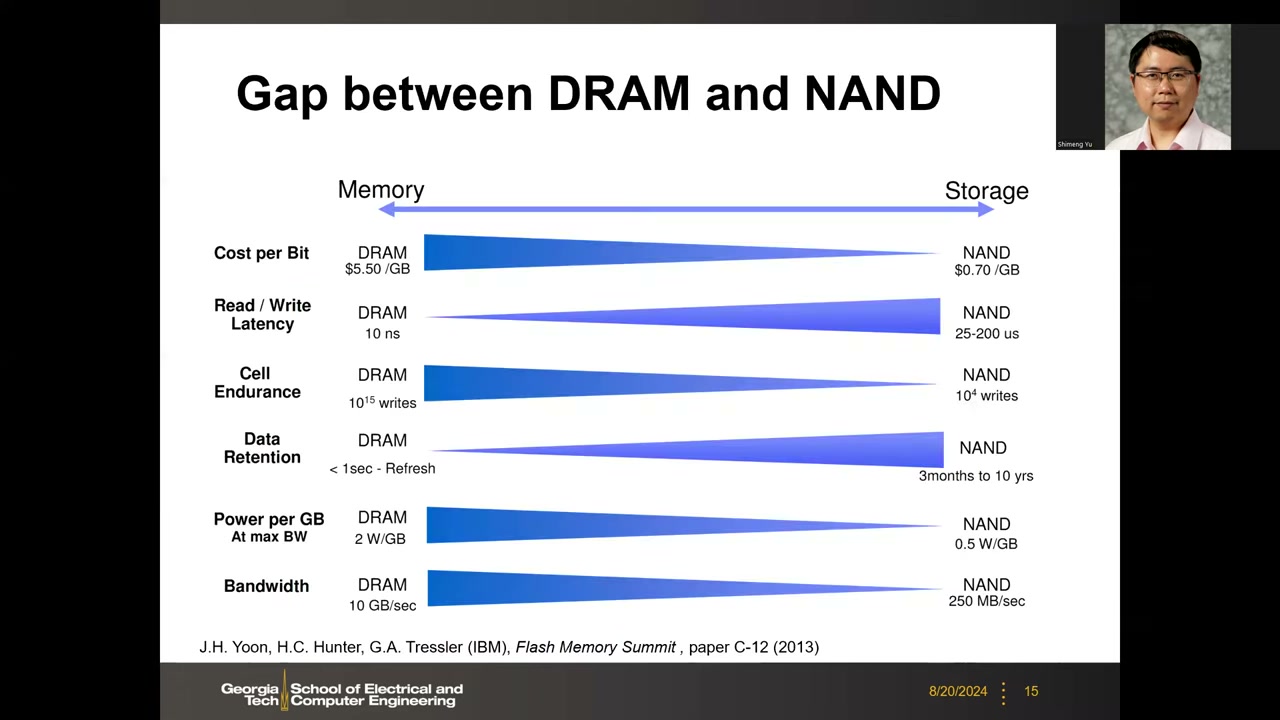
7. DRAM 与 NAND 的规格差距与新兴存储器的机会 P1 00:32:43
来源:J.H. Yoon, H.C. Hunter, G.A. Tressler(IBM),Flash Memory Summit, paper C-12, 2013。Memory(DRAM)与 Storage(NAND)的六维对比:
| 指标 | DRAM | NAND |
|---|---|---|
| 每 bit 成本(Cost per Bit) | $5.50 /GB | $0.70 /GB |
| 读/写延迟 | 10 ns | 25–200 µs |
| 单元耐久性(Endurance) | 10¹⁵ 次写 | 10⁴ 次写 |
| 数据保持(Retention) | < 1 s(需刷新) | 3 个月–10 年 |
| 满带宽功耗(Power per GB) | 2 W/GB | 0.5 W/GB |
| 带宽(Bandwidth) | 10 GB/s | 250 MB/s |
新兴存储器与 3D XPoint 的教训 P1 00:35:04
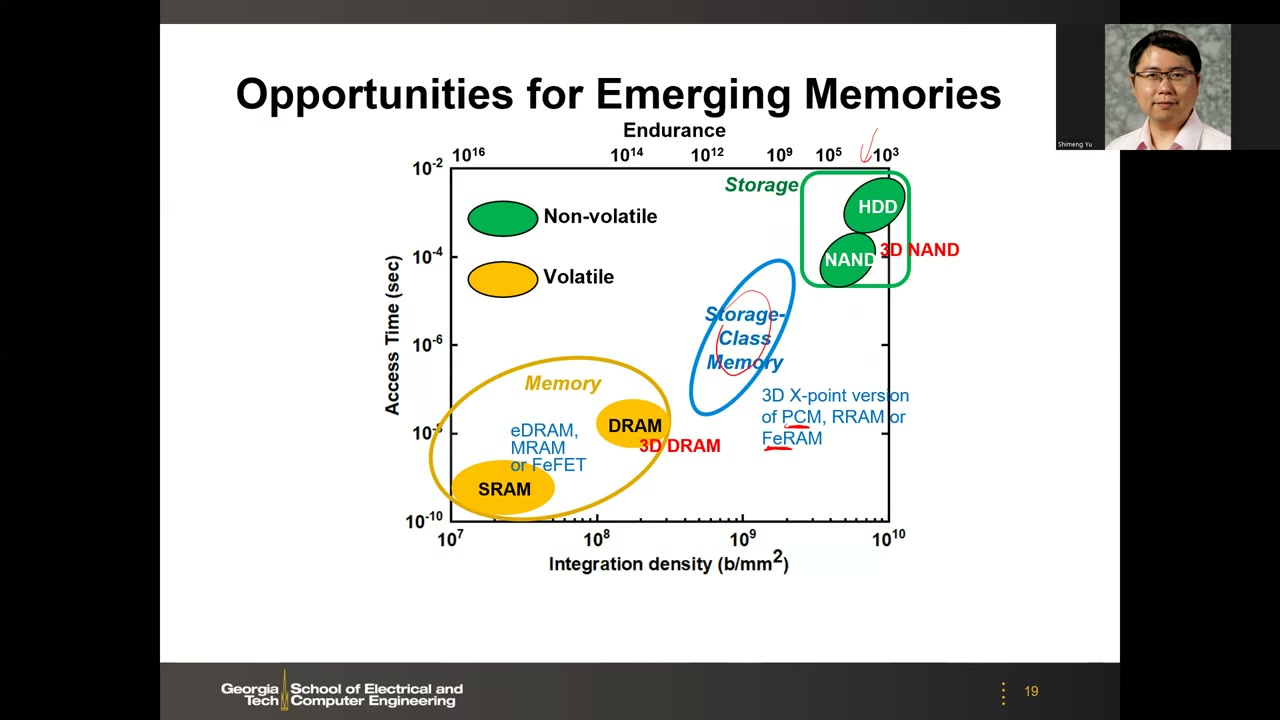
存储层次中出现了"空白地带"(white space):速度/容量缺口——许多应用需要大量 GB 且最好非易失。核心问题(幻灯片原话):"Which memory for which application?"(哪种存储器适合哪种应用?)新兴存储器研究已 15+ 年(教授入行至今),至今仍被称为 "emerging"——尚未大规模量产商用。根本原因:主流 NAND 与 DRAM 仍在持续微缩(3D NAND、3D DRAM 提高密度),新兴存储器始终难以抢占大市场;但 3D 化只提升密度、不提升速度——所以人们寄望于 Storage Class Memory(SCM,存储级内存) 填补缺口。
机会图(Access Time vs Integration Density):黄色 Volatile "Memory" 圈(SRAM、eDRAM/MRAM/FeFET、DRAM/3D DRAM,access time ~10⁻¹⁰–10⁻⁸ s,密度 ~10⁷–10⁹ b/mm²);绿色 Non-volatile "Storage" 圈(NAND/3D NAND、HDD,access time ~10⁻⁴–10⁻² s,密度 ~10⁹–10¹⁰ b/mm²);中间蓝色椭圆即 Storage-Class Memory(3D XPoint 式 PCM、RRAM 或 FeRAM)。顶轴 Endurance 从 10¹⁶(SRAM 侧)到 10³(HDD/NAND 侧)。幻灯片备注的密度参考值:SRAM 10–50 Mb/mm²、DRAM 100–300 Mb/mm²、SCM 500 Mb–2 Gb/mm²、NAND 3–10 Gb/mm²。
关于 endurance 的课堂问答:NAND 耐久性有限(10⁴ 次)但够用,因为存储类访问不频繁(拍照频率分钟级),按产品 3–10 年寿命估算所需写入次数即可;而 SCM 若用作内存,对 endurance 的要求高得多——这是其挑战之一。

8. 通用存储阵列架构 P1 00:40:24
(此处课堂投影仪故障重启,教授切到 PowerPoint 窗口继续讲解"Generic Memory Array Architecture"一页,无独立干净截图。)无论 SRAM、DRAM 还是 Flash,二维空间中存储器都组织为阵列架构——这是贯穿全课程所有存储技术的通用模型:
- 组成:行译码器(Row Decoder)、列译码器(Column Decoder)、列选通(Column Mux);行地址 M bits、列地址 N bits。
- 译码后得到 2M 行,每行称字线(Word Line, WL);每列称位线(Bit Line, BL);WL 与 BL 的交点即一个存储单元(memory cell)。
- 阵列总位数 = K × 2M × 2N。K 的含义:列译码不是逐条 BL 译码,而是以 K bit 为一组(典型 K=8,即一个 byte)整组选出——每次列译码同时取出 8 条列上的 8 bit。
- 数据通路:写驱动(Write Driver)把数据写入,灵敏放大器(Sense Amplifier)把数据读出,再送到 IO。
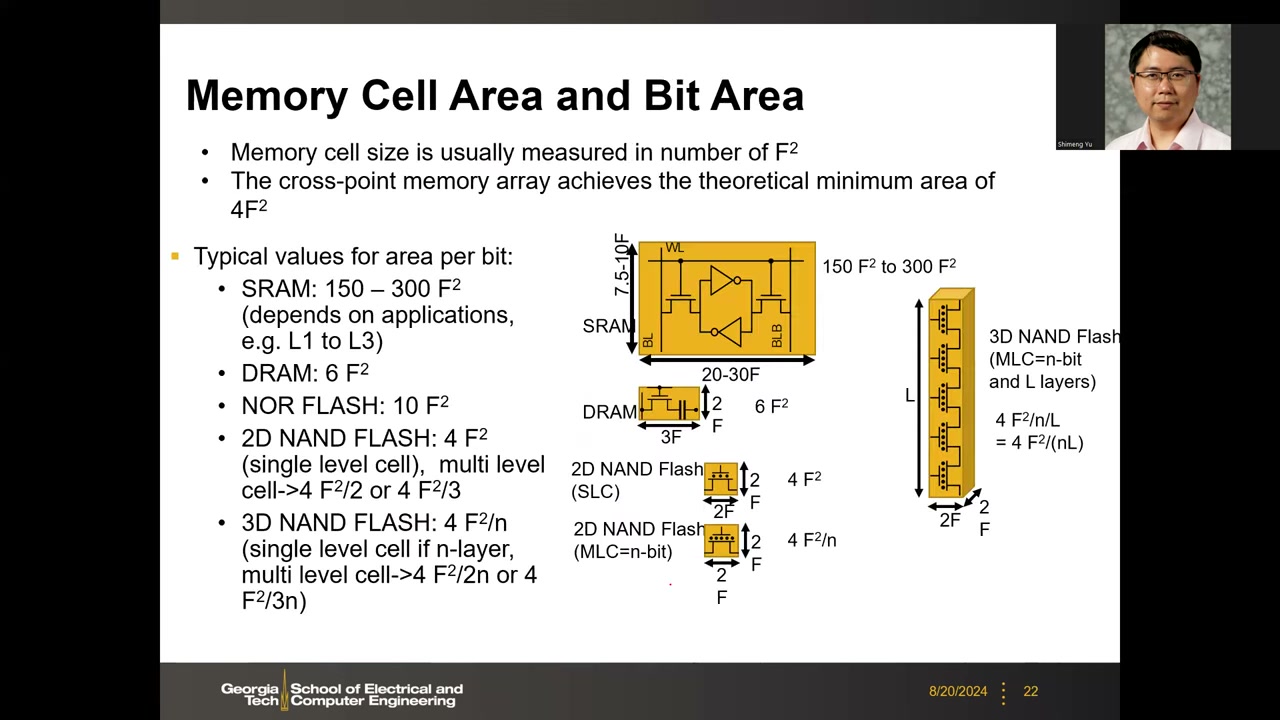
9. 存储单元面积与位面积(F² 度量) P1 00:42:55
(教授提示:本页是作业/考试考点。)单元面积惯用 F² 度量,F = feature size(特征尺寸),即给定工艺节点下光刻可分辨的理论最小尺寸(最小半间距)。
| 技术 | 单元面积 | 说明 |
|---|---|---|
| SRAM(6T) | 150–300 F² | 取决于应用层级:L1 用大管子 ~300F²,L3 用最小尺寸 ~150F²;版图约 7.5–10F × 20–30F |
| DRAM(1T1C) | 6 F² | 2F × 3F |
| NOR Flash | ~10 F² | 后续课程再讲 |
| 2D NAND Flash(SLC) | 4 F² | 达到二维理论极限(2F × 2F) |
| 2D NAND Flash(MLC,n bit/cell) | 4 F²/n | 2 bit/cell → 4F²/2;3 bit/cell → 4F²/3 |
| 3D NAND Flash(L 层,n bit/cell) | 4 F²/(nL) | SLC 为 4F²/L |
MLC(多值单元):SRAM/DRAM 是二值存储(一个单元只存 0 或 1),而 Flash 一个单元可存多 bit(如 00/01/10/11 = 2 bit),等效位面积按 bit 数除。3D NAND:把 2D NAND 的晶体管串(string)旋转 90°,沿垂直方向堆叠 L 层晶体管;硅衬底上的占地仍是 2F×2F,投影到二维后每 bit 等效面积除以 L。目前最新产品 L 已超过 300 层——这就是 NAND 每 bit 硅面积极小、价格极便宜的原因。课堂问答:3D NAND 良率——量产产品良率需达 99.x%,业界已解决,不是大问题。
10. 存储阵列效率(Array Efficiency) P1 00:50:08
定义:阵列效率 = 存储单元占用面积 ÷(存储单元 + 其外围电路)面积的百分比,且只统计存储部分(memory part only)。它是衡量存储芯片/宏设计好坏的指标——设计目标是最大化阵列效率:硅面积应尽量花在真正存数据的单元上,外围电路只是辅助读写,理想情况下越少越好。
| 芯片类型 | 典型阵列效率 |
|---|---|
| 微处理器(cache,SRAM) | ~30–50% |
| DRAM | ~60–70% |
| NAND | ~70–80% |
外围电路(peripheral circuitry)包括:地址译码器(address decoders)、灵敏放大器(sense amplifiers)、控制逻辑(时序控制、状态控制)、片上高压产生用的电荷泵(charge pumps)。幻灯片示例:2D NAND 芯片版图(两个 4Gb Memory Array Plane0/Plane1,中间 Row Decoder,底部 BL 控制电路、外围电路、电荷泵、Pads),以及 8 核 CPU die photo(共享 L3 cache 区域)。

Part 1 因投影仪故障未讲完,芯片实例从 Part 2 开始(Part 2 开头先回顾了本页 P2 00:00:00)。以下各节用真实硅片数据(Intel / IBM / AMD / Nvidia / SK Hynix / NAND 芯片)逐一验证阵列效率概念,并展望 SRAM/DRAM/NAND 各自进入的 3D 时代。
11. 案例 1:Intel Westmere 与 L3 阵列效率计算 P2 00:00:31
来源:N. Kurd et al., "Westmere: A Family of 32 nm IA Processors," ISSCC 2010, paper 5.1。2010 年发布,有 6 核与 2 核两个版本,6 核版含 1.17B(11.7 亿)晶体管:
- 12 MB 共享 L3 cache:采用 0.171 µm² 的 6T SRAM 单元;工作电压双模式——active Vmin = 900 mV,retention(待机保持)= 700 mV。
- 每核 256 KB L2 cache:采用更大的 0.275 µm² 6T SRAM 单元,active Vmin = 700 mV。
- 这正是上面讲过的权衡:越靠近核心(L2)用更大单元换速度,L3 容量优先用更小单元提高密度。
- 其它:DRAM 接口 DDR3-LV(1.5 V/1.35 V);core/un-core 支持电源门控(power gating),un-core 固定电压。die photo 上可见 6 个 Core、共享 L3 Cache、Memory Controller、Queue、QPI 接口等区域。

数据表与"信封背面"计算 P2 00:02:15
| 处理器 | 工艺 | 核数 | L3 | Die 面积 | 晶体管数 | 核电压范围 | TDP |
|---|---|---|---|---|---|---|---|
| Nehalem-4Core | 45 nm | 4 | 8 MB | 262 mm² | 731 M | 0.75–1.25 V | 60–130 W |
| Westmere-6Core | 32 nm | 6 | 12 MB | 240 mm² | 1.17 B | 0.72–1.20 V | 60–130 W |
| Westmere-2Core | 32 nm | 2 | 4 MB | 78 mm² | 384 M | 0.72–1.20 V | 10–50 W |
L3 cache 阵列效率的"信封背面"计算步骤:
- 从 die photo 用尺子估测:L3 cache(含其控制器)约占总芯片面积 26%;
- 公式:阵列效率 = SRAM 单元面积 × 比特数 ÷ 芯片面积(只算 memory 部分);
- 代入:SRAM 单元 0.171 µm²;比特数 12 MB = 96 Mb;L3 区域面积 = 240 mm² × 0.26;
- 结果:0.171 µm² × 96 M ÷ (240 mm² × 0.26) ≈ 27%(只考虑 L3,不含其它电路)。


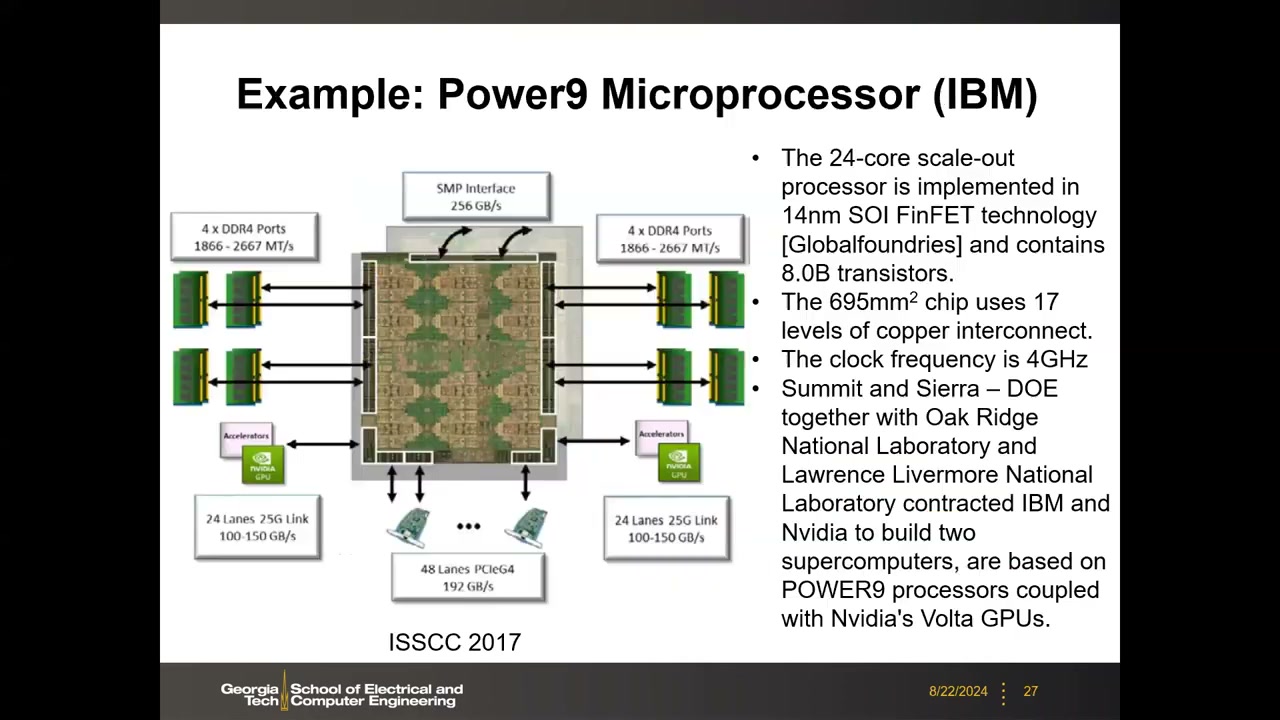
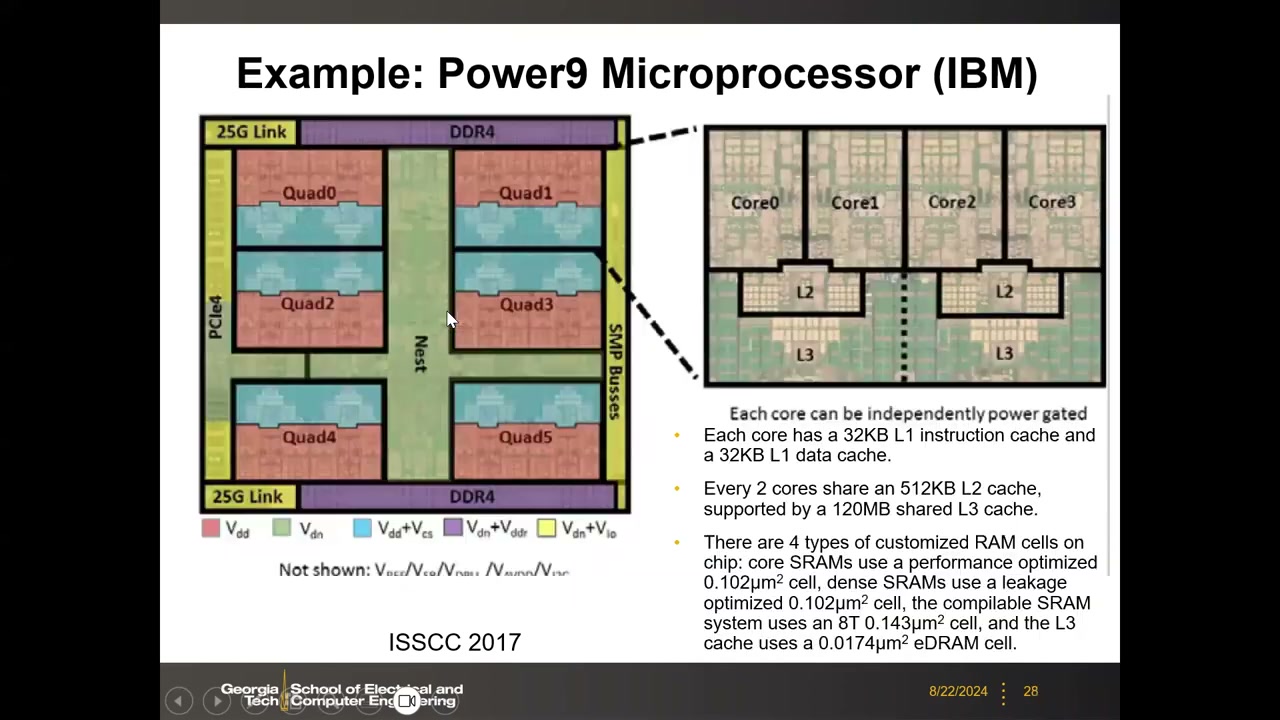
12. 案例 2:IBM Power9——用 eDRAM 做 L3 P2 00:05:30
ISSCC 2017 发表;24 核 scale-out 处理器,GlobalFoundries 14 nm SOI FinFET 工艺(IBM 与 GF 合作),8.0B 晶体管,die 695 mm²,17 层铜互连,时钟 4 GHz。面向高性能计算:DOE 与 Oak Ridge / Lawrence Livermore 国家实验室的 Summit 和 Sierra 超级计算机即基于 Power9 + Nvidia Volta GPU。系统接口:4×DDR4 端口(1866–2667 MT/s)、SMP 接口 256 GB/s、48 lane PCIe G4(192 GB/s)、25G link(100–150 GB/s)连接加速器。
缓存层级:每 die 有 6 个 Quad,每 Quad 4 核;每核 32 KB L1 指令 cache + 32 KB L1 数据 cache;每 2 核共享 512 KB L2;全片共享 120 MB L3。每核可独立电源门控。
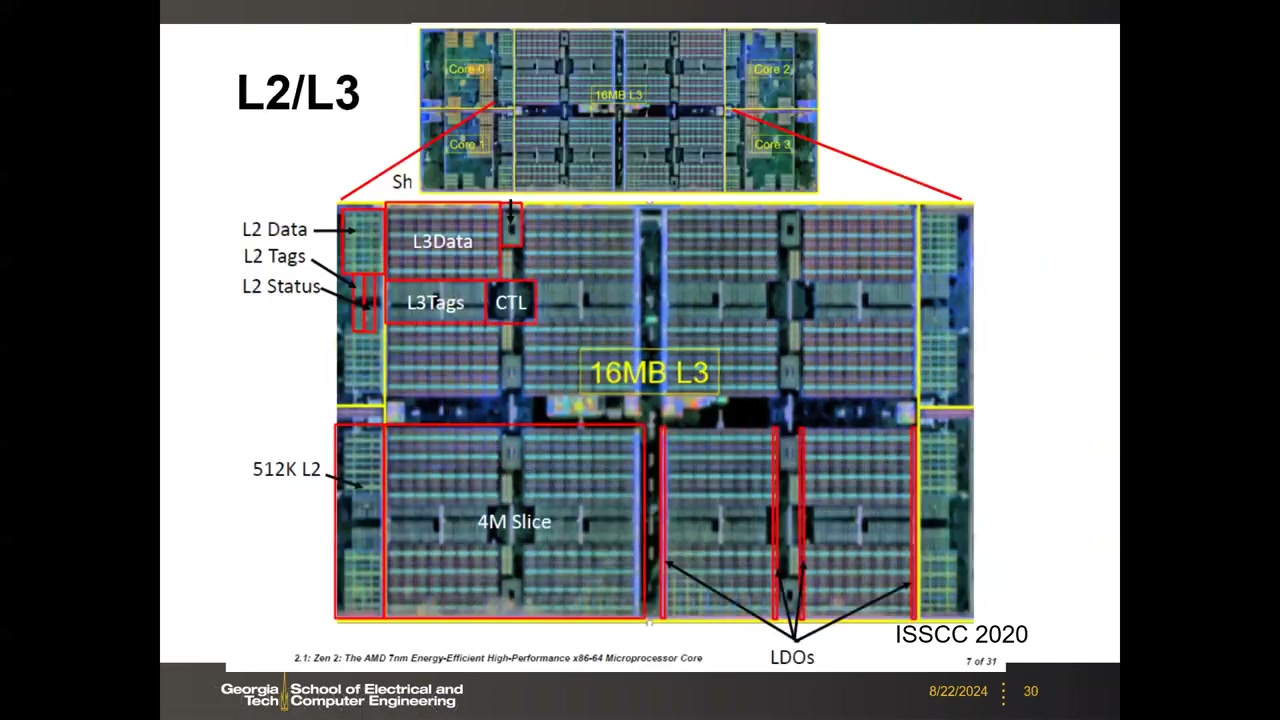
13. 案例 3:AMD Zen 2 版图与 Zen→Zen 2 设计规则 P2 00:09:01
TSMC 7 nm FinFET 工艺,ISSCC 2020 披露;用于商用 Ryzen 3 处理器。一个 CCX 的 die photo:4 核(Core 0–3),每核 32 KB L1(指令/数据分离)+ 512 KB L2;中央为 4 核共享的 16 MB L3。
- L3 细看:分成 4 个 4 MB slice;每个 slice 内除数据阵列(L3 Data)外还有 L3 Tags、CTL(控制)等外围逻辑;L2 也分 L2 Data / L2 Tags / L2 Status;版图上还有 LDO(低压差稳压器)。
- 核内放大图:L1 I-Cache 与 Data Cache 分离,周围是 Decode、uCode、Scheduler、ALU、Load/Store、Floating Point、Branch Prediction 等逻辑,旁边即 L2 Cache——直观展示 cache 占核面积的比例。

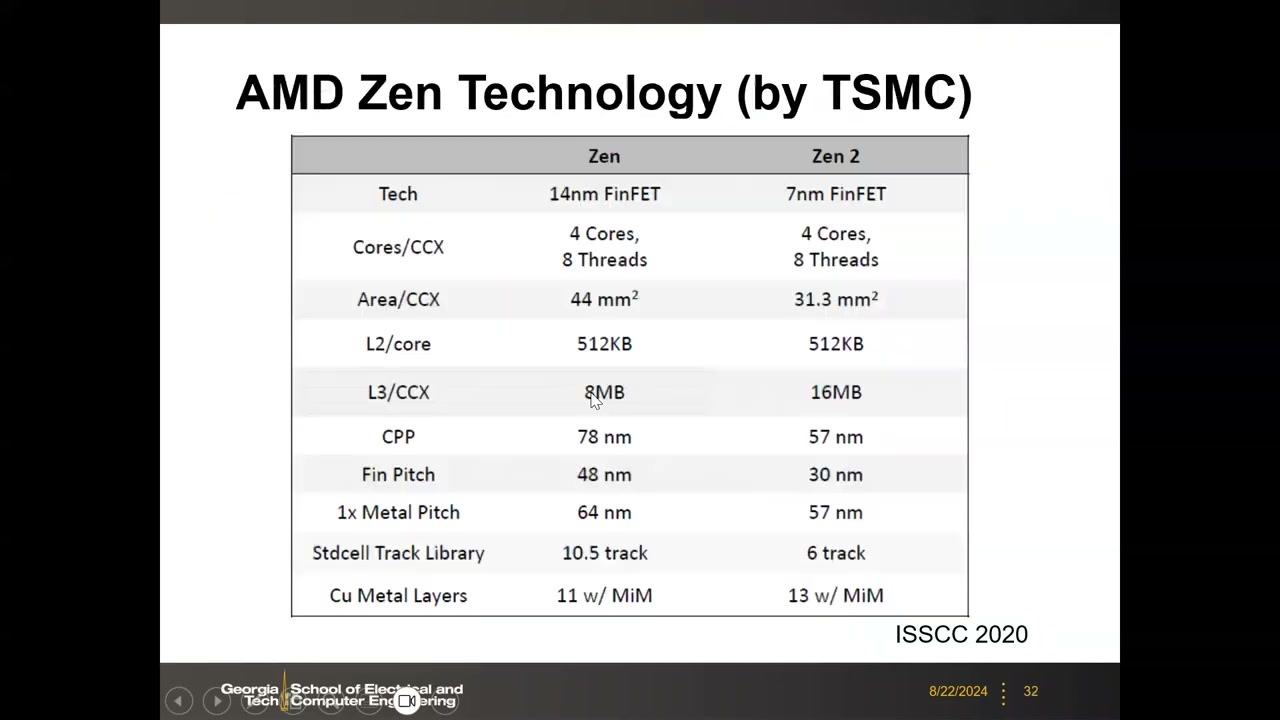
Zen vs Zen 2 技术参数对比 P2 00:10:46
| 项目 | Zen | Zen 2 |
|---|---|---|
| 工艺 | 14 nm FinFET | 7 nm FinFET |
| Cores/CCX | 4 核 8 线程 | 4 核 8 线程 |
| Area/CCX | 44 mm² | 31.3 mm² |
| L2/core | 512 KB | 512 KB |
| L3/CCX | 8 MB | 16 MB |
| CPP(contacted poly pitch) | 78 nm | 57 nm |
| Fin Pitch | 48 nm | 30 nm |
| 1x Metal Pitch | 64 nm | 57 nm |
| 标准单元库 | 10.5 track | 6 track |
| 铜金属层 | 11 层(含 MiM) | 13 层(含 MiM) |
解释:CPP 是源到漏方向相邻栅极(接触多晶硅)的间距,与 Fin Pitch、Metal-1 Pitch 一起是逻辑晶体管/标准单元密度的关键指标;6-track 库指一个标准单元高度内有 6 条 Metal-1 走线轨道;共 13 层金属完成互连布线。
14. SRAM 新时代:AMD 3D V-Cache P2 00:12:24
AMD 在 Zen 3 引入 3D 堆叠 cache(Zen 4 架构当年也已宣布沿用),开创 SRAM 3D 集成先河:
- 结构:专门保留一块只放 L3 cache 的顶部 die(L3D,extended L3 Die),容量 64 MB;底部基础 die 含 CPU 核与 32 MB 片上 L3。两片 die 通过 Cu-to-Cu 混合键合(hybrid bonding) 堆叠。
- 工艺:两片 die 均为 TSMC 7 nm FinFET(TSMC 同时承担键合);金属叠层 13 层 Cu + 1 层 Al;L3D 面积 41 mm²,约为基础 die 的 ~50%。
- 系统视角:因顶部 die 与片上 32 MB L3 是同一物理介质(SRAM),CPU 核与软件看到的是总计 96 MB 可寻址 L3(而不是把 64 MB 当作额外一层"L4 cache");3D V-Cache 与片上 L3 一样运行在 CPU 频率。
- 课堂答疑:据 AMD,混合键合开销极小——从顶部 die 取数据约有 4 个 CPU 时钟周期的额外延迟,但时钟频率相同。

15. GPU 中的 SRAM:Nvidia A100 P2 00:16:54
Nvidia 7 nm A100 GPU 片上 SRAM 总量约 87.25 MB,但组织方式与 CPU 完全不同。GPU 由大量小核并行:Nvidia 称之为 SM(Stream Multiprocessor,流多处理器),是 GPU 的关键计算单元;A100 共 108 个 SM:
- 每个 SM 内:寄存器文件 256 KB/SM(也属 SRAM)、L1 指令 cache、L0 指令 cache、L1 数据 cache + 共享内存 192 KB/SM——每个小核约数百 KB 量级的 L1。
- 108 个 SM 合计 47.25 MB;全片共享 L2 cache 仅 40 MB。

16. DRAM 案例:SK Hynix DDR5 与 H100 上的 HBM P2 00:19:03
SK Hynix 在 ISSCC 2019 发表的第一代 DDR5 芯片(DDR 第五代):
| 项目 | 参数 |
|---|---|
| 容量 | 16 Gb |
| 数据速率 | 6.4 Gbps/pin |
| 供电 | VDD/VDDQ 1.1 V,VPP 1.8 V |
| Die 面积 | 76.22 mm² |
| 工艺 | 1y-nm 4 层金属 DRAM 工艺("10 几 nm"的第二代节点) |
| IO 配置 | X4 / x8 / x16 |
| Burst length | BC8、BL16 on-the-fly |
| RAS 特性 | In-DRAM ECC |
| 均衡方案 | DFE / FFE |
版图特征:DRAM die 非常规整——数十个 bank(图中标注 1 Bank / 1 Bank Group)占据绝大部分面积,外围逻辑只占边角很小区域,这正是 DRAM 阵列效率高(60–80%)的直观体现。细节留到 DRAM 章节。

DRAM 新时代:HBM 与 GPU 共封装(Nvidia H100) P2 00:20:15
DRAM 也因 3D 集成进入新时代:HBM(High Bandwidth Memory,高带宽存储器)是当今 GPU 产品的关键使能技术,Nvidia 从中获益巨大。以 H100(GH100,Hopper 架构,2023-03-21 发布)为例:
| 项目 | 参数 |
|---|---|
| 工艺 / 晶体管 | TSMC 5 nm,80,000 M(800 亿)晶体管,密度 98.3 M/mm² |
| Die 面积 | 814 mm² |
| HBM 配置 | 6 颗 HBM3 堆栈共封装;每堆栈 = 8 片 DRAM die 垂直堆叠 × 16 GB → 共 96 GB |
| 内存总线 / 带宽 | 5120 bit;3.36 TB/s(GPU 从 DRAM 取数带宽) |
| Boost clock | 1837 MHz |
| Cache / SM | L1 256 KB/SM,L2 50 MB;SM 数 132 |
| TDP | 700 W |
| 理论性能 | FP16 248.3 TFLOPS(4:1)、FP32 62.08 TFLOPS、FP64 31.04 TFLOPS(1:2) |
HBM 细节在 DRAM 章节再讲,此处是市场最新产品的预告。

17. NAND 案例:2D NAND 微缩的终点 P2 00:22:25
2D NAND 微缩历程(2008–2014/2015,die 面积年均缩小 28%):42 nm/935 mm²(2008)→ 32 nm/636 mm²(2009)→ 27 nm/480 mm²(2010)→ 21 nm/325 mm²(2011)→ 19 nm/220 mm²(2012)→ 16 nm/175 mm²(2014)→ 14 nm/130.1 mm²(2015 ISSCC,最后一代 2D NAND),最后一代较上代缩小 26%。
最后一代 2D NAND(ISSCC 2016 论文:128Gb 2b/cell,14 nm,tPROG = 640 µs,800 MB/s I/O):单芯片 128 Gb,分 4 个 plane、每 plane 32 Gb 阵列;外围(sense amp、列译码、外围电路与 PAD)位于底部窄条。2014/2015 年 2D 微缩停止,NAND 转向 3D NAND——距今约 10 年。
课堂答疑:2D NAND 无法继续微缩的原因很多——几何上、电学上(单元间耦合干扰)、保持特性(retention)等,细节留到 NAND Flash 章节。

18. 讲者总结(Summary) P2 00:24:06
- 存储器在 VLSI 系统中无处不在;大数据与 AI/ML 工作负载(均为 memory-bound 应用)使存储需求持续增长。
- NAND Flash 已成为主流存储介质(SSD、SD 卡、USB、数据中心存储)。
- DRAM 是新时代 GPU 的关键使能者(HBM);SRAM 也在以 3D V-Cache 等创新稳步前进,提升 CPU 末级缓存。
- 阵列效率是评估存储芯片设计的关键指标。

本讲要点总结
- VLSI 系统三大支柱:计算、存储、通信——存储器与计算同等重要("Don't Forget the Memory")。
- 智能手机中最大的两类芯片是处理器与存储(12GB LPDDR5 + 256GB NAND);存储约占整机成本 1/8,单 bit 极便宜、利润极薄。
- 存储器层次结构是延迟—容量的基本折衷:存储器越大越慢,理想"通用存储器"不存在;金字塔上方易失(SRAM/DRAM)、下方非易失(NAND/HDD)。
- L1/L2/L3 同为 6T SRAM,差别仅在晶体管 W/L:L1 大管子换速度,L3 小管子换容量。
- 全球每年约 95% 的硅用于制造存储单元;NAND 每 die 已超过 1 万亿晶体管,比 CPU 高约一个数量级。
- 内存墙:处理器算力增长远快于到 DRAM 的带宽;真实大数据负载 82–95% 的能耗花在数据搬移而非计算——这是存内计算研究的动机。
- LLM 是 memory-bounded 应用:GPT-4(~1T 参数)所需带宽约 100,000 GB/s 量级,连 8×H100 都达不到需求线。
- DRAM 与 NAND 在成本(~10×)、延迟(3–4 个数量级)等六个维度差距巨大,这一缺口是 SCM/新兴存储器的机会;3D XPoint 的失败在商业而非技术。
- 核心公式:阵列总位数 = K × 2^M × 2^N;二维单元面积极限 4F²;DRAM 6F²、SRAM 150–300F²、3D NAND 每 bit 4F²/(nL)(现已 >300 层)。
- 阵列效率 = 单元面积 ÷(单元 + 外围电路)面积:CPU cache ~30–50%(Westmere L3 实算 ≈27%)、DRAM ~60–70%、NAND ~70–80%;谈 CPU 时必须指明哪一级 cache。
- 三大存储技术都已进入 3D 时代:SRAM 有 3D V-Cache(96 MB 可寻址 L3、混合键合仅 +4 周期)、DRAM 有 HBM(H100:96 GB、3.36 TB/s)、NAND 自 2014/2015 年起全面转向 3D。
- 存储产业的终极目标是降低每比特成本(cost, cost, cost)——对 NAND 而言成本就是一切。
术语表
| 术语 | 中文 | 释义 |
|---|---|---|
| VLSI | 超大规模集成电路 | 由计算、存储、通信三大支柱构成的集成系统。 |
| SRAM(6T) | 静态随机存取存储器 | 6 晶体管单元(交叉耦合反相器保持数据)、最快的易失存储器,用作处理器各级 cache。 |
| DRAM | 动态随机存取存储器 | 1T1C 单元(6F²)、需周期性刷新的易失存储器,作系统主存。 |
| 1T1C | 一管一容单元 | DRAM 基本单元结构:一个存取晶体管加一个存储电容。 |
| eDRAM | 嵌入式 DRAM | 集成在逻辑芯片上的 1T1C DRAM,单元远小于 6T SRAM(Power9 中 0.0174 µm²)。 |
| NAND Flash | NAND 闪存 | 串联结构非易失存储器,单 bit 面积最小(4F²/(nL)),用于 SSD/手机存储。 |
| NOR Flash | NOR 闪存 | 并联结构闪存,单元约 10F²,本讲仅提及。 |
| 2D/3D NAND | 平面/三维 NAND | 平面 NAND 微缩止于 14nm/128Gb(2014/2015),之后转向垂直堆叠的 3D NAND(现 >300 层)。 |
| LPDDR5 | 低功耗 DDR 第 5 代 | 手机用低功耗 DRAM 接口标准。 |
| DDR5 | 第五代双倍数据率内存 | SK Hynix 2019 年首发:16Gb、6.4Gbps/pin、1.1V。 |
| PoP | 堆叠封装 | 手机中 DRAM 与处理器共封装的方式(Package on Package)。 |
| PMIC | 电源管理芯片 | 将输入电压转换并调节后分配给系统各芯片。 |
| UFS | 通用闪存存储 | 手机 NAND 存储的接口标准(S20 Ultra 为 UFS 3.0)。 |
| Cache(L1/L2/L3) | 高速缓存 | 处理器片上 SRAM 多级存储层级:越靠近核心越快越小,越外层容量越大、单元越密。 |
| Memory Hierarchy | 存储器层次结构 | 按延迟—容量折衷组织的金字塔式存储体系。 |
| On-chip / Embedded memory | 片上/嵌入式存储器 | 与处理器核同片集成的存储(如 cache)。 |
| Off-chip / Standalone memory | 片外/独立存储器 | 独立芯片形式的存储(如 DRAM、NAND)。 |
| Volatile / Non-volatile | 易失/非易失 | 断电后数据是否丢失;前者常称 memory,后者称 storage。 |
| Data Retention | 数据保持 | 不供电/不刷新条件下保持数据的时间(DRAM <1s,NAND 3 个月–10 年)。 |
| Endurance | 耐久性 | 存储单元可承受的擦写循环次数(DRAM 10¹⁵,NAND 10⁴)。 |
| Refresh | 刷新 | DRAM 周期性重写以防电荷泄漏,约占 DRAM 总功耗 10–20%。 |
| Memory Wall | 内存墙 | 处理器算力与主存带宽增长失衡造成的性能差距(von Neumann 瓶颈)。 |
| Memory-bound | 受存储限制的 | 性能瓶颈在存储访问而非计算的工作负载(如大数据、AI/ML、LLM)。 |
| In-memory Computing | 存内计算 | 在存储器内/附近处理数据以避免数据搬移的研究方向。 |
| LLM | 大语言模型 | 如 GPT-4(~1T 参数),是 memory-bounded 应用。 |
| HBM | 高带宽存储器 | 多片 DRAM die 垂直堆叠(H100 为 8 层/堆栈)并与 GPU 共封装;H100 用 HBM3 共 96GB、3.36TB/s。 |
| FLOPs | 每秒浮点运算次数 | 处理器/GPU 计算吞吐量指标。 |
| Storage Class Memory(SCM) | 存储级内存 | 性能介于 DRAM 与 NAND 之间的新型存储类别。 |
| 3D XPoint | 交叉点相变存储产品 | Intel/Micron 的 PCM 产品,2015 年上市后停产;败因在商业而非技术。 |
| PCM / RRAM / FeRAM / MRAM / FeFET | 相变/阻变/铁电/磁性/铁电晶体管存储 | 各类新兴存储技术,候选填补层次结构空白。 |
| Word Line(WL)/ Bit Line(BL) | 字线/位线 | 阵列的行/列连线,交点即一个存储单元。 |
| Row/Column Decoder | 行/列译码器 | 把 M/N 位地址译码为对应行/列选择信号的外围电路。 |
| Sense Amplifier | 灵敏放大器 | 读出位线上微小信号并放大为逻辑电平的电路。 |
| Write Driver | 写驱动 | 将数据写入选中单元的外围电路。 |
| Charge Pump | 电荷泵 | 片上产生高于电源电压的电路(Flash 写/擦除需要)。 |
| Feature Size(F) | 特征尺寸 | 工艺节点下光刻的理论最小尺寸;单元面积以 F² 计,二维极限 4F²。 |
| SLC / MLC | 单值/多值单元 | 每单元存 1 bit 或 n bit;MLC 使等效位面积除以 n。 |
| Array Efficiency | 阵列效率 | 存储单元面积占(单元+外围电路)面积的百分比;NAND 70–80%、DRAM 60–70%、CPU cache 30–50%。 |
| Peripheral Circuitry | 外围电路 | 存储阵列周边的译码器、灵敏放大器、控制逻辑、电荷泵等支持电路。 |
| Vmin(active/retention) | 最小工作/保持电压 | SRAM 正常读写所需最低电压与仅保持数据所需的更低待机电压。 |
| Power Gating | 电源门控 | 关断空闲模块电源以降低漏电功耗的技术。 |
| SOI FinFET | 绝缘体上硅鳍式场效应晶体管 | IBM/GF 14nm Power9 采用的晶体管工艺。 |
| CPP | 接触多晶硅间距 | 晶体管源漏方向相邻栅极的间距,逻辑密度关键指标(Contacted Poly Pitch)。 |
| Fin Pitch | 鳍间距 | FinFET 相邻鳍的间距。 |
| Standard Cell Track Library | 标准单元轨道库 | 以 Metal-1 走线轨道数定义的标准单元高度(如 6-track)。 |
| LDO | 低压差线性稳压器 | 片上为各模块供电的稳压电路。 |
| 3D V-Cache | 3D 垂直缓存 | AMD 用混合键合在 CPU 基础 die 上方堆叠 64MB SRAM L3 扩展 die 的技术。 |
| Hybrid Bonding(Cu-to-Cu) | 铜-铜混合键合 | 两片 die 以铜垫直接键合的 3D 堆叠工艺,互连开销极小(约 4 个时钟周期延迟)。 |
| SM | 流多处理器 | Nvidia GPU 的基本计算单元(Stream Multiprocessor),A100 含 108 个。 |
| Register File | 寄存器文件 | GPU 每个 SM 内的高速 SRAM 寄存器阵列(A100 为 256 KB/SM)。 |
| Bank / Bank Group | 存储体/存储体组 | DRAM 芯片内部可并行操作的阵列分区单位。 |
| In-DRAM ECC | 片内纠错码 | DRAM 芯片内部自带的错误校验纠正(DDR5 的 RAS 特性)。 |
| DFE / FFE | 判决反馈/前馈均衡 | 高速 IO 信号均衡技术。 |
| Plane | 平面(NAND 分区) | NAND 芯片内可并行操作的阵列分区,128Gb 芯片含 4 个 32Gb plane。 |
| tPROG | 编程时间 | NAND 一次编程操作所需时间(最后一代 2D NAND 为 640 µs)。 |
| Cost per bit | 每比特成本 | 存储产业(尤其 NAND)追求的终极指标。 |
| Teardown | 拆解分析 | 逆向工程公司(如 TechInsights)拆解产品分析元器件与成本的方法。 |