Lecture 2:CMOS 基础与产业格局
1. MOSFET 复习:结构、CMOS 技术与能带图 P1 00:00:43
本讲(Section 2:CMOS Scaling and Industry Trend)分三部分:MOSFET 复习、CMOS 微缩、半导体产业与市场。Part 1 覆盖前两项,Part 2 收尾产业与市场。虽然这是存储器课程,但 CMOS 微缩的逻辑同样支配着存储器技术的发展。
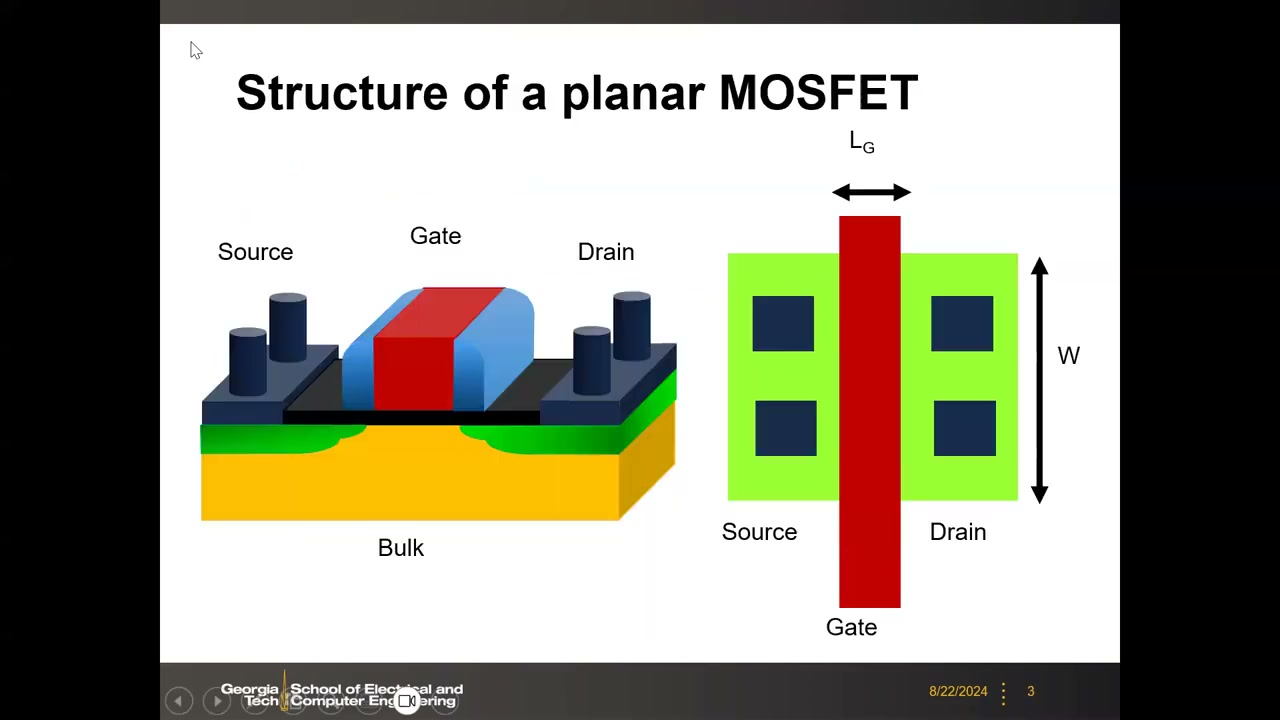
平面 MOSFET 由源(Source)、栅(Gate)、漏(Drain)、衬底(Bulk)构成。从版图(layout)角度看,两个关键尺寸是沟道宽度 W 与沟道长度(栅长)LG——W/L 决定晶体管的电流驱动能力。CMOS 技术要求 NMOS 与 PMOS 共址(collocated):NMOS 直接做在 p 衬底上(n+ 源漏,VG>0 时电子沟道导通),PMOS 则需预先制作 n-well(n 阱)(p+ 源漏,VG<0 时空穴沟道导通)。基本电路单元反相器(inverter)= 1 个 NMOS + 1 个 PMOS;布尔逻辑普遍需要两种管子,这是 CMOS 技术的根本动机。
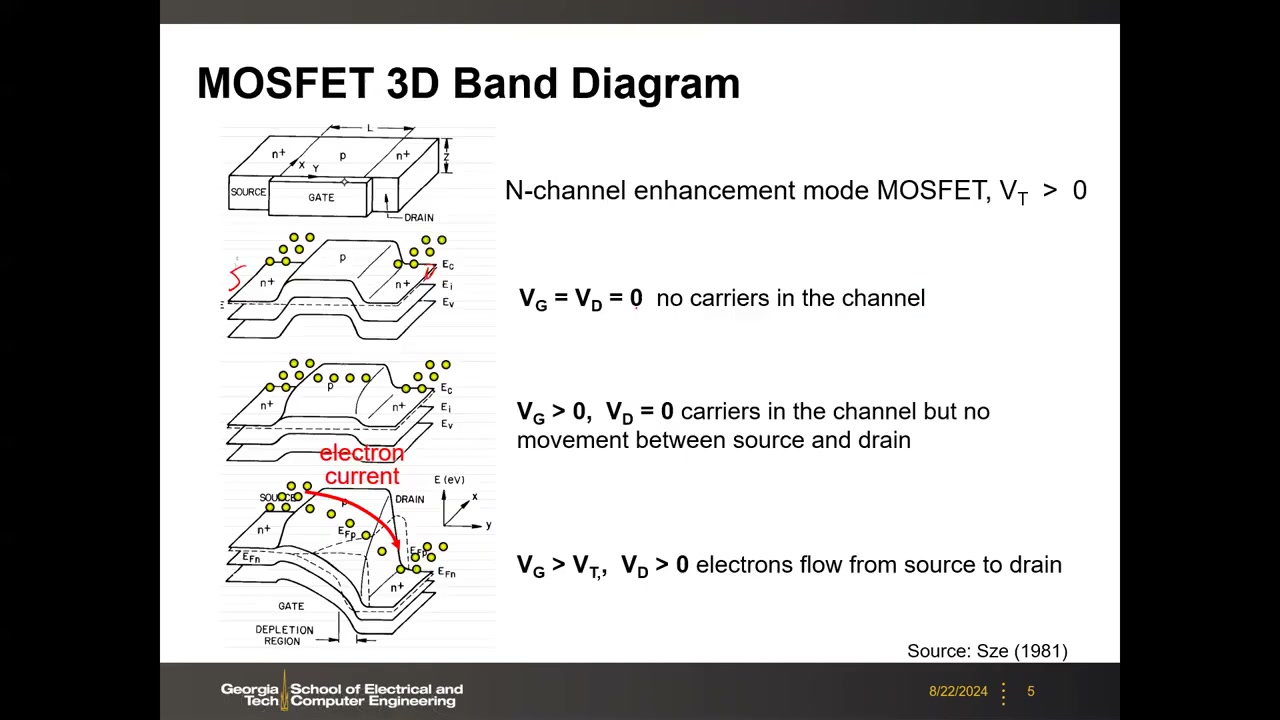
P1 00:01:53 用 3D 能带图(图源 Sze 1981)理解 N 沟道增强型 MOSFET(VT>0)的工作原理,分三种偏置状态:
- VG = VD = 0:源漏 n+ 区有大量电子,但被沟道区较高的势垒(barrier)隔开,沟道内无载流子。
- VG > 0, VD = 0:正栅压使硅表面附近能带下弯,源到沟道的势垒降低,沟道形成反型层(有电子);但源漏等电位,无净电流。
- VG > VT, VD > 0:漏压把漏端能带进一步压低,形成"斜坡"——电子像水一样流向低势能处,产生源→漏电子流。
课堂答疑(P1 00:04:26):为什么 3D 能带图只有一侧下弯?——因为加了漏压后漏侧被进一步压低,沿沟道形成梯度;若 VD=0 则沟道内的弯曲是均匀的。这张能带图是后面理解短沟道效应、band-to-band tunneling 等诸多现象的基础工具。
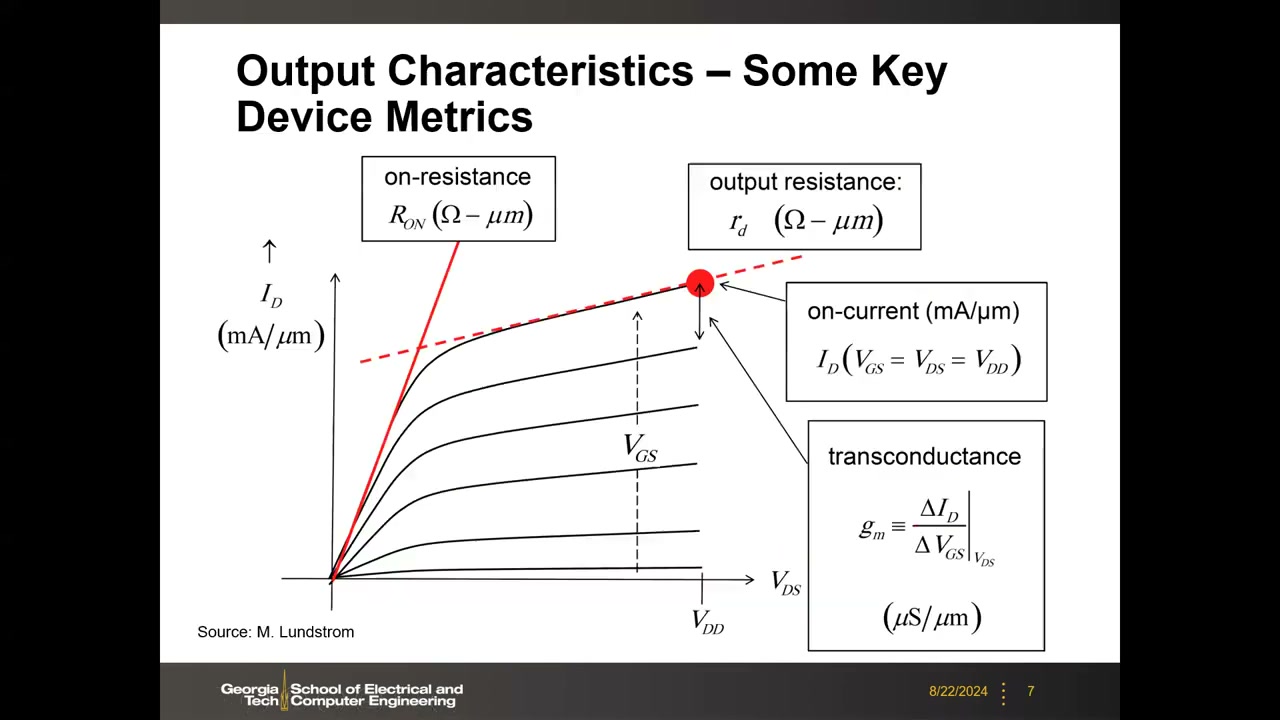
2. I-V 特性与关键器件参数 P1 00:04:09
两类代表性 I-V 曲线:ID-VD(输出特性)——扫描栅压得到一族曲线;ID-VG(转移特性)。关键参数包括阈值电压 VT 与饱和电压 VDSAT(划分线性区/三极管区与饱和区)。注意实际器件中"饱和并不真正饱和":由于短沟道效应与沟道长度调制,饱和区电流仍随 VD 略增。
P1 00:05:59 在输出特性上定义四个关键器件指标(源 M. Lundstrom):
- 导通电阻 RON(Ω·μm):线性区斜率的倒数,此时晶体管近似为一个电阻。
- 输出电阻 rd / ro(Ω·μm):饱和区斜率的倒数(小信号概念),对模拟电路重要——放大器本征增益 = gm × ro。
- 导通电流 Ion(mA/μm):VGS = VDS = VDD 时的最大电流,按栅宽归一化(每 1 μm 宽度多少 mA)。
- 跨导 gm ≡ ΔID/ΔVGS |VDS(μS/μm):栅压变化引起的漏电流变化,模拟设计的核心参数。
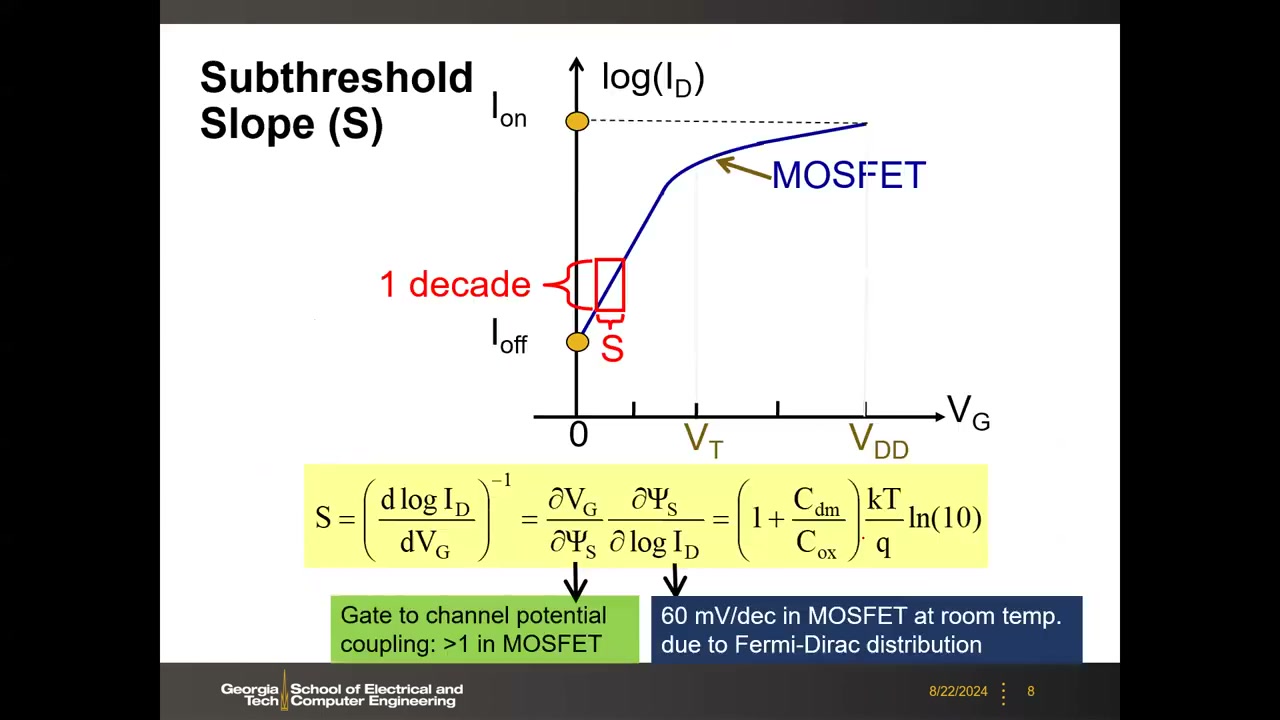
3. 亚阈值斜率 SS 与 60 mV/dec 物理极限 P1 00:08:04
在半对数(log ID vs VG)转移曲线上,VT 以下电流随栅压降低指数衰减。亚阈值斜率 S(或 SS)的单位是 mV/decade——电流降低一个数量级(10 倍)所需的栅压减少量;S 越陡(数值越小)越好。课堂答疑(P1 00:14:22):"decade" 就是电流变化 10 倍。
幻灯片公式(准确转录):
S = (d log ID / dVG)−1 = (∂VG/∂Ψs)·(∂Ψs/∂ log ID) = (1 + Cdm/Cox)·(kT/q)·ln(10)
公式由两个物理来源构成:
- 第一项 ∂VG/∂Ψs:栅-沟道电位耦合。耗尽电容 Cdm 与栅氧电容 Cox 串联分压,栅压不能 100% 传到硅表面电位 Ψs,所以该项 ≥ 1(MOSFET 中恒大于 1)。
- 第二项源于费米-狄拉克统计:kT/q 为热电压,室温约 26 mV;ln(10) ≈ 2.3 是 log10 与自然指数 e 之间的换算因子。两者相乘 ≈ 60 mV/dec。
4. SS 决定 VT 与 VDD 下限:电压微缩为何停滞 P1 00:14:38
SS 为什么如此重要?数字电路要求关断态足够"干净":Ion/Ioff ≥ 105,否则"off 不是真正的 off",仍有漏电。由此可推出电压下限:
- 5 个数量级 × 60 mV/dec ⇒ 最小阈值电压 VT ≈ 300 mV(且这已是最理想情形);当今晶体管 VT 约 300–400 mV。
- VDD 必须显著大于 VT,故当今最低 VDD 约 600 mV。
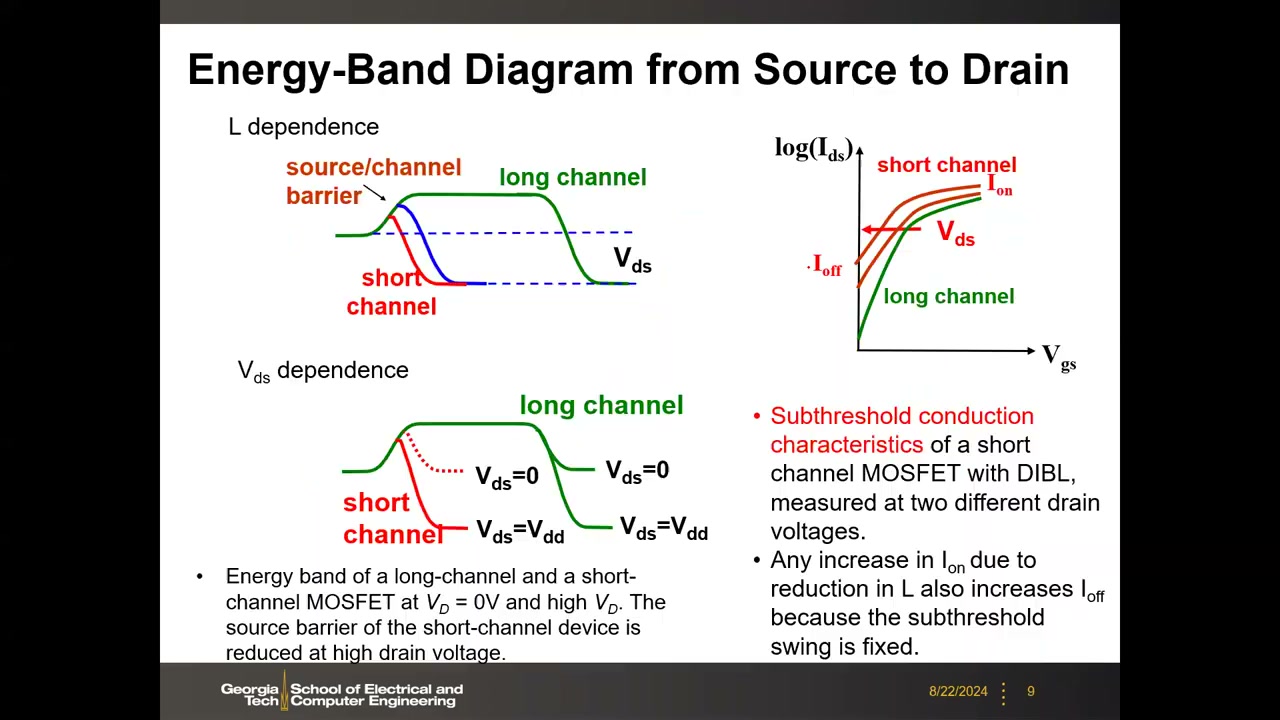
5. 短沟道效应与 DIBL:能带图视角 P1 00:16:50
用源-漏方向的能带图可以同时理解短沟道效应(SCE)的两个方面:
- L 依赖性:沟道过短时漏极离源极太近,源/沟道势垒本身被压低(与长沟道相比),电子容易越过势垒——即使在标称关断态,Ioff 也不再是真正关断,漏电流增大。
- VDS 依赖性(DIBL,漏致势垒降低):长沟道下漏压只压低漏端能带、不影响源端势垒;短沟道下漏压会直接拉低源/沟道势垒,因此 Ioff 随 VDS 升高显著增大。幻灯片展示了短沟道 MOSFET 在两个漏压下测得的亚阈值导电特性——曲线整体平移。
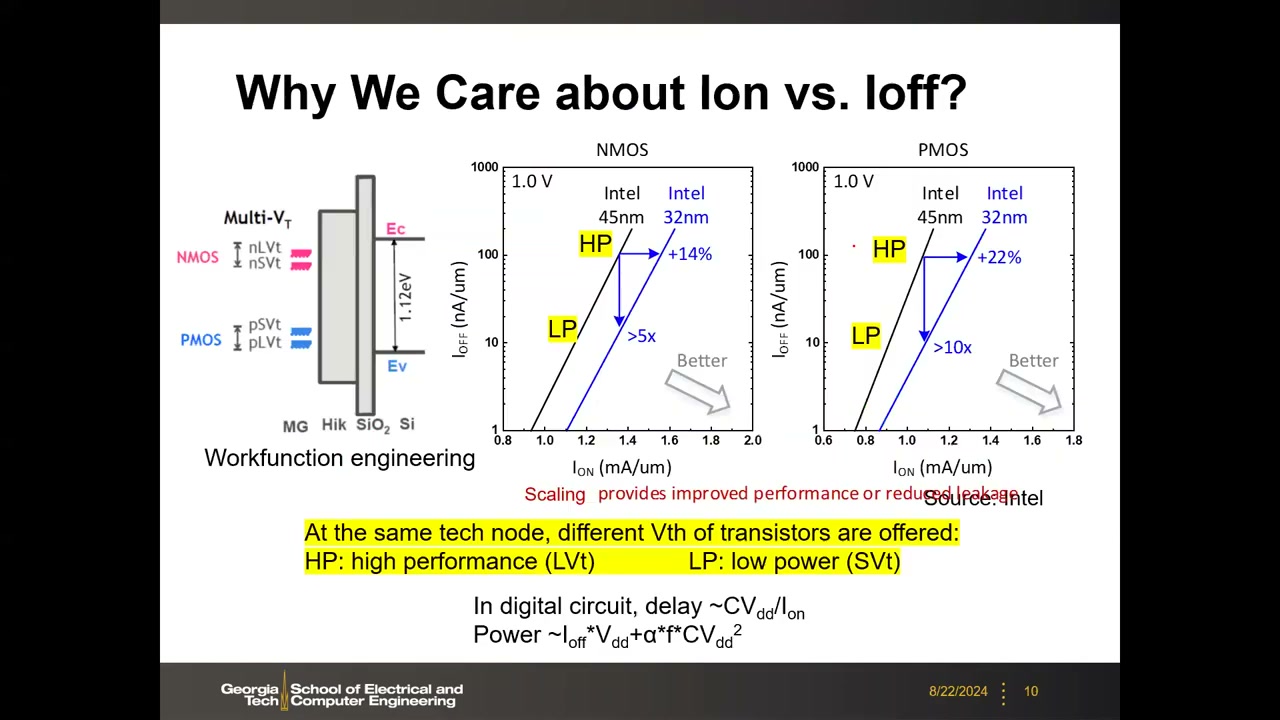
6. Ion vs Ioff 设计空间与多 VT / 功函数工程 P1 00:18:24
以 Intel 45 nm → 32 nm 实测数据为例(坐标:Ion (mA/μm) vs Ioff (nA/μm,对数轴),VDD = 1.0 V),微缩把整个 Ion-Ioff 包络推向右下("Better")方向。定量收益:
- 固定 Ioff 时:NMOS Ion +14%、PMOS Ion +22%;
- 固定 Ion 时:NMOS Ioff 降 >5×、PMOS 降 >10×。
为什么关心这两个量?数字电路的一阶近似:delay ~ C·VDD/Ion(Ion 越大越快);Power ~ Ioff·VDD + α·f·C·VDD²(静态漏电 + 动态功耗,α 为活动因子,f 为时钟频率)——降低 Ioff 直接降低待机漏电功耗。
同一技术节点会提供多种 VT 的晶体管:HP(高性能,低 VT)与 LP(低功耗,标准/高 VT);幻灯片标注了 nLVt/nSVt(NMOS)、pSVt/pLVt(PMOS),并以 Si 带隙 1.12 eV 作示意。VT 的调节依靠功函数工程(workfunction engineering):现代晶体管均为金属栅(MG/High-k/SiO₂/Si 叠层),选用不同费米能级(功函数 = 费米能级到真空能级的距离)的栅金属即可调 VT,无需改变其他工艺。
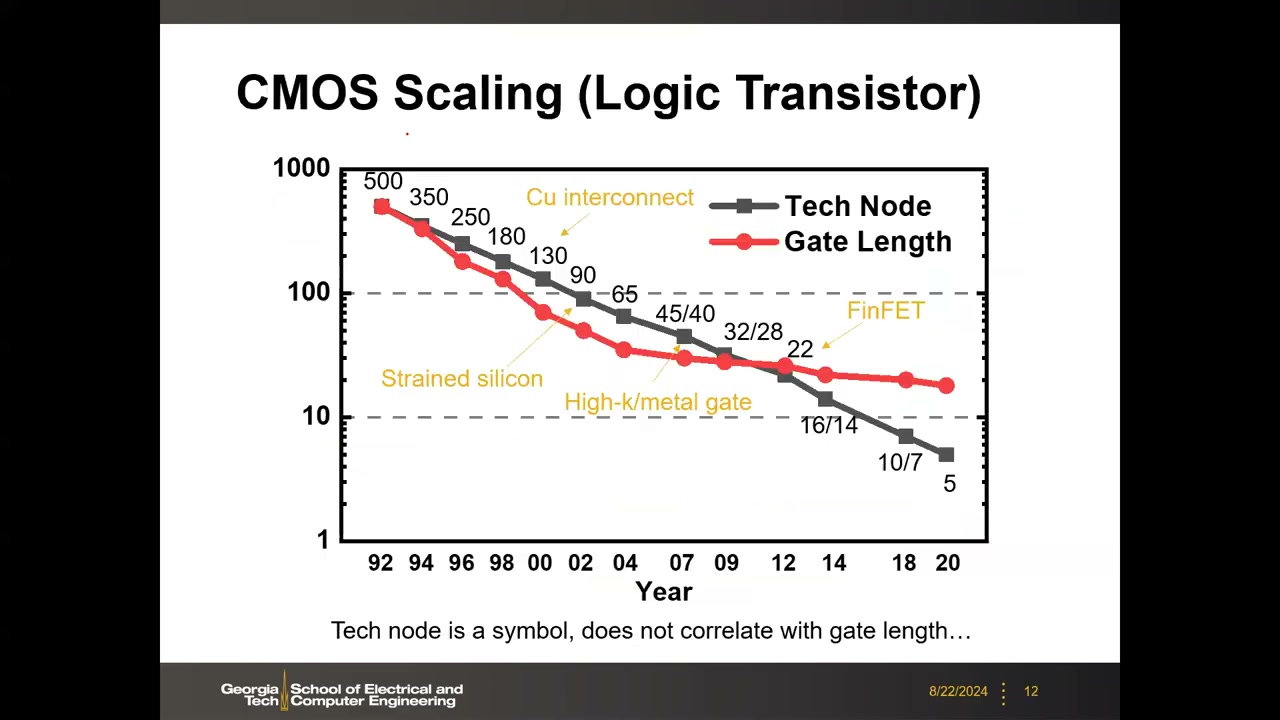
7. CMOS 微缩历史:技术节点 ≠ 栅长 P1 00:22:02
教授展示了自己收集的 20–30 年历史数据(横轴 1992–2020)。节点序列:500→350→250→180→130→90→65→45/40→32/28→22→16/14→10/7→5 nm。其间的关键创新里程碑:130 nm Cu 互连(替代铝互连)、90 nm 应变硅、45 nm high-k/metal gate、22 nm FinFET。
节点数字与物理栅长的关系经历三个阶段:老时代(约 >250–300 nm,1970s–80s)两者一致;250 nm 之后栅长微缩一度加速(利用源漏向沟道内扩散,使物理栅长小于光刻/版图栅长);而到如今 5 nm/3 nm 节点的物理栅长停在约 15–16 nm,与节点数字完全脱钩。
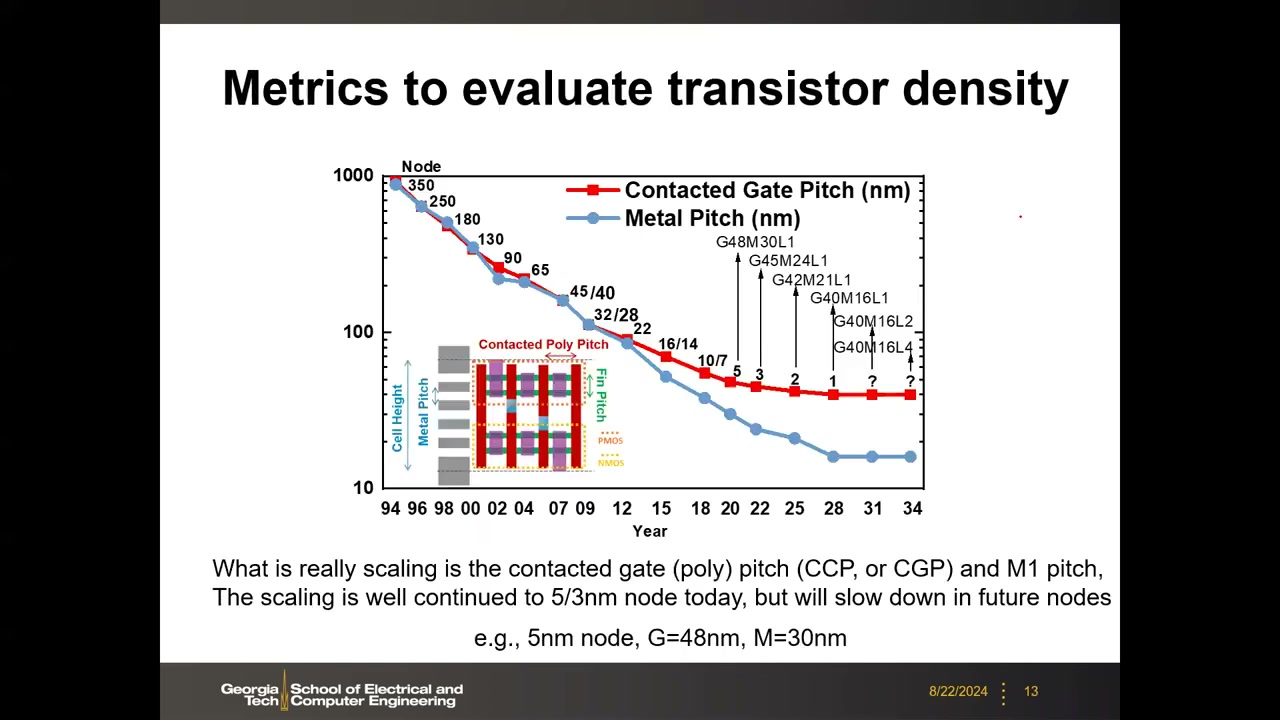
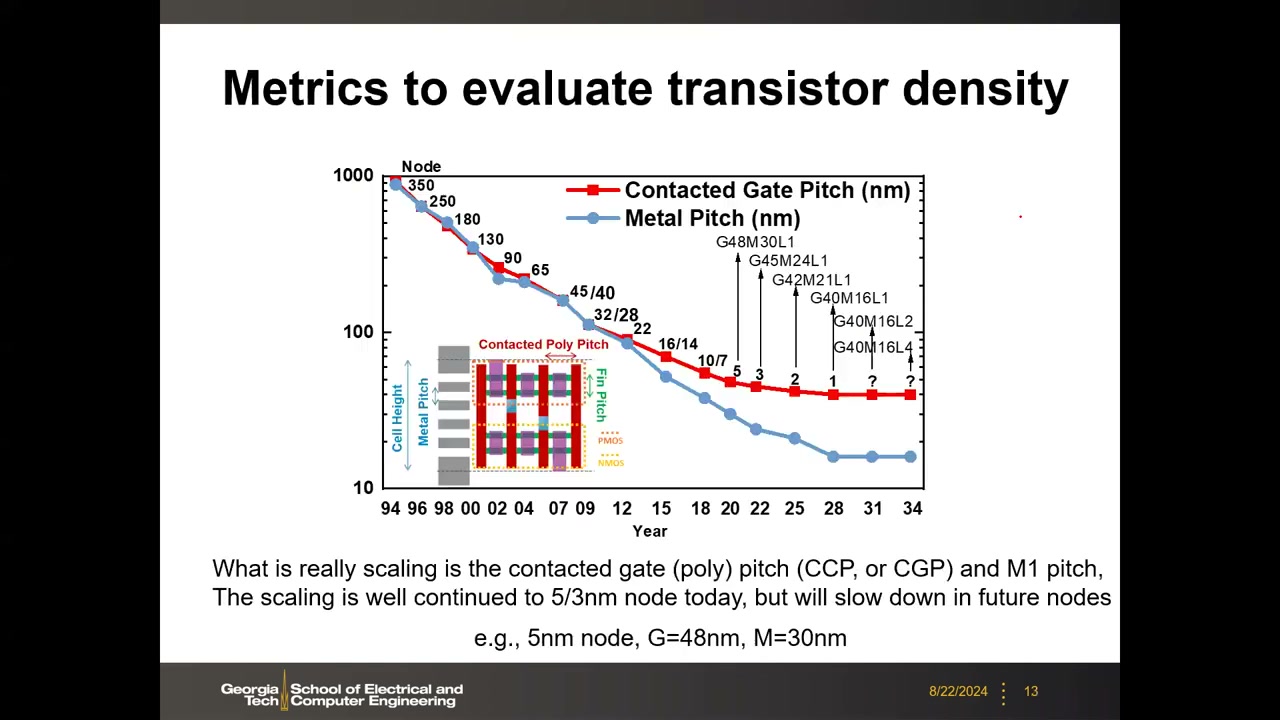
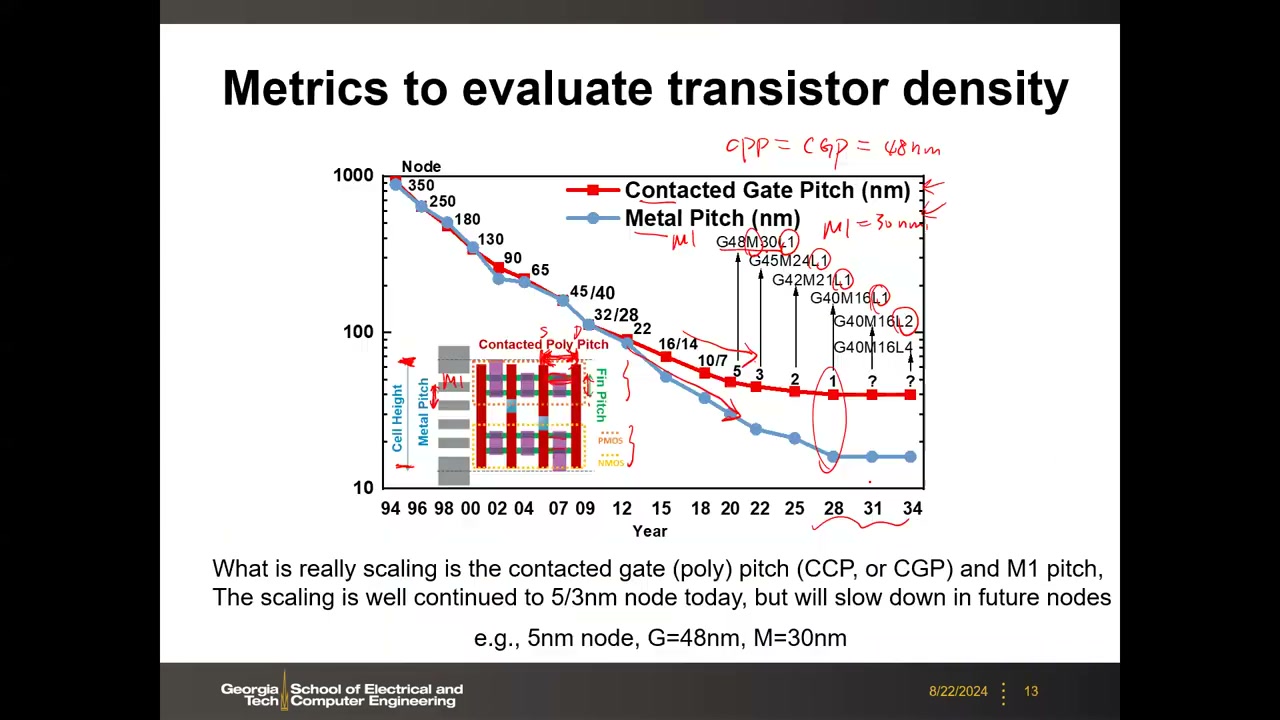
8. 真正的微缩指标:CPP/CGP 与 M1 Pitch P1 00:25:39
摩尔定律仍在继续,但微缩的不是物理栅长,而是标准单元(inverter/NAND/NOR 等)的面积,由两个版图指标决定:
- 水平方向:接触多晶/栅间距 CPP = CGP(Contacted Poly/Gate Pitch)——源接触中心到漏接触中心的距离(旧称 poly 因栅曾是多晶硅,现已是金属栅)。
- 垂直方向:M1 金属间距(Metal-1 Pitch),单元高度 = 金属轨道数 × M1 pitch。
数据显示 CPP 与 M1 pitch 持续微缩到 5/3 nm 节点(M1 微缩更快,CPP 略放缓),未来将放缓。例:5 nm 节点 G48M30L1 = CGP 48 nm、M1 30 nm、单层(L1)。命名序列 G48M30L1、G45M24L1、G42M21L1、G40M16L1、G40M16L2、G40M16L4 中,L1 = 单层 2D 设计;L2/L4 = 未来 3D 堆叠(CFET 或多层晶体管垂直堆叠),属于产业预测。课堂答疑(P1 00:29:54):从版图角度,GAA 纳米片与 FinFET 没有区别,CPP/M1 pitch 的定义不变,只是按设计规则继续缩。
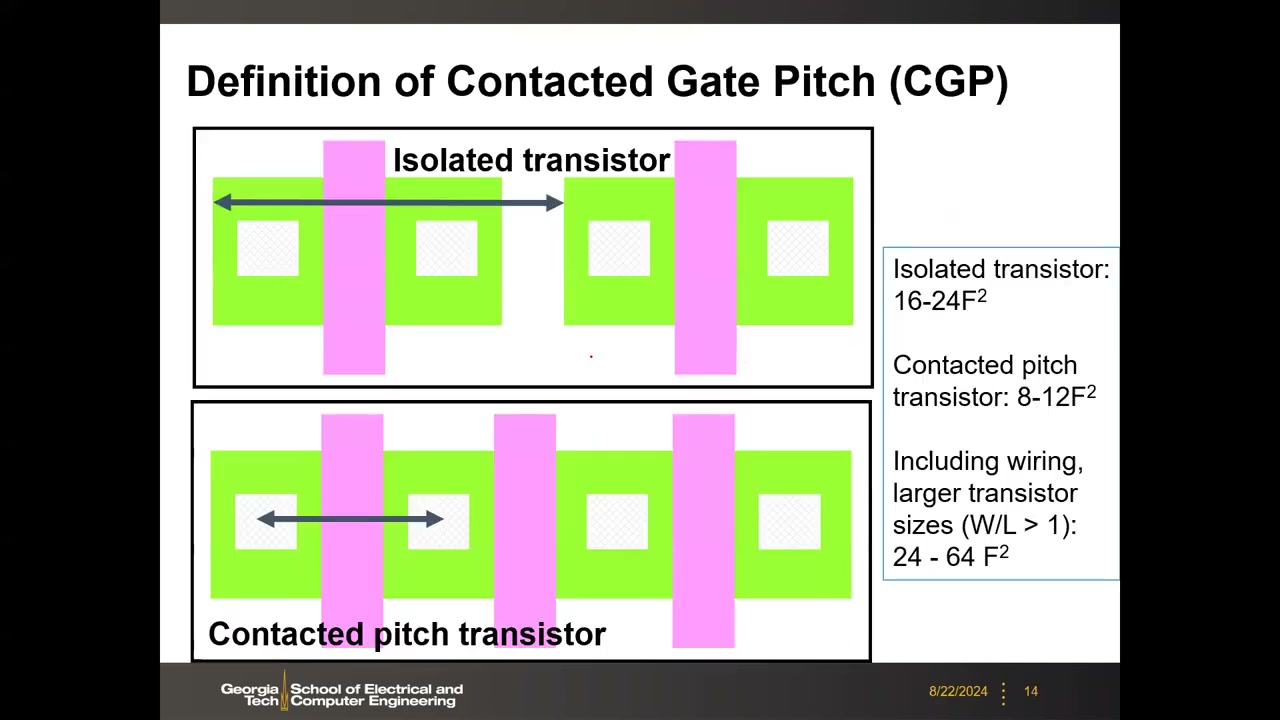
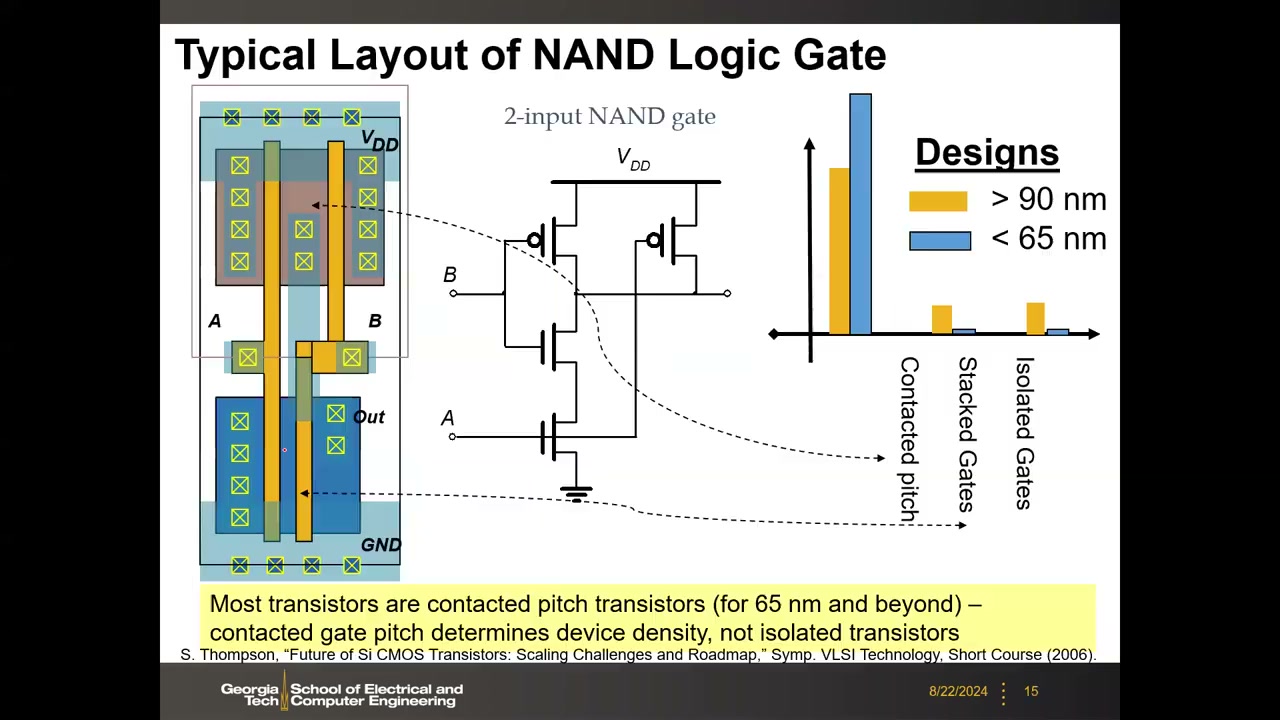
P1 00:30:32 CGP 的定义与单管面积(以 F² 计量):孤立晶体管(isolated)16–24 F²;接触间距晶体管(contacted pitch)8–12 F²;考虑布线及较大尺寸(W/L>1)时为 24–64 F²。P1 00:31:29 的 2 输入 NAND 版图实例(引 S. Thompson, Symp. VLSI Tech. Short Course 2006):两个 NMOS 串联(中间无需接触孔),两个 PMOS 并联(中间必须加接触孔,故占两个 contact pitch)。统计对比(>90 nm vs <65 nm 设计)表明:65 nm 及以后绝大多数晶体管是 contacted pitch 晶体管——决定器件密度的是接触栅间距,而非孤立晶体管。
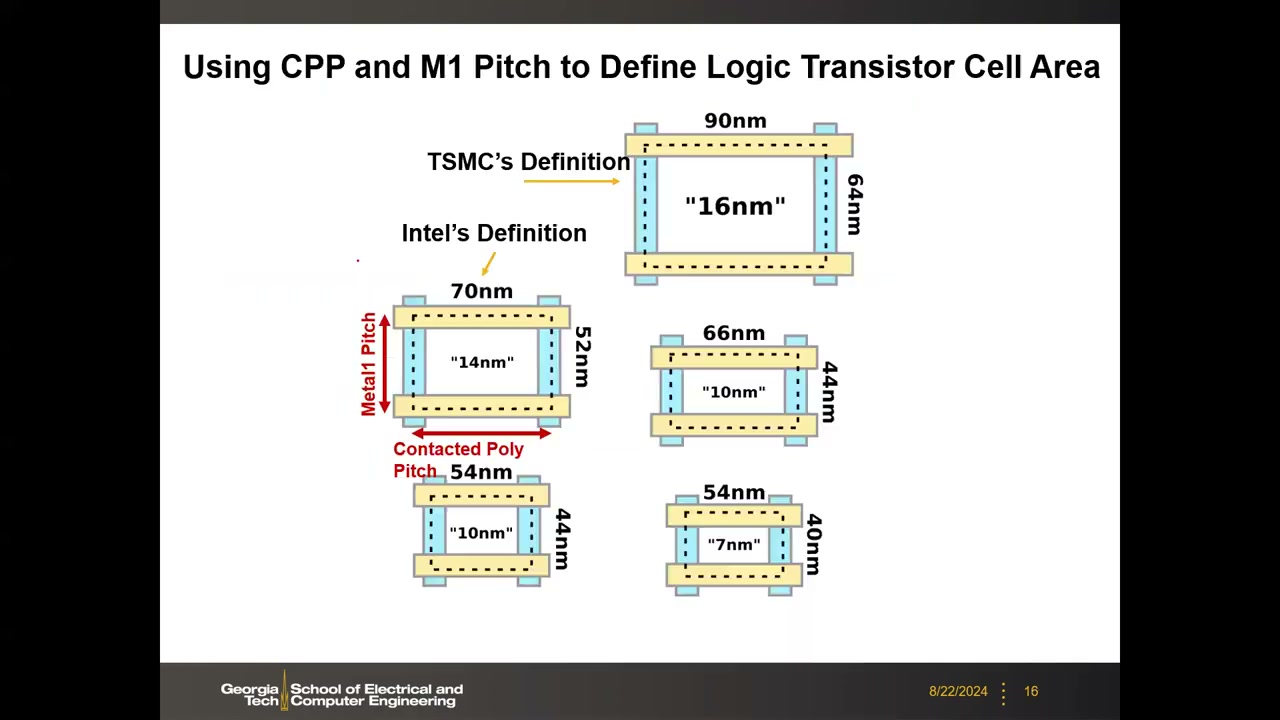
9. 标准单元面积:TSMC vs Intel 命名差异与鳍减除 P1 00:32:23
用 CPP × M1 pitch 定义逻辑晶体管单元面积,可以横向对比各厂同名节点的真实设计规则:
| 厂商"节点名" | CPP(nm) | M1 pitch(nm) |
|---|---|---|
| TSMC "16nm" | 90 | 64 |
| Intel "14nm" | 70 | 52 |
| TSMC "10nm" | 66 | 44 |
| Intel "10nm" | 54 | 44 |
| TSMC "7nm" | 54 | 40 |
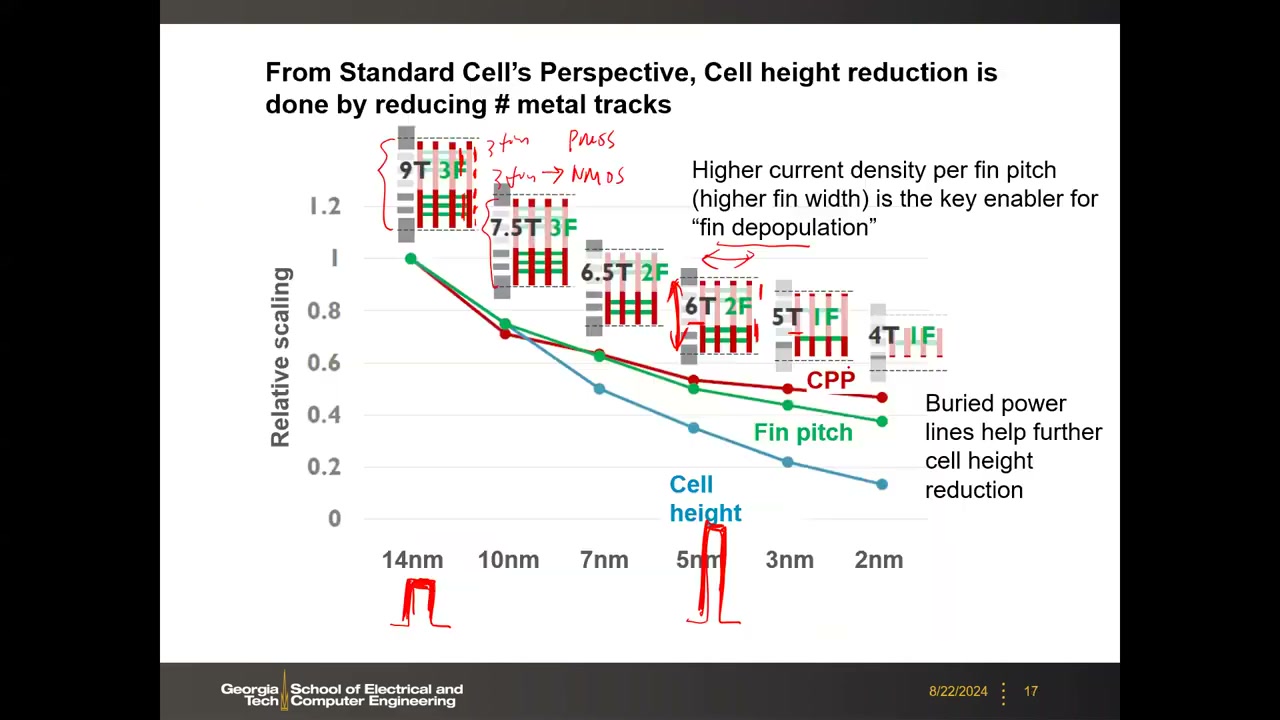
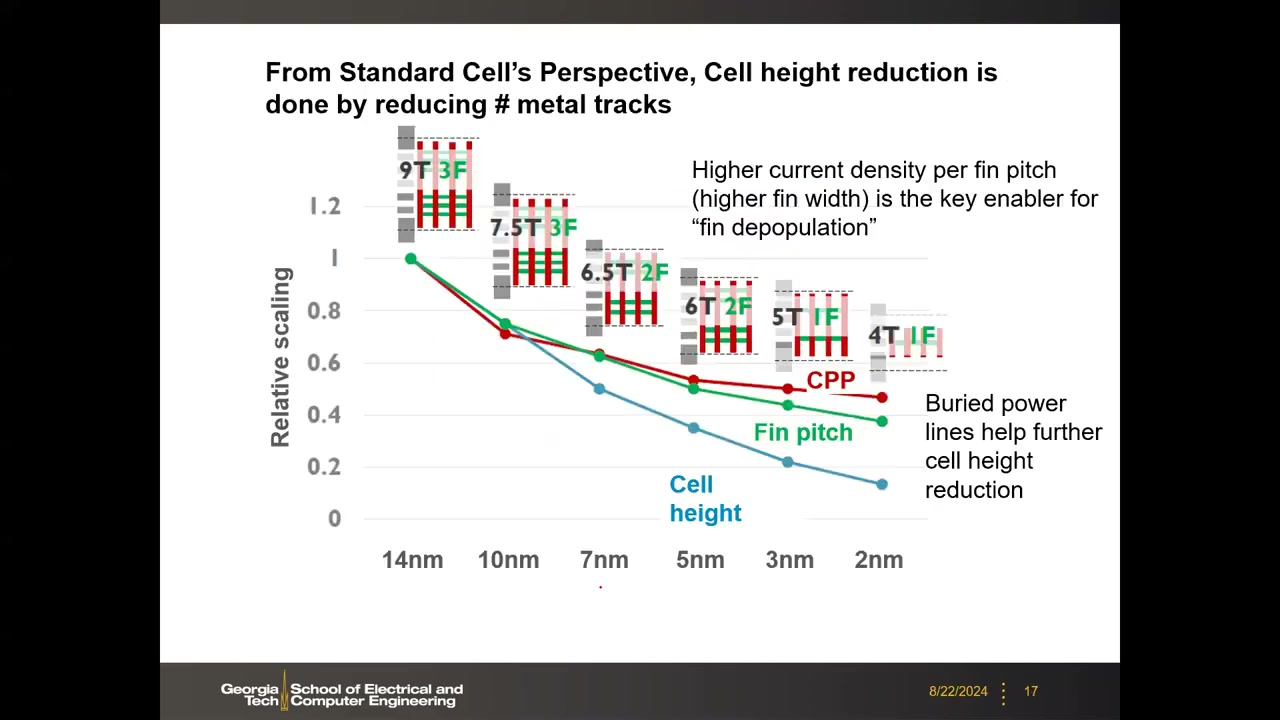
P1 00:34:04 未来 CPP 微缩将饱和、M1/fin pitch 微缩放缓,但晶体管密度仍能提升——靠降低单元高度:减少金属轨道数(metal tracks)和 NMOS/PMOS 的鳍数(fin depopulation,鳍减除):
| 节点 | 14 nm | 10 nm | 7 nm | 5 nm | 3 nm | 2 nm |
|---|---|---|---|---|---|---|
| 单元高度(轨道数 × 鳍数) | 9T 3F | 7.5T 3F | 6.5T 2F | 6T 2F | 5T 1F | 4T 1F |
原理:40 nm 时代 NMOS/PMOS 各需 3 个鳍才能提供满足时序要求的电流;FinFET 节点演进中每个鳍变得更高更薄、侧壁导电,每鳍电流密度更高(higher current density per fin pitch)是 fin depopulation 的关键使能因素——5/3 nm 只需 2 鳍甚至 1 鳍。这是当前维持摩尔定律的主要驱动力。课堂答疑补充(P1 00:40:30):标准单元还包含 VDD/VSS 电源轨,占用面积;背面供电(backside power delivery / buried power lines)把电源轨藏到硅片背面,可进一步降低单元高度,预计在 2 nm/1 nm 节点引入。
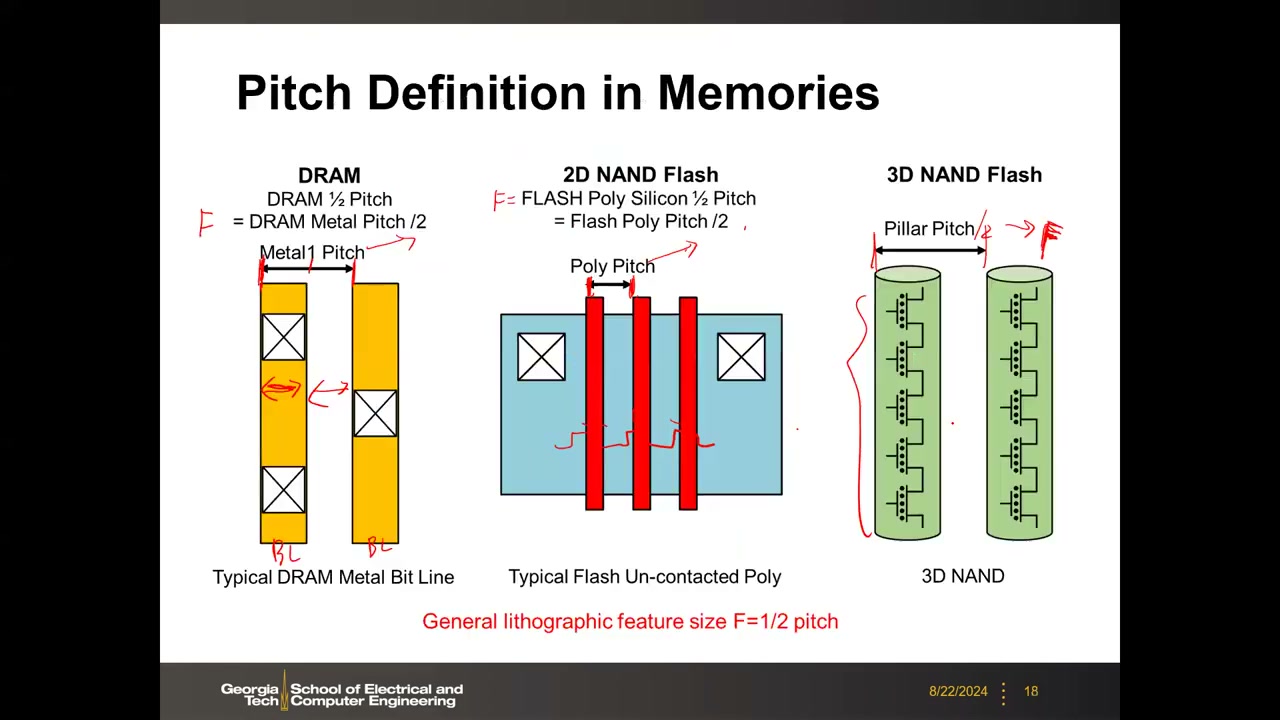
10. 存储器中的 pitch / F 定义 P1 00:36:59
教授打趣说"存储器同行更诚实"——存储器的特征尺寸 F 有明确定义:一般取光刻 pitch 的一半(F = 1/2 pitch)。具体到各类存储器:
- DRAM:F = 金属(位线 M1)pitch 的一半(金属线宽 + 间隔的一半)。
- 2D NAND Flash:F = 多晶硅栅 pitch 的一半(串联晶体管栅到栅的 pitch,未接触 poly)。
- 3D NAND:可勉强用柱间距(pillar pitch)之半定义 F,但该值远大于 2D NAND 的 F;真正重要的是堆叠层数,业界已不再谈 F。课堂答疑(P1 00:41:08):3D NAND 柱间距大约 100–120 nm 量级,可能 90–100 nm,未必降到 100 nm 以下。
11. 微缩技术路线:应变硅 → HKMG → FinFET → 纳米片 → CFET P1 00:41:41
沿时间轴(90 nm → 45 nm → 22 nm → 3 nm)的四代关键创新:
- 90 nm 应变硅(strained silicon):用 SiGe 源漏(PMOS 单轴压应变)/张应力 Si₃N₄ 帽层(NMOS 单轴张应变)改变晶体结构、提升载流子迁移率。
- 45 nm high-k/metal gate(HKMG):解决栅漏电问题。
- 22 nm FinFET:三维鳍结构,对抗短沟道效应。
- 3 nm 及以后:堆叠纳米片(stacked nanosheet)。Samsung 已在 3 nm 量产,称 GAA MBCFET(Multi-Bridge-Channel FET);Intel 叫 nanoribbon;TSMC 与 Intel 计划在 N2 / 18A 节点转向纳米片。GAA = gate-all-around(全环绕栅)。
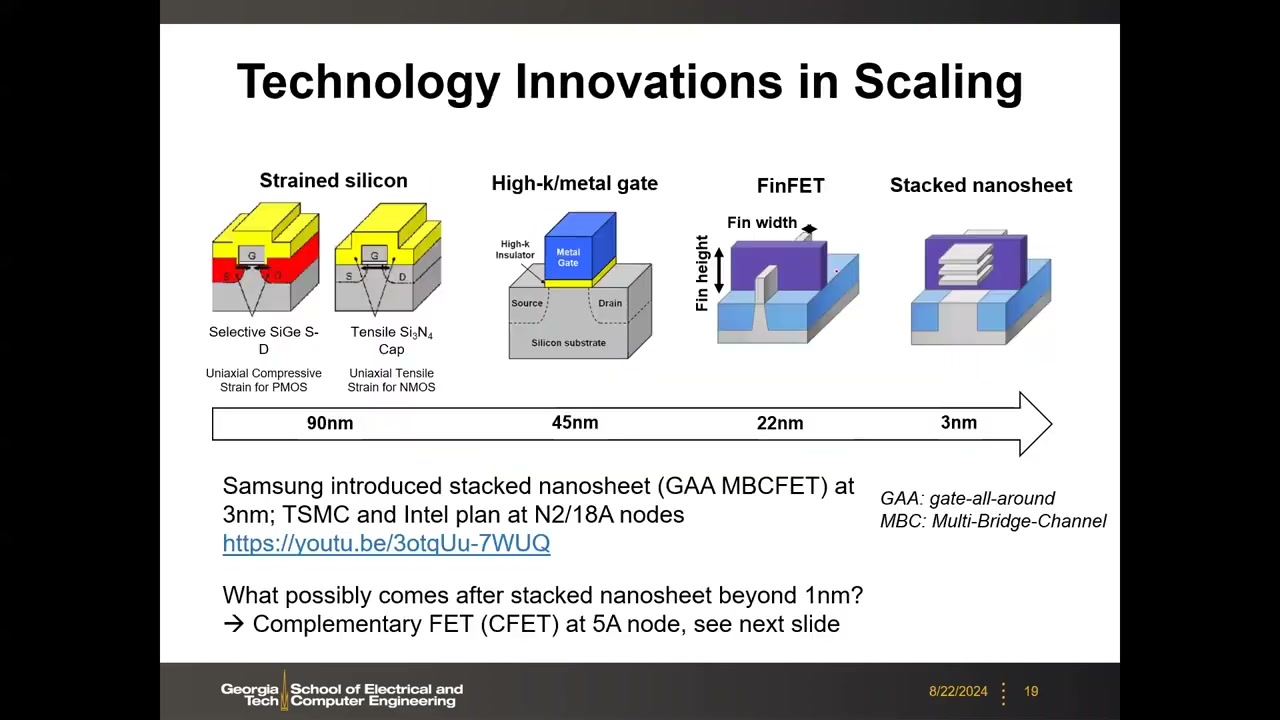
P1 00:43:04 纳米片之后是 CFET(Complementary FET,互补场效应晶体管):标准单元中 NMOS 与 PMOS 原本左右/上下并排占面积,CFET 把 NMOS 垂直堆叠在 PMOS 之上(自对准堆叠纳米带)。Intel 在 IEDM 2020 已有早期演示论文——TEM 剖面中纳米带宽约 13 nm、NMOS/PMOS 间距约 50 nm。产业路线图把 CFET 定位在 5 Å(5A)节点,约 7–8 年后实现;这是目前业界能看到的逻辑微缩终点。

P1 00:44:10 最后展望"原子世界"(源 Applied Materials / imec):纳米片尺寸仅 2–4 nm,原子已可数;GAA 结构横截面包含 超过 5 种材料,每层仅 1–2 nm 厚,需要原子级工艺——"每个原子层、每个界面都重要"。未来 5–10 年逻辑微缩仍会继续直到 CFET;之后前道(FEOL)CMOS 尚无方案,只能依靠异质 3D 堆叠/芯片键合(chip-to-chip bonding),那可能是 10 年以后的事。

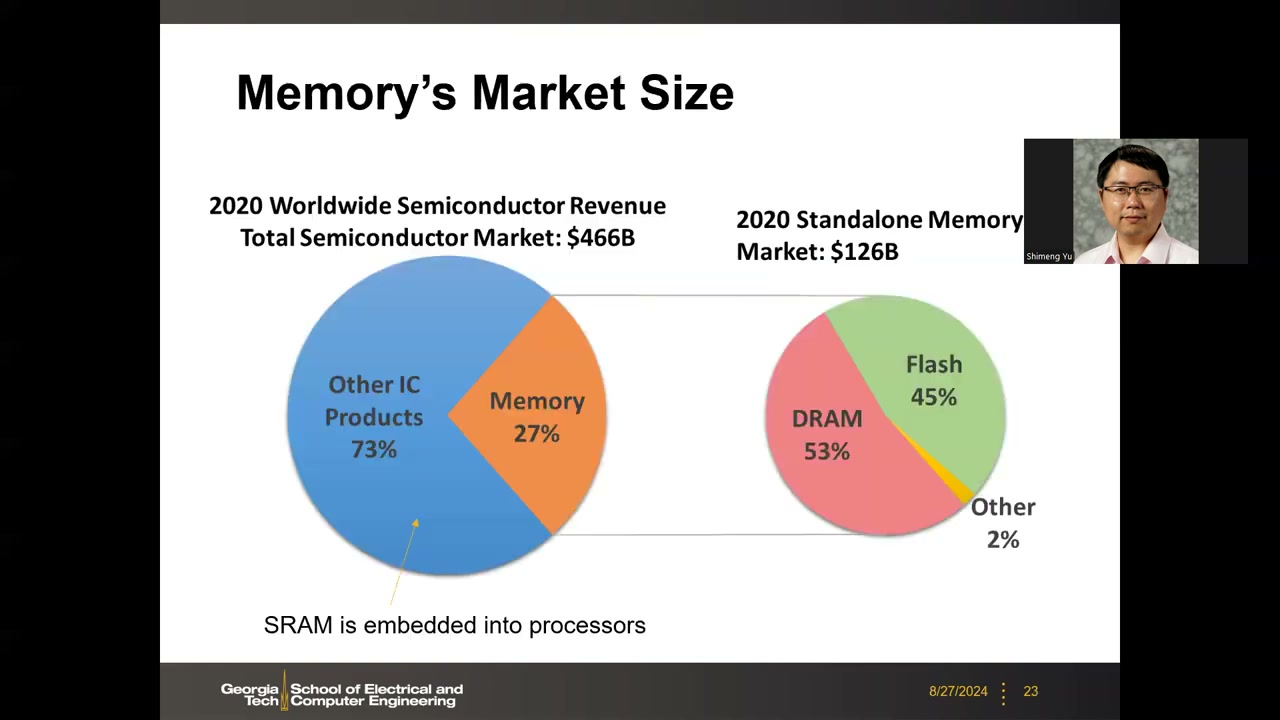
12. 存储器市场规模 P2 00:00:21
Part 2 进入大纲第三项"半导体产业与市场"。2020 年全球半导体总收入约 $466B(4660 亿美元);教授补充:当年(2024)估计已超过 $500B 甚至 $600B,是一个巨大的市场。市场拆分:
| 层级 | 构成 | 占比 / 规模 |
|---|---|---|
| 全球半导体(2020,$466B) | 独立(standalone)存储器 | 27%(约 $126B) |
| 其他 IC 产品 | 73% | |
| 独立存储器内部($126B) | DRAM | 53% |
| Flash | 45% | |
| 其他(Other) | 2% |
这是全课程"为什么要学存储器"的市场层面论据——存储器约占半导体市场四分之一强,且 DRAM 与 Flash 大致各占一半,是产业支柱。
13. 半导体产业模式:Foundry / Fabless / IDM / 系统集成商 P2 00:01:46
- Foundry(代工厂):只做制造,为设计公司代工。代表:TSMC、GlobalFoundries、UMC、SMIC 等。TSMC 占代工市场份额超过 60%,处于绝对主导;GlobalFoundries、UMC、SMIC 属第二、第三梯队。
- Fabless(无晶圆厂设计公司 / design house):只做设计,把版图交给代工厂制造。代表:AMD、NVIDIA、Qualcomm、Broadcom、MediaTek 等。须与代工厂紧密合作,常共同做 DTCO(Design-Technology Co-Optimization,设计-工艺协同优化)。
- IDM(整合器件制造商):设计 + 制造一体,曾是主流模式,如今越来越少。代表:Intel、Samsung。
- Intel 是最大的 IDM;近期推行"IDM 2.0"战略:实质上拆分为两部分——Intel Foundry 对外接其他客户订单,同时 Intel 也把自家设计交给其他代工厂制造(例如 Intel 最新处理器由 TSMC 制造)。
- Samsung 也是 IDM("什么都做");Samsung Foundry 是全球第二大代工厂,市场份额约 15–16%,但 Samsung 的主要营收来自存储器业务。
- 存储器公司(归入 IDM 类):独立存储器(DRAM、NAND Flash)的主要厂商——Samsung、SK Hynix、Micron(三家同时供应 DRAM 和 NAND Flash),Western Digital 与 Kioxia(只做 NAND Flash)。
- 汽车电子(归入 IDM 类):设计与制造一体,因为常有特殊工艺。代表:TI、NXP、ST Microelectronics、Renesas(日本)等。
- System Integrator(系统集成商):越来越多系统/软件/互联网公司自研定制芯片——Apple(自有 silicon)、Google、Meta,还有 Tesla、Amazon、Microsoft 等都在该领域招人。
- EDA 厂商(幻灯片未列,教授口头补充):整个生态的使能者(enabler),如 Cadence、Synopsys、Mentor Graphics。

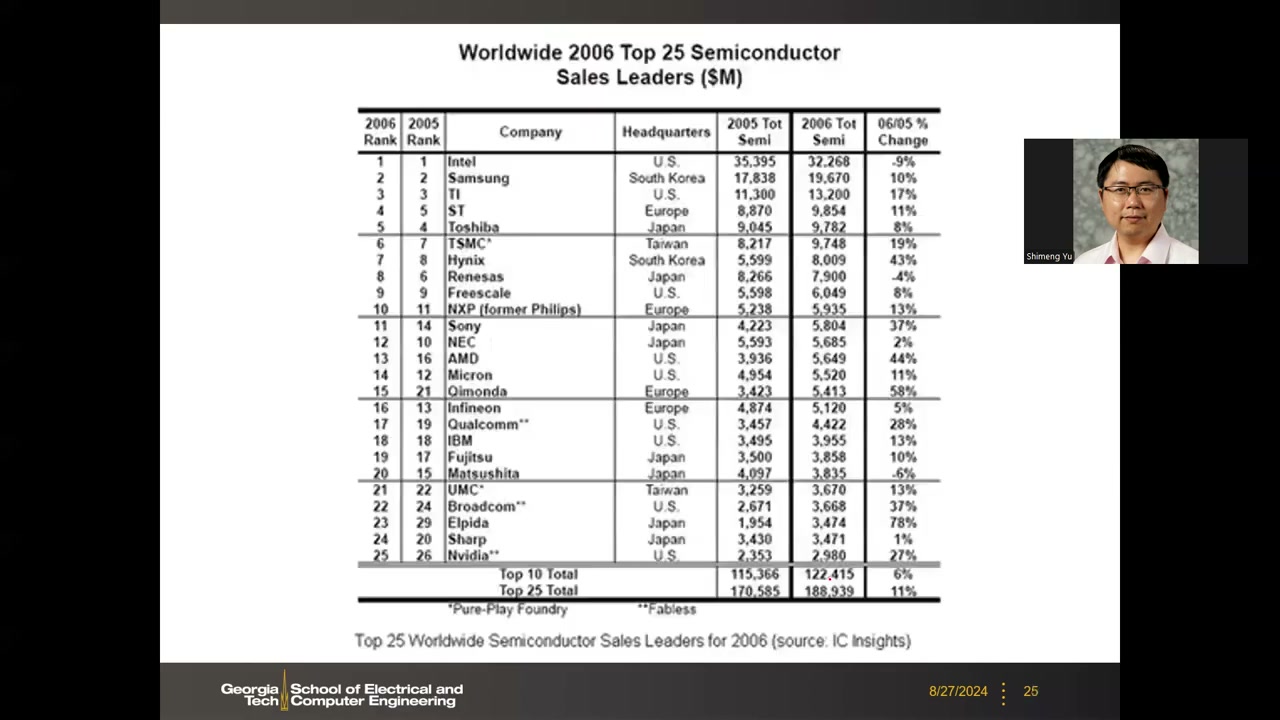
14. 历史营收排名演变(2006 → 2023) P2 00:07:35
教授用 7 个年份的全球半导体营收排名表(来源 IC Insights / TechInsights,含代工厂)展示近 20 年的产业格局变迁。各年要点重排如下:
| 年份 | 前几名(营收,$M) | 格局看点 |
|---|---|---|
| 2006 P2 00:07:35 |
1 Intel(32,268)· 2 Samsung(19,670)· 3 TI · 4 ST · 5 Toshiba · 6 TSMC(9,748)· 7 Hynix · 8 Renesas · 9 Freescale · 10 NXP | 传统 IDM 主导时代的基准年。Top 10 合计 $122,415M,Top 25 合计 $188,939M(+11%)。NVIDIA 仅第 25($2,980M)、AMD 第 13、Qualcomm 第 17;NEC(后并入 Renesas)、Freescale(后被 NXP 收购)今已不存。 |
| 2010 P2 00:08:33 |
1 Intel(40,095,+24%)· 2 Samsung(32,677,+54%)· 3 Toshiba · 4 TSMC(13,072,+45%)· 5 TI | TSMC 快速爬升(第 6→第 4);Qualcomm 首进前十(第 10,$7,098M)——手机业务起点。存储器公司:Hynix 第 7(+68%)、Micron 第 9(+69%)、Elpida 第 11(+75%)。Top 20 合计 $213,601M(+35%)。 |
| 2014 P2 00:09:25 |
1 Intel(51,368)· 2 Samsung(37,259)· 3 TSMC(25,088,+26%)· 4 Qualcomm(19,100)· 5 Micron+Elpida(16,614) | TSMC 跃居第 3;Qualcomm 处于智能手机巅峰期的顶点;Micron 收购 Elpida 后跃升至第 5;SK Hynix 首进前十(第 6,$15,838M,+22%)。当时排名靠后的:MediaTek 第 12、AMD 第 15($5,512M)、NVIDIA 第 20($4,237M)。 |
| 2016 P2 00:10:34 |
1 Intel(56,313)· 2 Samsung(43,535)· 3 TSMC(29,324)· 4 Qualcomm · 5 Broadcom | 格局变化不大;存储器表现不错:SK Hynix 第 6($14,234M)、Micron 第 7($12,842M)。NVIDIA 跃升至第 16($6,340M,+35%);Apple 出现在第 14($6,493M)——自用定制处理器,由 TSMC/Samsung 代工。 |
| 2018 P2 00:11:02 |
1 Samsung(83,258,+26%)· 2 Intel(70,154)· 3 SK Hynix(37,731,+41%)· 4 TSMC(34,209)· 5 Micron(31,806,+33%) | 存储器超级周期:Samsung 首次超过 Intel 登顶,SK Hynix 升至第 3、Micron 第 5。NVIDIA 首进前十(第 10,$12,896M,+37%);Qualcomm 开始下滑(第 7,-3%)。Top 15 合计 $381,160M(+18%)。 |
| 2020 P2 00:11:36 |
1 Intel(73,894)· 2 Samsung(60,482)· 3 TSMC(45,420,+31%)· 4 SK Hynix(26,470)· 5 Micron(21,659) | 前两名回到 Intel/Samsung——教授评论:过去 20 年第一、第二基本总是这两家。NVIDIA 升至第 8($15,884M,+50%);MediaTek 第 11(+35%)、Kioxia 第 12、Apple 第 13、AMD 第 15(+41%)。 |
| 2023 P2 00:12:06 |
1 TSMC(68,852,-9%)· 2 Intel(51,401,-16%)· 3 NVIDIA(49,565,+102%)· 4 Samsung(48,304,-37%)· 5 Qualcomm | 格局巨变(2024 未结束,2023 为最新):TSMC 登顶;Intel 近况不佳;NVIDIA 营收翻倍(对应近年股价暴涨);Samsung 受存储器下行周期拖累。SK Hynix 第 7($23,922M)、AMD 第 8($22,612M)、Micron 第 13(-37%)。Top 25 合计约 $516,827M(约 -11%)。 |
教授特别声明:列出排名"不评判公司优劣,这是历史告诉你的"。
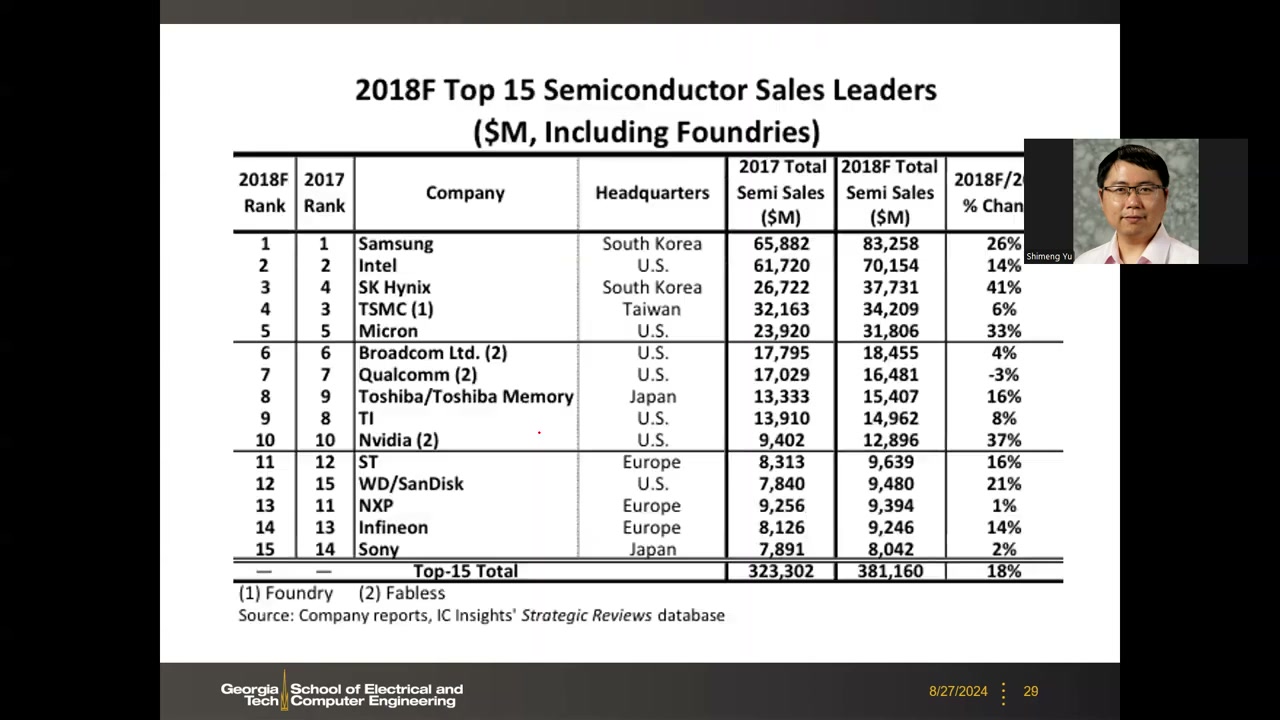
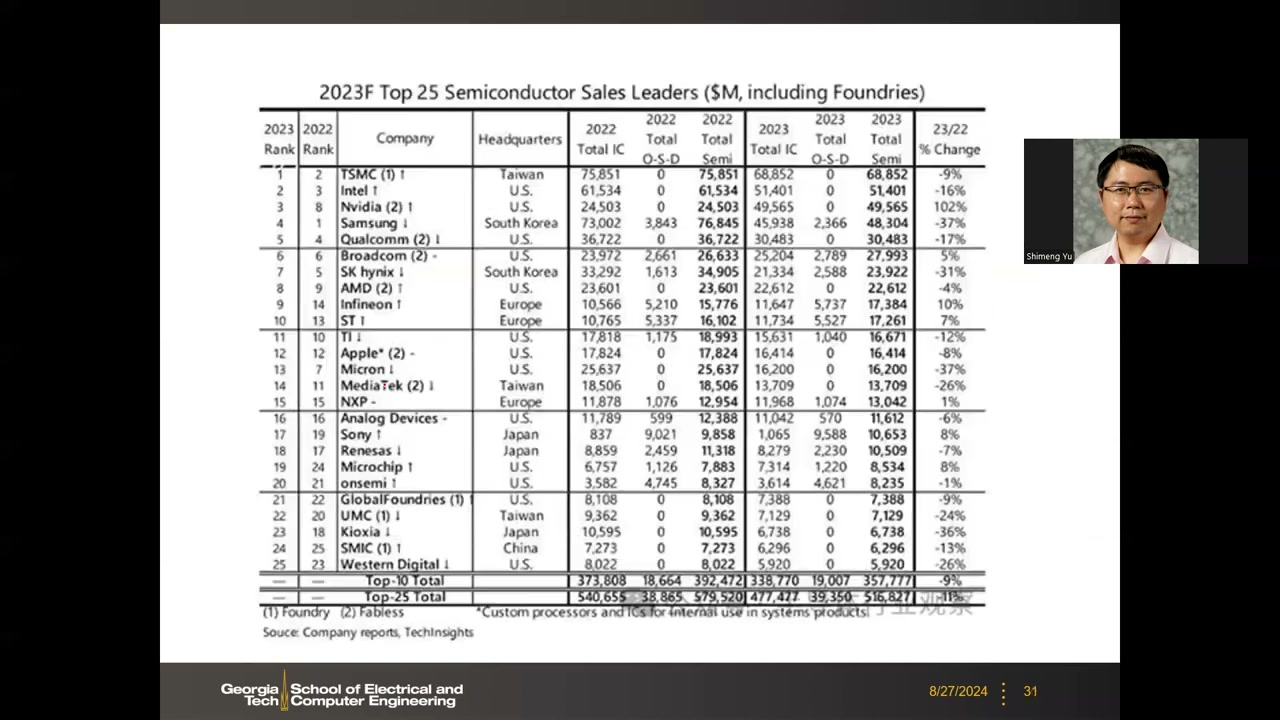
15. 存储器公司的地位与 HBM P2 00:13:15
存储器公司在 Top 10 中占据可观席位:Samsung 的营收主要来自存储器(其 Foundry 营收与存储器相比微不足道);此外还有 Micron 和 SK Hynix。SK Hynix 近年表现尤其好的原因是 HBM(高带宽存储器):NVIDIA 与 SK Hynix 有独家协议(exclusive agreement),NVIDIA GPU 的 DRAM(HBM)全部来自 SK Hynix,SK Hynix 因此大幅受益于 AI/GPU 浪潮。这直接呼应本课程主题——存储器(特别是 DRAM/HBM)是当前 AI 硬件浪潮的核心受益环节。
P2 00:13:59 全节 Summary(幻灯片第 32 页)收尾整个 Section 2,六条结论见下方"本讲要点总结";视频在约 15:45 结束。

本讲要点总结
- CMOS = NMOS + PMOS 共址(PMOS 置于 n-well),W/L 决定电流驱动能力;反相器是最基本单元。3D 能带图(势垒升降)是理解器件开关与短沟道效应的基础工具。
- 亚阈值斜率 S = (1 + Cdm/Cox)·(kT/q)·ln(10):电容分压项 ≥1,费米-狄拉克统计项 ≈ 26 mV × 2.3 ≈ 60 mV/dec——室温物理极限,任何厂商无法突破;实际最佳约 65–70 mV/dec。
- Ion/Ioff ≥ 10⁵ 的关断要求 × 60 mV/dec ⇒ 最小 VT ≈ 300 mV ⇒ 最低 VDD ≈ 600 mV——这是电压微缩停滞的根本物理原因。
- 短沟道效应与 DIBL:沟道过短或漏压过高都会压低源端势垒、抬高 Ioff;因 SS 固定,缩 L 带来的 Ion 增益必然伴随 Ioff 上升。应对手段:同一节点多 VT 器件(HP/LP),靠栅金属功函数工程调节。
- 技术节点是"营销符号":5/3 nm 节点的物理栅长停在约 15–16 nm;Intel 14 ≈ TSMC 10、Intel 10 ≈ TSMC 7(Intel 后来索性改名 Intel 7)。
- 真正驱动逻辑微缩的是 CPP/CGP(水平)与 M1 pitch(垂直),例如 5 nm 节点 G48M30L1 = CGP 48 nm、M1 30 nm;决定密度的是接触间距晶体管(8–12 F²),而非孤立晶体管(16–24 F²)。
- 标准单元高度缩减(9T3F → 7.5T3F → 6.5T2F → 6T2F → 5T1F → 4T1F)依靠减少金属轨道数与鳍减除(每鳍电流密度提升是关键使能因素),是近年密度提升的主要驱动力;背面供电将在 2 nm/1 nm 进一步助力。
- 存储器的节点定义更"诚实":F = 1/2 pitch(DRAM 用金属半 pitch、2D NAND 用 poly 半 pitch);3D NAND 真正关心的是堆叠层数。对逻辑而言,有意义的是绝对硅面积而非 F² 换算。
- 器件结构路线:90 nm 应变硅 → 45 nm HKMG → 22 nm FinFET → 3 nm 堆叠纳米片(Samsung MBCFET 已量产,TSMC/Intel 在 N2/18A 跟进)→ CFET(NMOS 叠 PMOS,约 5A 节点 / 2030 年后),是目前可见的逻辑微缩终点。
- 市场规模:2020 全球半导体约 $466B,独立存储器占 27%(约 $126B),其中 DRAM 53% / Flash 45%;SRAM 属嵌入式存储器,计入其他 IC 产品。
- 产业模式四分法:Foundry(TSMC 份额 >60%)/ Fabless(NVIDIA、AMD、Qualcomm 等)/ IDM(Intel IDM 2.0、Samsung;存储器公司与汽车电子归此类,存储器公司全闭环、不外提供 PDK)/ 系统集成商(Apple、Google 等自研芯片),EDA 是生态使能者。
- 排名变迁(2006→2023):从 Intel/传统 IDM 主导,到 2018 存储器超级周期 Samsung 登顶,再到 2023 TSMC 第 1、NVIDIA 第 3(+102%);SK Hynix 凭 NVIDIA HBM 独家供应成为 AI 浪潮的核心受益者。
术语表
| 术语 | 中文 | 说明 |
|---|---|---|
| MOSFET | 金属-氧化物-半导体场效应晶体管 | 通过栅压控制沟道导电的基本器件。 |
| CMOS(Complementary MOS) | 互补金属氧化物半导体 | NMOS 与 PMOS 共址构成的技术,逻辑电路的基础。 |
| n-well | n 阱 | 在 p 衬底中预制的 n 型区域,用于容纳 PMOS。 |
| Band diagram | 能带图 | 描述电子势能随位置变化的图,用于理解势垒、载流子流动与短沟道效应。 |
| Output / Transfer characteristics | 输出特性 / 转移特性 | ID-VD 与 ID-VG 两类代表性 I-V 曲线。 |
| VT(Threshold Voltage) | 阈值电压 | 沟道开启所需的最小栅压;受 SS 限制最小约 300 mV。 |
| VDSAT(Saturation Voltage) | 饱和电压 | 划分线性区与饱和区的漏压。 |
| RON(On-resistance) | 导通电阻 | 线性区斜率的倒数(Ω·μm),线性区晶体管近似电阻。 |
| ro / rd(Output resistance) | 输出电阻 | 饱和区小信号电阻,模拟放大器本征增益 gm·ro 的组成。 |
| Ion(On-current) | 导通电流 | VGS=VDS=VDD 时的最大电流,按栅宽归一化(mA/μm)。 |
| gm(Transconductance) | 跨导 | ΔID/ΔVGS,栅压对漏电流的调控能力(μS/μm)。 |
| Subthreshold Slope(S/SS) | 亚阈值斜率 | 电流降低 10 倍所需的栅压(mV/dec),室温物理极限 60 mV/dec。 |
| Decade | 十倍程 | 电流变化一个数量级(10 倍)。 |
| Ψs(Surface potential) | 表面电位 | 硅表面处的电位,栅压经 Cox/Cdm 分压后传到此处。 |
| Cox / Cdm | 栅氧电容 / 耗尽层电容 | 决定栅-沟道耦合效率的两个串联电容。 |
| SCE(Short Channel Effect) | 短沟道效应 | 沟道过短导致源/沟道势垒降低、漏电增大的效应。 |
| DIBL(Drain-Induced Barrier Lowering) | 漏致势垒降低 | 短沟道下漏压拉低源端势垒,使 Ioff 随 VDS 增大。 |
| HP / LP | 高性能 / 低功耗晶体管 | 同一节点提供的低 VT / 高 VT 器件选项。 |
| Workfunction engineering | 功函数工程 | 通过选择不同功函数的栅金属调节 VT。 |
| Technology node | 技术节点 | 逻辑工艺的命名标号,现已与物理尺寸脱钩的"营销符号";DRAM/Flash 的节点则对应实际物理半节距。 |
| CPP / CGP(Contacted Poly/Gate Pitch) | 接触多晶/栅间距 | 源接触中心到漏接触中心的距离,密度的水平指标(5 nm 节点约 48 nm),逻辑微缩的真实指标之一。 |
| M1 Pitch(Metal-1 Pitch) | 第一层金属间距 | 密度的垂直指标(5 nm 节点约 30 nm),与 CPP 共同决定标准单元面积。 |
| Metal track | 金属轨道 | 标准单元高度 = 轨道数 × M1 pitch(如 6T、5T 设计)。 |
| Standard cell / cell height | 标准单元 / 单元高度 | 反相器/NAND/NOR 等版图基本单元;高度降低(减少 M1 track 数)是近年密度提升的关键使能因素。 |
| FinFET | 鳍式场效应晶体管 | 22 nm 引入的三维结构,沿鳍侧壁导电,抑制短沟道效应;当前主流逻辑晶体管结构。 |
| Fin depopulation | 鳍减除 | 每鳍电流提升后减少每管鳍数(3 鳍→1 鳍)以降低单元高度,是当前密度提升的关键驱动。 |
| Backside power delivery | 背面供电 | 把 VDD/VSS 电源轨移到硅片背面以缩减单元高度,预计 2 nm/1 nm 节点引入。 |
| F(Feature size) | 特征尺寸 | 一般定义为光刻 pitch 的一半;DRAM 用金属半 pitch,2D NAND 用 poly 半 pitch。 |
| Half pitch | 半节距 | 线宽 + 线距的一半;DRAM/Flash 技术节点对应的物理最小特征尺寸定义。 |
| Pillar pitch | 柱间距 | 3D NAND 中垂直沟道柱的间距(约 100 nm 量级);3D NAND 真正关心的是堆叠层数。 |
| Strained silicon | 应变硅 | 90 nm 引入,用 SiGe 源漏 / 氮化物帽层施加应力提升迁移率。 |
| HKMG(High-k/Metal Gate) | 高 k 栅介质 / 金属栅 | 45 nm 引入,解决栅漏电。 |
| GAA(Gate-All-Around) | 全环绕栅 | 栅极四面包裹沟道的结构,纳米片晶体管的栅架构。 |
| Stacked nanosheet | 堆叠纳米片 | FinFET 之后的 GAA 结构;Samsung 已量产(称 MBCFET),Intel 称 nanoribbon。 |
| MBCFET(Multi-Bridge-Channel FET) | 多桥沟道 FET | Samsung 对 GAA 堆叠纳米片的商品名(3 nm 量产)。 |
| CFET(Complementary FET) | 互补场效应晶体管 | NMOS 垂直堆叠于 PMOS 之上,路线图约 5A 节点 / 2030 年后,目前可见的微缩终点。 |
| IEDM | 国际电子器件会议 | Intel 2020 年在此发表 CFET 早期演示论文。 |
| Standalone memory | 独立存储器 | 以独立芯片形式出售的存储器(DRAM、NAND Flash),区别于片上嵌入式存储器。 |
| Embedded memory | 嵌入式存储器 | 与处理器集成在同一芯片上的存储器(如 SRAM),营收计入处理器/逻辑产品而非存储器市场。 |
| Foundry | 晶圆代工厂 | 只做芯片制造、不做自有产品设计的公司(如 TSMC,市场份额 >60%)。 |
| Fabless | 无晶圆厂设计公司 | 只做芯片设计、把制造外包给代工厂的公司(如 NVIDIA、AMD、Qualcomm)。 |
| IDM(Integrated Device Manufacturer) | 整合器件制造商 | 设计与制造一体的公司(如 Intel、Samsung)。 |
| IDM 2.0 | Intel IDM 2.0 战略 | Intel 拆分模式:Intel Foundry 对外接单,同时 Intel 自家芯片也交 TSMC 等外部代工。 |
| DTCO(Design-Technology Co-Optimization) | 设计-工艺协同优化 | Fabless 公司与代工厂共同优化设计与工艺以达最佳 PPA 的方法。 |
| PDK(Process Design Kit) | 工艺设计套件 | 代工厂提供给设计公司的工艺文件包;存储器公司不对外提供 PDK(全闭环自产)。 |
| EDA(Electronic Design Automation) | 电子设计自动化 | 芯片设计软件工具,厂商如 Cadence、Synopsys、Mentor Graphics。 |
| System Integrator | 系统集成商 | 自研定制芯片的系统/互联网公司(Apple、Google、Meta、Amazon 等)。 |
| HBM(High Bandwidth Memory) | 高带宽存储器 | 用于 GPU/AI 加速器的堆叠 DRAM;NVIDIA 的 HBM 由 SK Hynix 独家供应。 |