Lecture 3:SRAM
1. SRAM 的定位与缓存演进 P1 00:00:39
SRAM = Static Random Access Memory,三个关键词各有确切含义:Static(静态)——不需要周期性刷新(与需要刷新的 DRAM 相对),只要电源在数据就保持;Random Access(随机访问)——给定地址即可独立读写阵列中任意一位(与必须按特定顺序读出的 NAND Flash 相对);Volatile(易失性)——掉电后数据丢失(与非易失存储器相对)。这三个特性确定了 SRAM 在存储层次中的定位:高速、片上、易失的缓存(cache)。
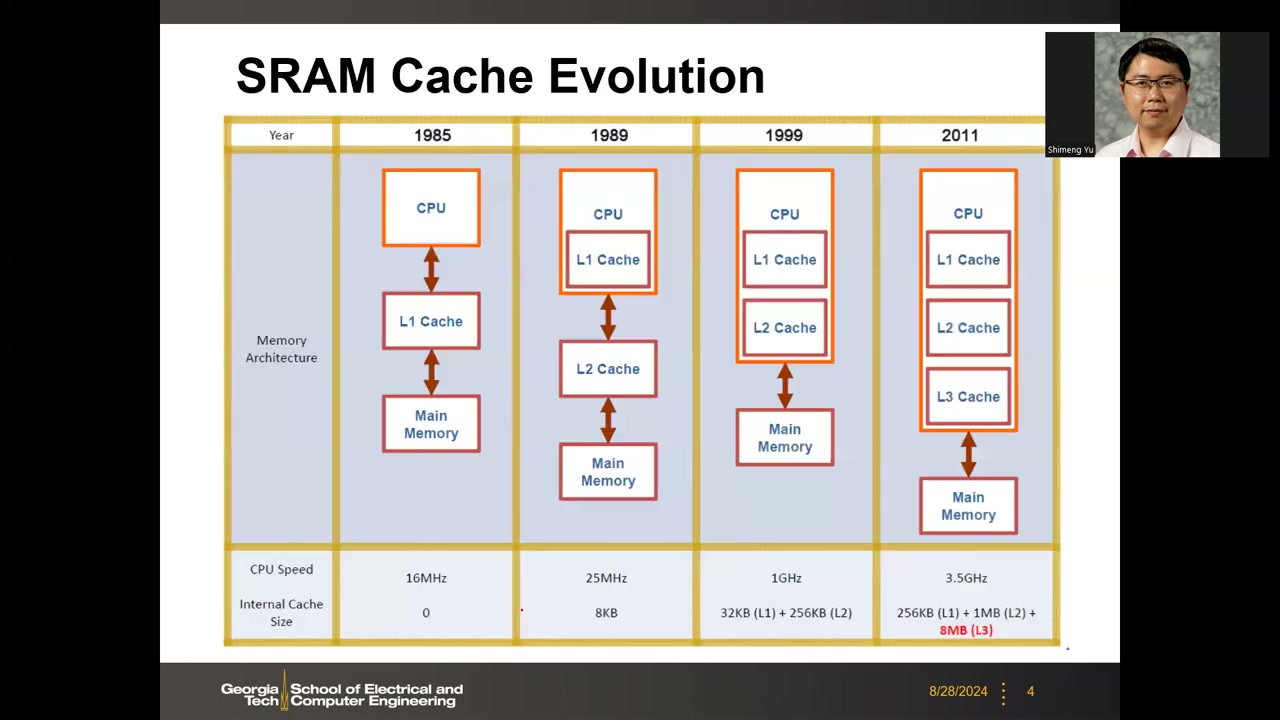
SRAM 缓存的历史演进 P1 00:02:20:缓存逐步从片外移到处理器片上(嵌入式存储器,embedded memory),层级越来越多;最新的 AMD 处理器借助 3D V-Cache 把片上 SRAM 缓存做到 64 甚至 96 MB(见第 20 节)。
| 年份 | 结构 | CPU 主频 | 片内缓存容量 |
|---|---|---|---|
| 1985 | CPU → L1(片外)→ 主存 | 16 MHz | 0 |
| 1989 | CPU(含 L1) → L2 → 主存 | 25 MHz | 8 KB |
| 1999 | CPU(含 L1+L2) → 主存 | 1 GHz | 32 KB (L1) + 256 KB (L2) |
| 2011 | CPU(含 L1+L2+L3) → 主存 | 3.5 GHz | 256 KB (L1) + 1 MB (L2) + 8 MB (L3) |
2. 6T 单元结构与 Hold / Read / Write 概览 P1 00:03:47
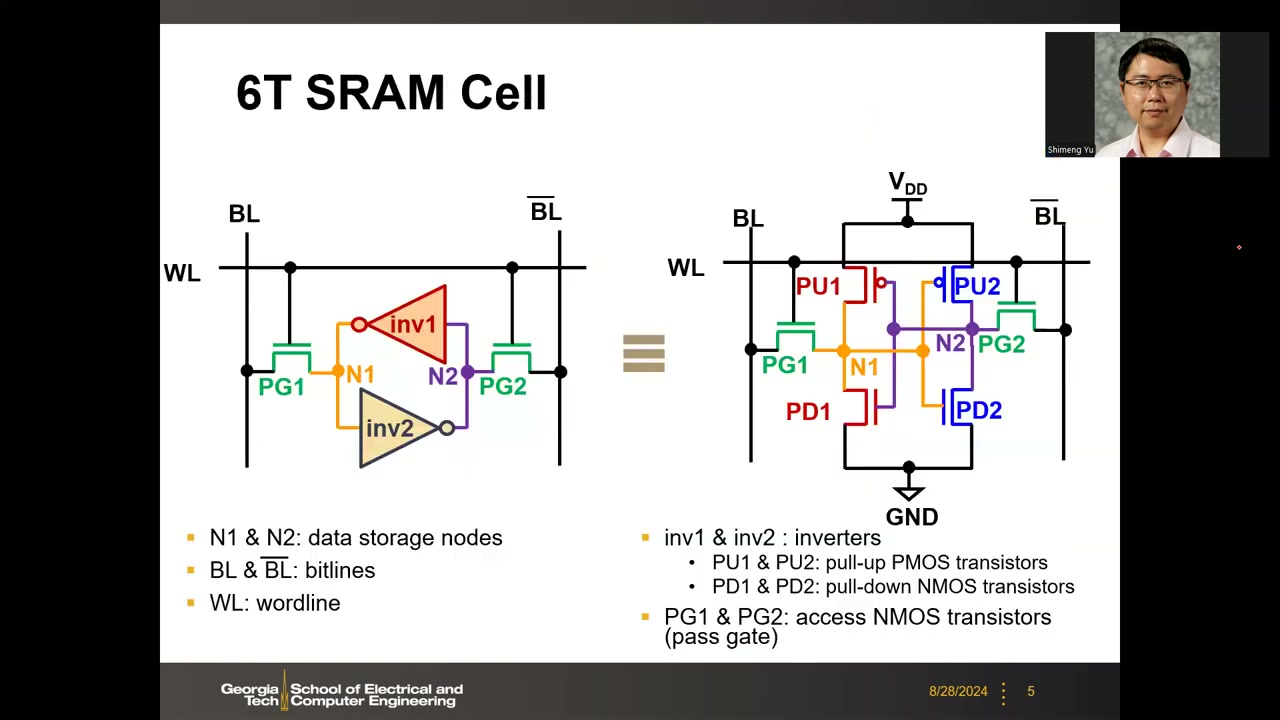
6 管 SRAM 位元(bit cell)= 中间一对交叉耦合反相器(cross-coupled inverters)+ 两个存取管(pass gate)。命名约定:
- N1、N2:两个存储节点,因锁存特性数据永远互补(N1=1 则 N2=0);约定以 N1 一侧表示存储的数据。
- PU1/PU2 = pull-up PMOS(上拉,接 VDD);PD1/PD2 = pull-down NMOS(下拉,接 GND);PG1/PG2 = access NMOS(存取管)——共 4 个 NMOS + 2 个 PMOS。
- BL / BL̄:互补位线;WL(字线)控制两个 pass gate 的栅极。
- 交叉耦合:inv2 的输出(N2)接 inv1 的输入(PD1/PU1 的栅),反之亦然。Pass gate 原则上可用 PMOS,但 NMOS 迁移率与驱动电流密度更优,实际一律用 NMOS。
三种操作模式 P1 00:06:54(约定 0 = GND、1 = VDD):
- Hold(保持):WL=0,pass gate 关断,电路只剩交叉耦合反相器,靠锁存特性维持两种互补状态之一。
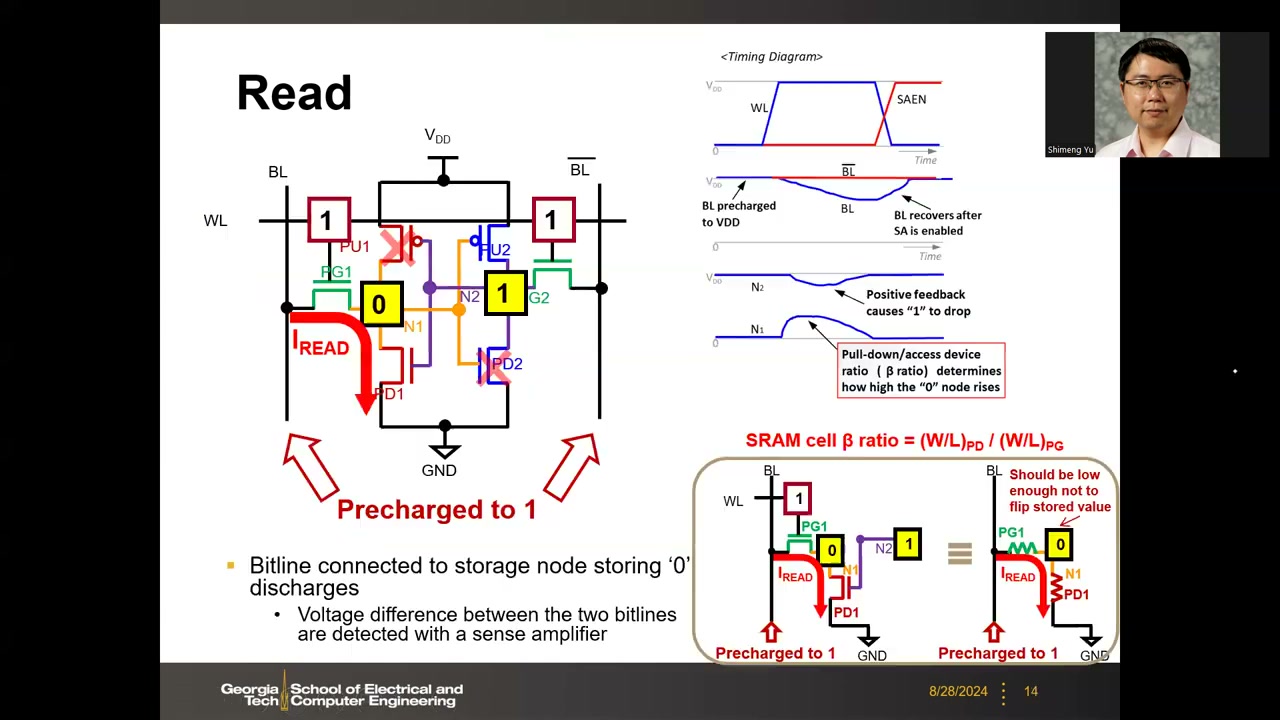
- Read(读):先把 BL 与 BL̄ 预充电到 VDD(长位线有寄生电容 C_BL 起电荷存储作用),再打开 WL。存 0 的一侧产生放电电流,BL 电压衰减 ΔV;存 1 的一侧 pass gate 三端等电位、无电流。阵列边缘的灵敏放大器检测两位线间的微小压差并放大为数字 0/1。
- Write(写):先把 BL、BL̄ 偏置为要写入的互补数据,再打开 WL,把外部数据"拷贝"进存储节点(细节见第 4 节)。
3. 读操作:读扰动、β ratio 与读速度 P1 00:17:57
读路径 = PG1 + PD1 串联(放电电流必须经下拉管汇入真正的地)。把两管近似为电阻,这就是一个电压分压器:放电电流流过时,存 0 节点 N1 的电位高于地——"读 0 时 0 并不是真 0",被抬高一个 ΔV,即读扰动(read disturb)。N1 是 PD2 的栅,V_N1 升高会"半开"PD2 把 V_N2 拉低;若正反馈持续到两线交叉,数据就被翻转,相当于一次误写,必须避免。
因此要求 PD 电阻小(电导大)。晶体管电导 ∝ W/L,由此得 6T 尺寸设计第一条规则(读稳定性约束):
SRAM cell β ratio = (W/L)PD / (W/L)PG —— 要求 PD 强、PG 弱,β ratio 要大,分压效应才能保证读期间 N1 节点抬升足够小。读完关 WL 后,被注入的扰动相当于蝶形曲线分析中的噪声,只要小于噪声容限,正反馈迭代会让状态恢复原值。
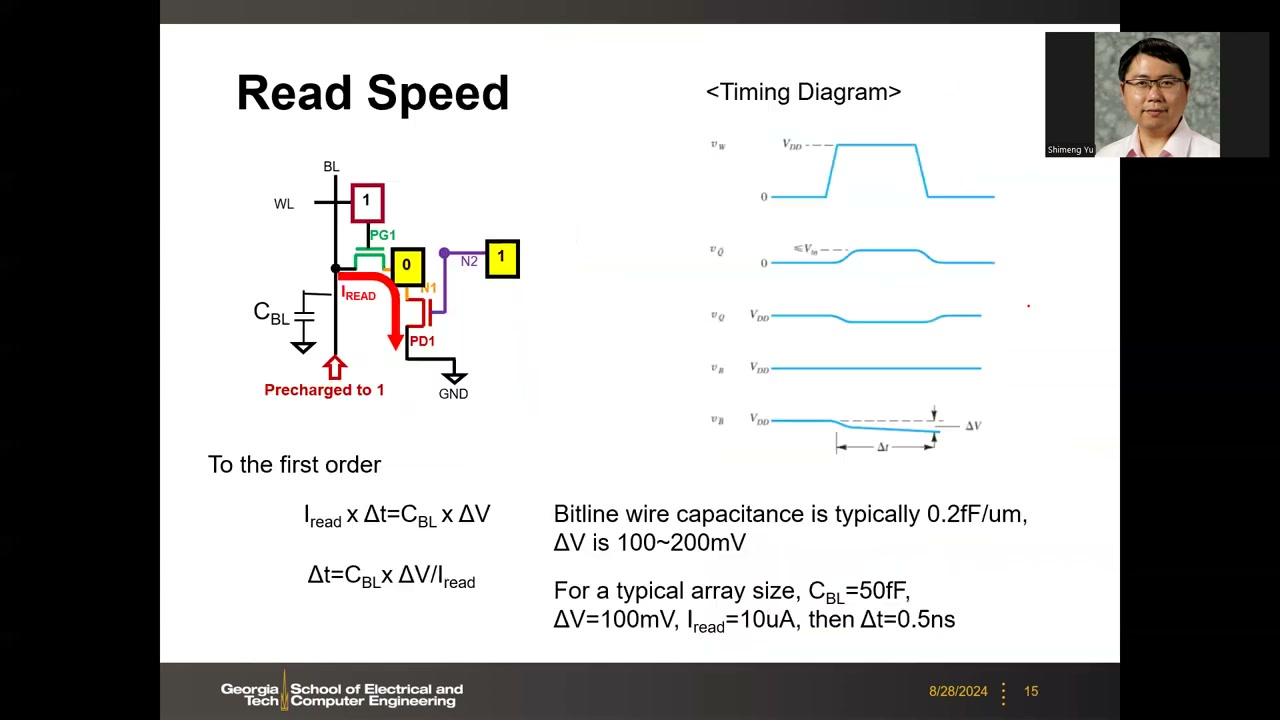
读速度的一阶估算 P1 00:25:50:放电电荷 = 电容 × 电压变化,
Iread × Δt = CBL × ΔV ,即 Δt = CBL × ΔV / Iread
- 位线导线电容典型值 0.2 fF/μm,取决于位线长度(一条位线挂 32 或 128 个单元)。
- 灵敏放大器可靠检测需 ΔV ≈ 100–200 mV(存在失配、热噪声等非理想因素)。
- 典型算例:CBL = 50 fF,ΔV = 100 mV,Iread = 10 μA → Δt = 0.5 ns,对应约 2 GHz 时钟。要更快(如 3 GHz)可加大 pass gate 的 W/L——这正是 L1/L2/L3 设计差异的来源之一。
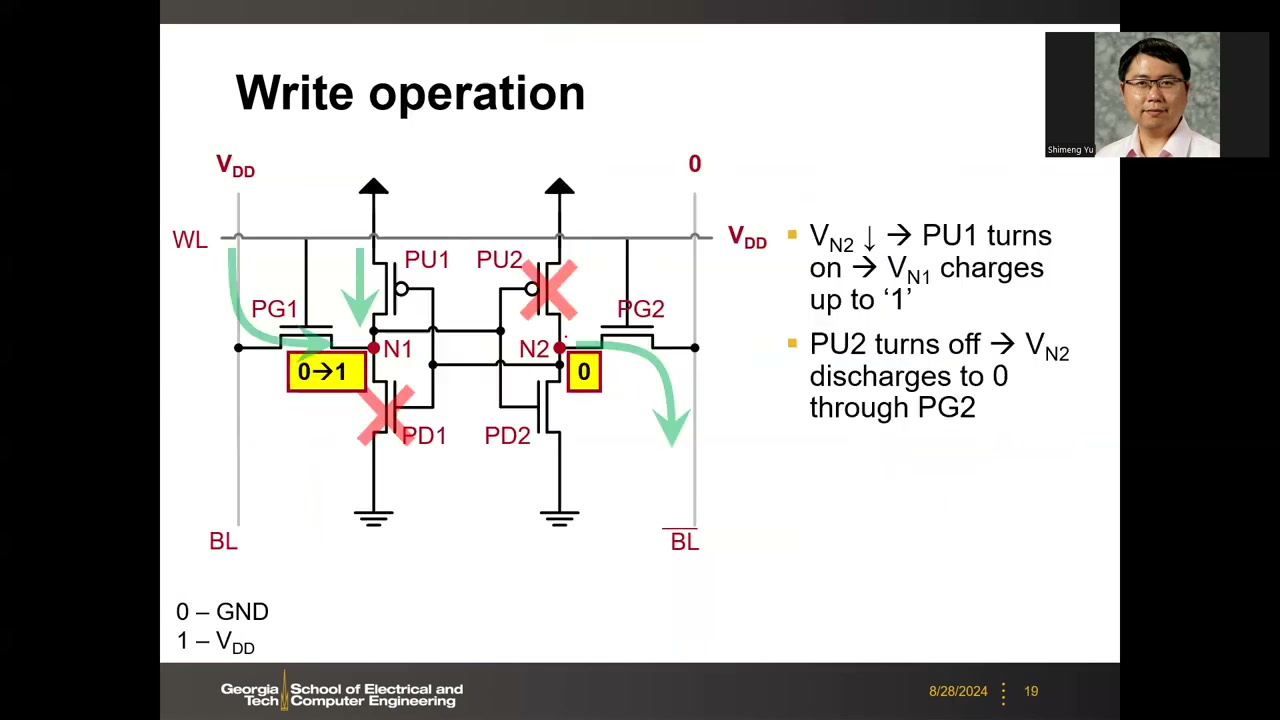
4. 写操作:1→0 先行与 γ ratio P1 00:29:37
写入要翻转数据(例:初始 N1=0/N2=1,写入 N1=1/N2=0),涉及两个翻转。结论:1→0 先发生,0→1 随后:
- 0→1 不会自己发生:BL=VDD、N1=0、PG1 开——这与读操作的偏置完全相同,而读的设计要求(β ratio 大)恰恰保证了 N1 只被轻微抬升、不翻转。"By design"读约束使 0→1 无法由 PG1 单独触发。
- 1→0 主动发生:BL̄=0、N2=VDD、PG2 开,电流从 VDD 经 PU2→PG2→BL̄ 流向地,把 N2 拉低。这又是一个分压器(VDD—PU2—N2—PG2—GND):要让 N2 接近 0,需 PG 强、PU 弱。
- N2 足够低后:N2 是 PU1(PMOS)的栅,V_GS 变负 → PU1 导通 → 额外电流把 N1 充到 1,完成 0→1(之前仅靠 PG1 的电流不足以翻转 N1)。
由此得第二条尺寸规则(写能力约束):SRAM cell γ ratio = (W/L)PU / (W/L)PG。γ ratio 可取约 1 仍满足"PG 强、PU 弱"——因为 PU 是 PMOS、PG 是 NMOS,μn > μp,相同 W/L 下 NMOS 驱动力仍更强(65 nm 等老节点 μn ≈ 2μp;先进 FinFET 节点差距已缩小到约 10%)。
写时序图上,N2(1→0)先衰减,足够低后 N1 才开始上升,两线交叉点更靠近 GND 而非 VDD——正因为 1→0 必须先发生。读与写由不同节点发起:读关心存 0 节点的抬升(要最小化),写由存 1 节点的下拉发起(要拉得足够低)。
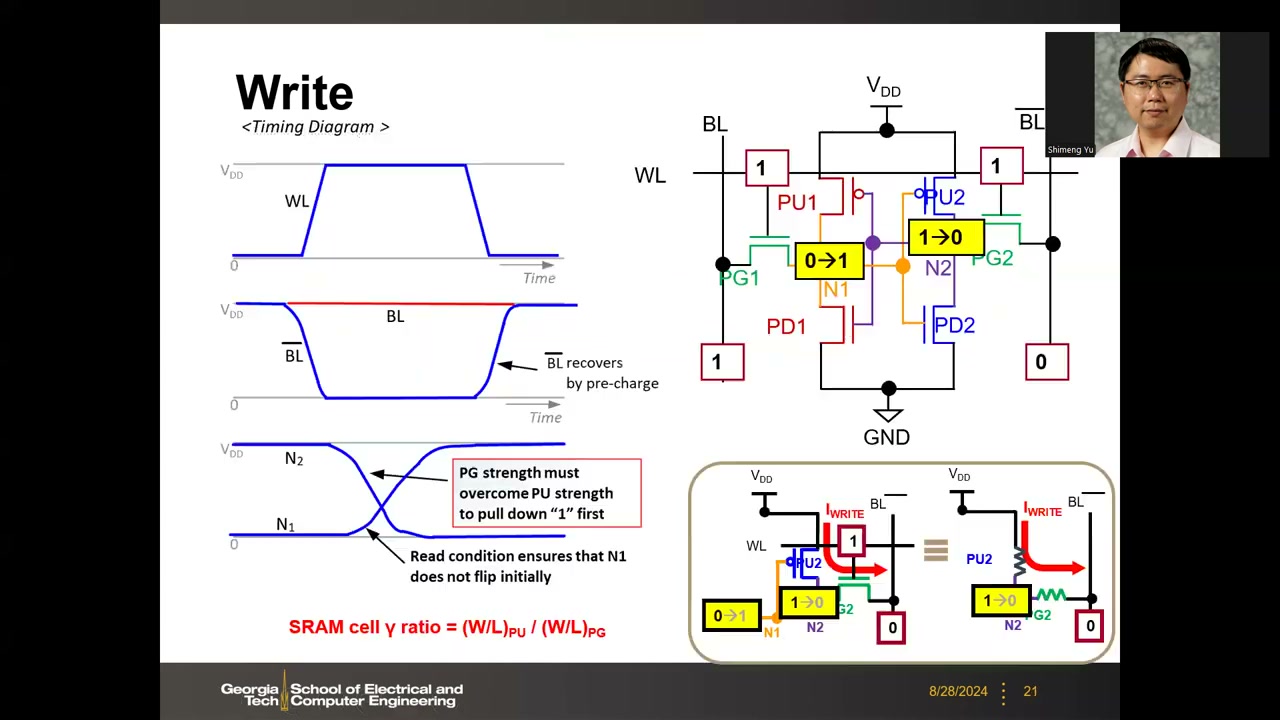
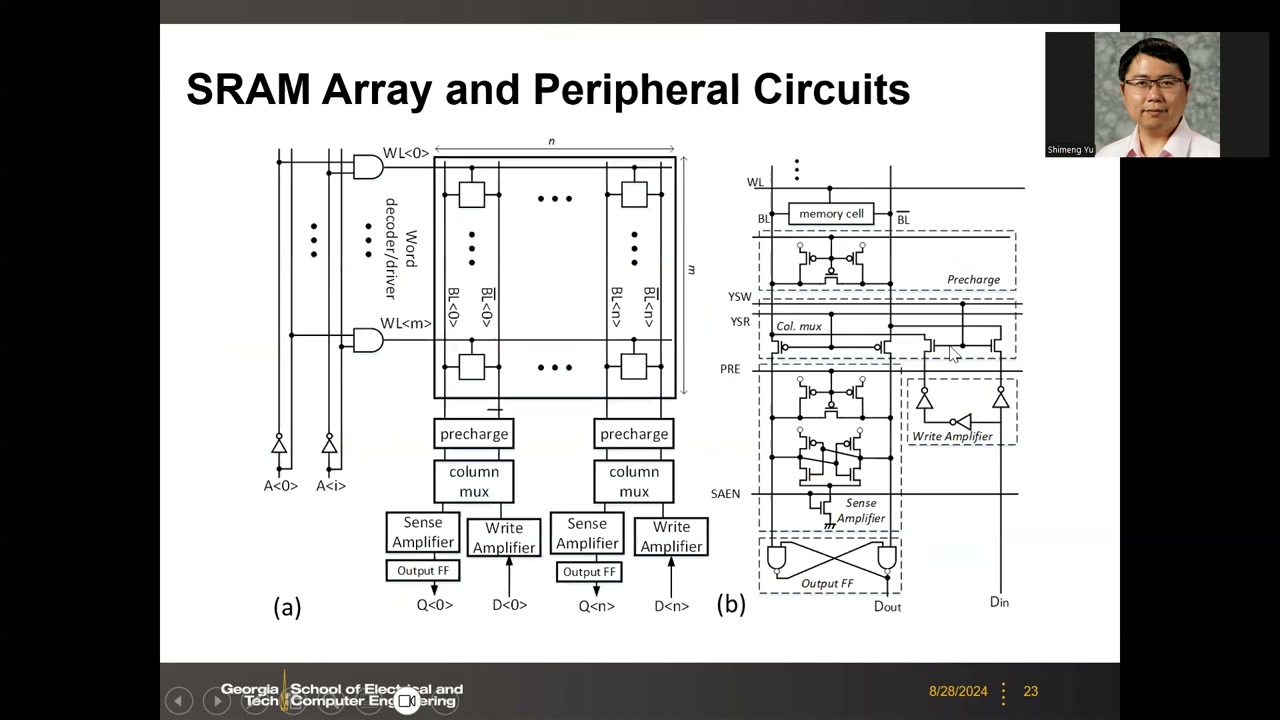
5. SRAM 阵列与外围电路 P1 00:39:35
m×n 的 6T 阵列:行方向由字线译码器/驱动器选行;列方向每对 BL/BL̄ 接一套外围电路:precharge → column mux → sense amplifier(读路径 → 输出触发器)/ write driver(写路径 ← D_in)。
- 预充电模块:3 个 PMOS——两个把 BL、BL̄ 接 VDD,中间一个作"桥"(equalizer)保证预充后两位线严格等电位;由 PRE 信号控制。
- 列选通(column mux):两个传输门,由 YSR/YSW 在读/写路径间选择。
- 灵敏放大器(SA):本质是一个锁存(交叉耦合反相器);其底部不直接接地,而是经尾部 NMOS 接地,由 SAEN(sense amp enable)控制。SAEN=0 时锁存"悬浮",两节点可同为 VDD;必须等位线 ΔV 充分建立后才拉高 SAEN——锁存接地后必然翻转,电压低的一侧被强制拉到 0,把毫伏级 ΔV 放大为数字 0/1,结果锁入输出触发器送出。
- 写驱动器:用不同级数的反相器链从 D_in 生成互补数据,经列 mux 写入。
阵列级完整时序图 P1 00:47:31(Ishibashi & Osada 2011)展示读/写周期中 CK、WL、位线、PE、YSR/YSW、SE(SAEN)、Q、D 等全部控制信号——关键约束是 SE 相对 WL 上升沿延迟 Δt,等待 ΔV 建立。
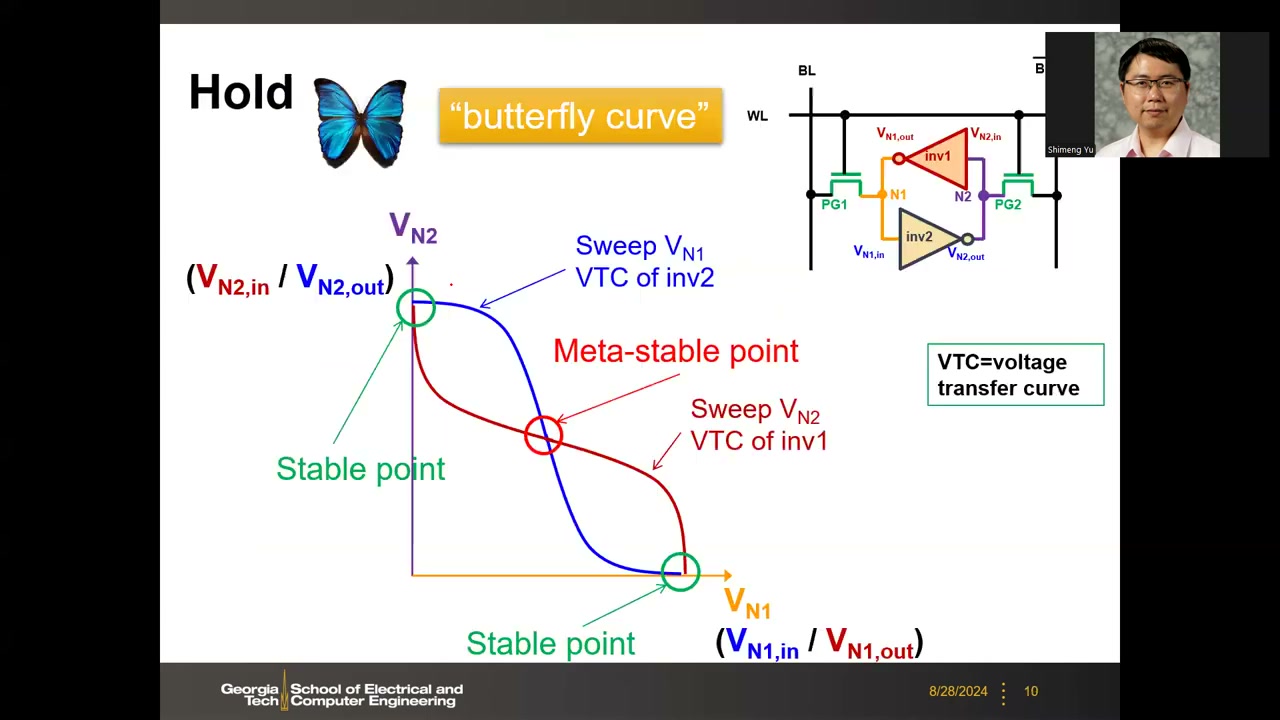
6. 静态稳定性:蝶形曲线与 SNM P1 00:13:05 P2 00:00:03
在 VN1–VN2 平面上画出两个反相器的电压传输曲线(VTC,其中一条需对调坐标轴),得到蝶形曲线(butterfly curve)。两曲线有 3 个交点:两个稳定点(对应数据态 (0,1) 与 (1,0))和中间约 VDD/2 处的亚稳点——任何噪声都会把它推向稳定点之一。从稳定点出发的受扰状态可经两条 VTC 的交替迭代收敛回原点,这就是交叉耦合结构对噪声鲁棒的原因。
静态噪声裕度(SNM):静态分析假设噪声永久存在(最坏情况)。在两个存储节点各串入噪声电压源后 VTC 平移,当两曲线间"无空间"时单元翻转。SNM = 蝶形曲线内可嵌入的最大正方形的边长。计算技巧(作业相关):把坐标轴旋转 45°,求两条 VTC 间的最大距离 D1(即正方形对角线),则 SNM = D1/√2。
Read SNM < Hold SNM P2 00:03:11:读时 pass gate 导通,存 0 节点因 PG/PD 分压被抬高,蝶形曲线"low"端抬离地,可嵌入正方形缩小(经典文献:Seevinck, JSSC 1987;Bhavnagarwala, JSSC 2001)。Read 蝶形曲线的获得:假设 BL/BL̄ 恒为 VDD,只需分析半边 3 管电路(PG、PD、PU),由 KCL 扫描求解,再沿 45° 镜像。
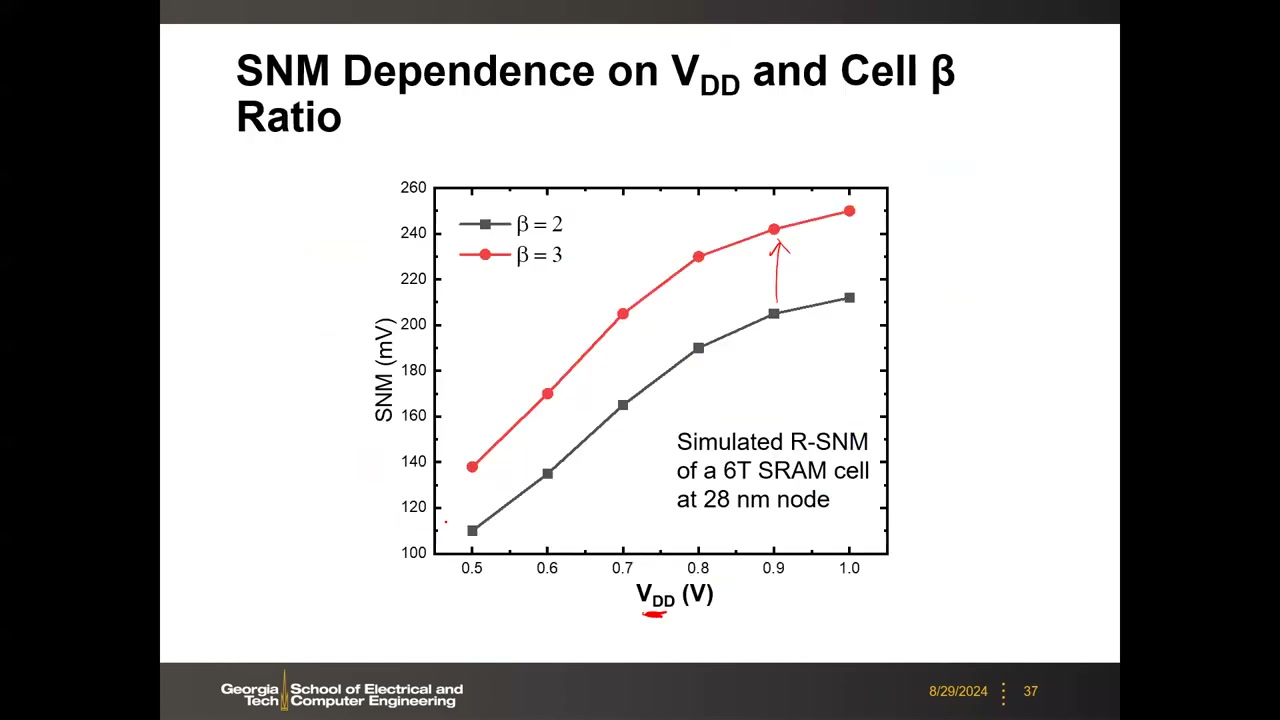
器件设计对 SNM 的影响 P2 00:11:13:β 越大,"low"电平越接近地且 VTC 转换越陡,Read SNM 越大(代价是面积)。28 nm SPICE 仿真:β 从 2→3,SNM 提升约 60–70 mV;VDD 从 0.5 V→1.0 V,SNM 从约 110 mV→212 mV(β=2)。设计经验值:SNM 达 150–200 mV 足够,低于 100 mV 就很棘手——而降功耗要求降 VDD,与噪声裕度需求矛盾。
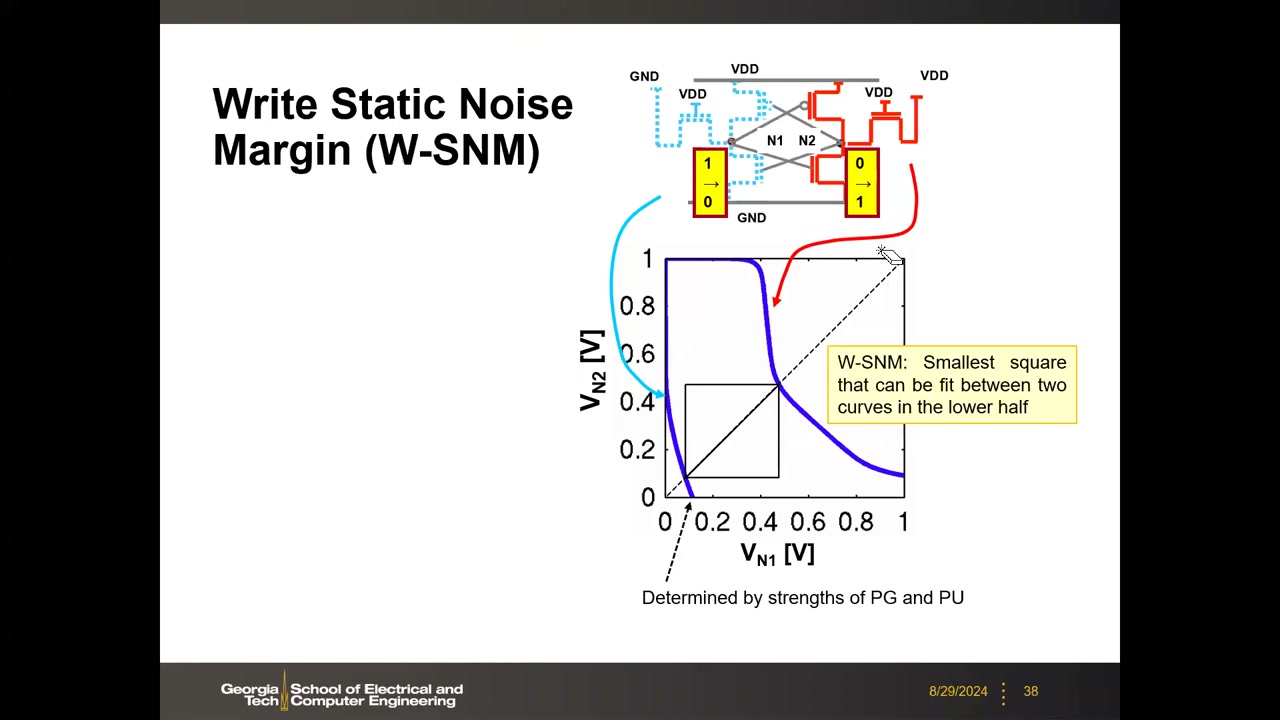
写静态噪声裕度 W-SNM P2 00:16:35:写偏置(BL=0、BL̄=VDD、WL=VDD)下分析左右两组 3 管曲线,成功写入要求两曲线只有一个交点(目标数据);若噪声平移产生额外交点,写入结果随机 → 写失败。W-SNM = 两曲线(下半平面)间可嵌入的最小正方形的边长,由 PG 与 PU 强度决定。
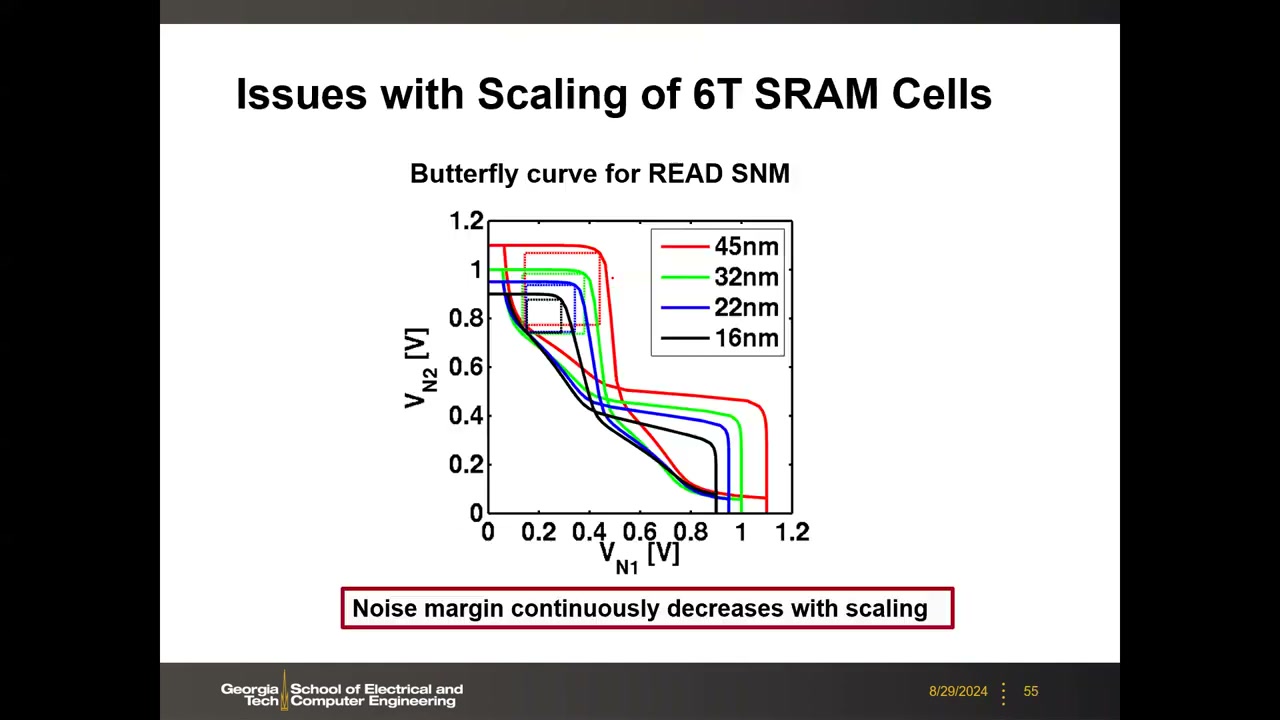
各节点硅实测 P2 00:38:55:65 nm(0.625 µm² cell,SNM≈300 mV@1.2V)→ 32 nm HKMG(0.124 µm²,SNM=220 mV@0.8V)→ 22 nm(0.1 µm²,要记住;SNM=220/180/148 mV @ 0.9/0.8/0.7 V)→ 16 nm FinFET(成组统计曲线)→ <10 nm(0.03 µm²,SNM>100/90 mV @ 0.6/0.45 V)。总趋势:VDD 随节点降低 → 噪声裕度随缩放持续下降,是设计核心挑战。
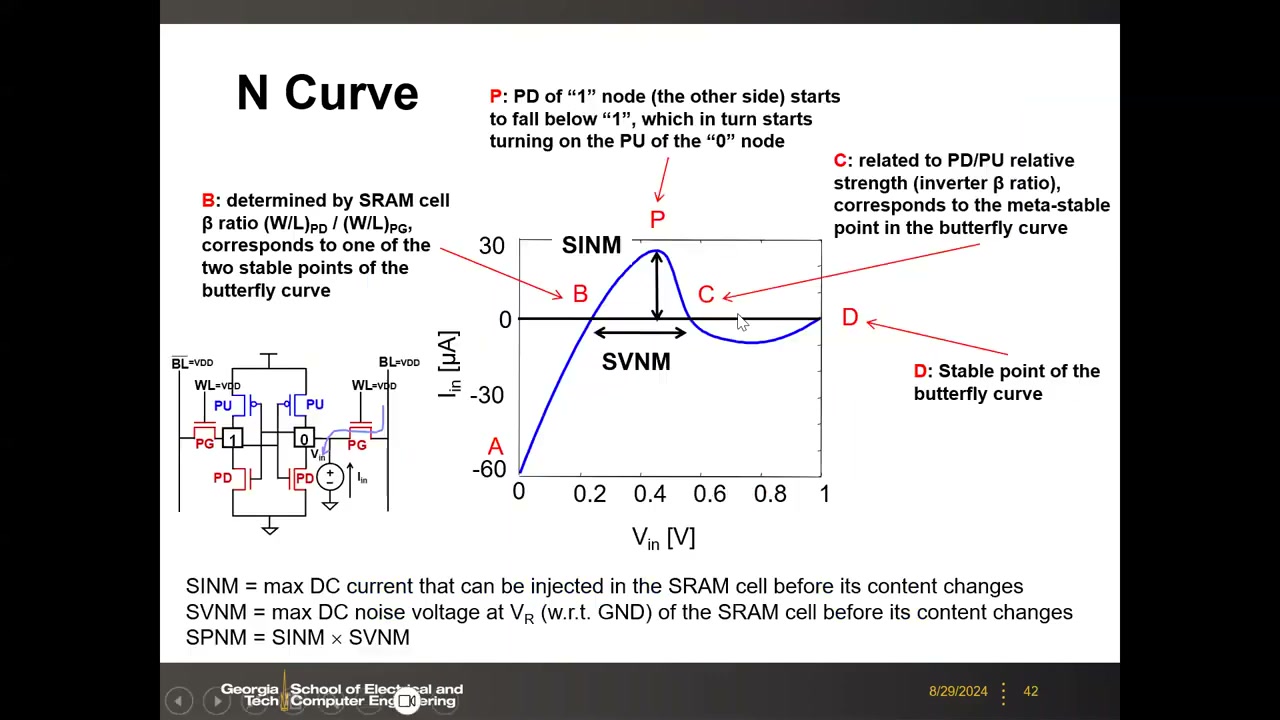
7. N 曲线测试法 P2 00:20:28
动机:蝶形曲线只给电压噪声裕度;N 曲线同时给出电压与电流裕度,且兼容在线(in-line)晶圆级测试。测法:读偏置(BL=BL̄=VDD、WL=VDD)下,在存 0 节点接电压源 Vin 从 0 扫到 VDD,测电流 Iin,曲线形似字母 N。
关键点 A–B–P–C–D:B 点(Iin=0,电压由 β ratio 决定)对应蝶形曲线稳定点;P 点(电流峰值)触发正反馈翻转;C 点对应亚稳点;D 点(Vin=VDD)对应另一稳定点。三个裕度定义:
- SINM = 翻转前可注入的最大直流电流(B 与 P 之间的电流峰值);
- SVNM = 翻转前存储节点(相对 GND)可容忍的最大直流噪声电压(B 到 C 的电压跨度);
- SPNM = SINM × SVNM(最大可注入功率噪声裕度)。
N 曲线可由三管电流合成:KCL 给出 Iin = −(IPG+IPD+IPU),沿轨迹对三管输出特性取 trace 逐点相加即得。
两法比较 P2 00:32:17:本质等价(信息都含于 MOSFET 的 IV 曲线)。蝶形曲线易与设计参数(β ratio)挂钩、更适合刻画失配;N 曲线无需 45° 旋转后处理、直接读出 SVNM/SINM,更适合在线测试,但 SVNM 会略微高估电压裕度。两者画在同一图上时三个临界点对齐。

8. 读写冲突、辅助电路与 8T SRAM P2 00:44:01
读与写的根本冲突:读优化希望锁存强、pass gate 弱(大 β、大 γ);写优化希望存储节点与位线强耦合——pass gate 强、PU 弱(小 β、小 γ)。冲突根源是 pass gate 被读写共享:读电流经 PG 但不许改变状态,写电流也经 PG 却要求足以翻转状态,只能折中。
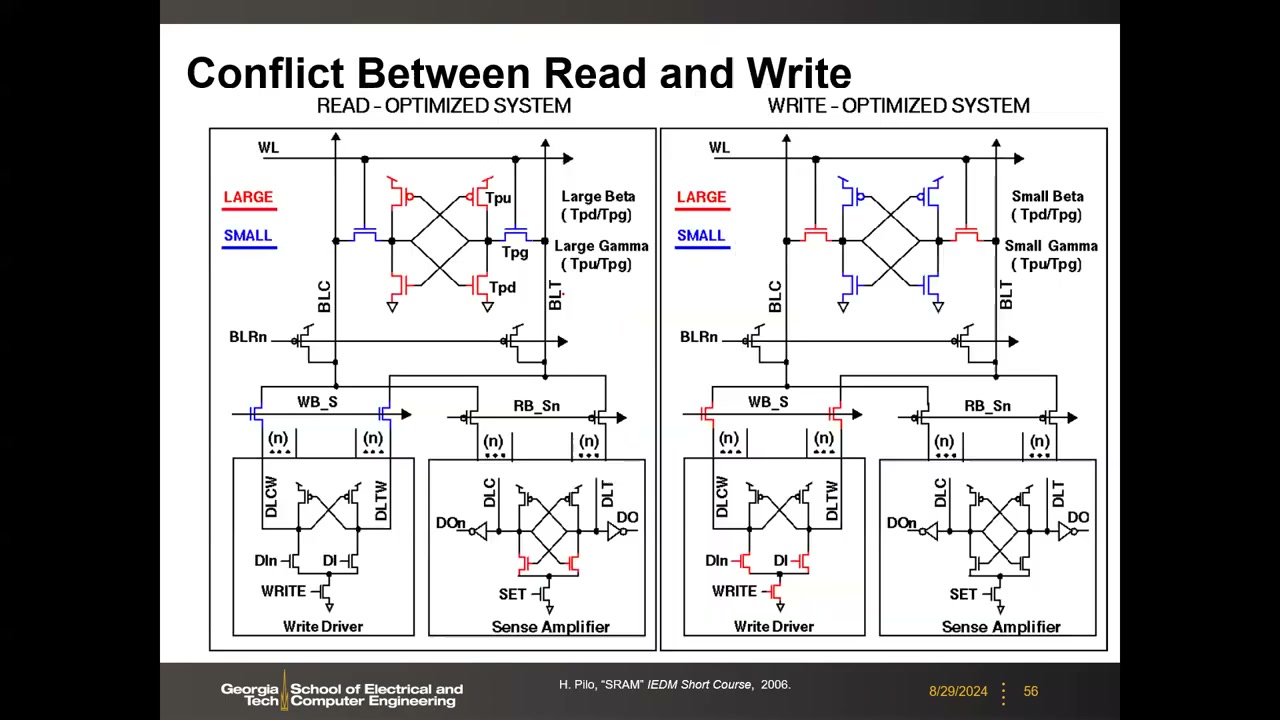
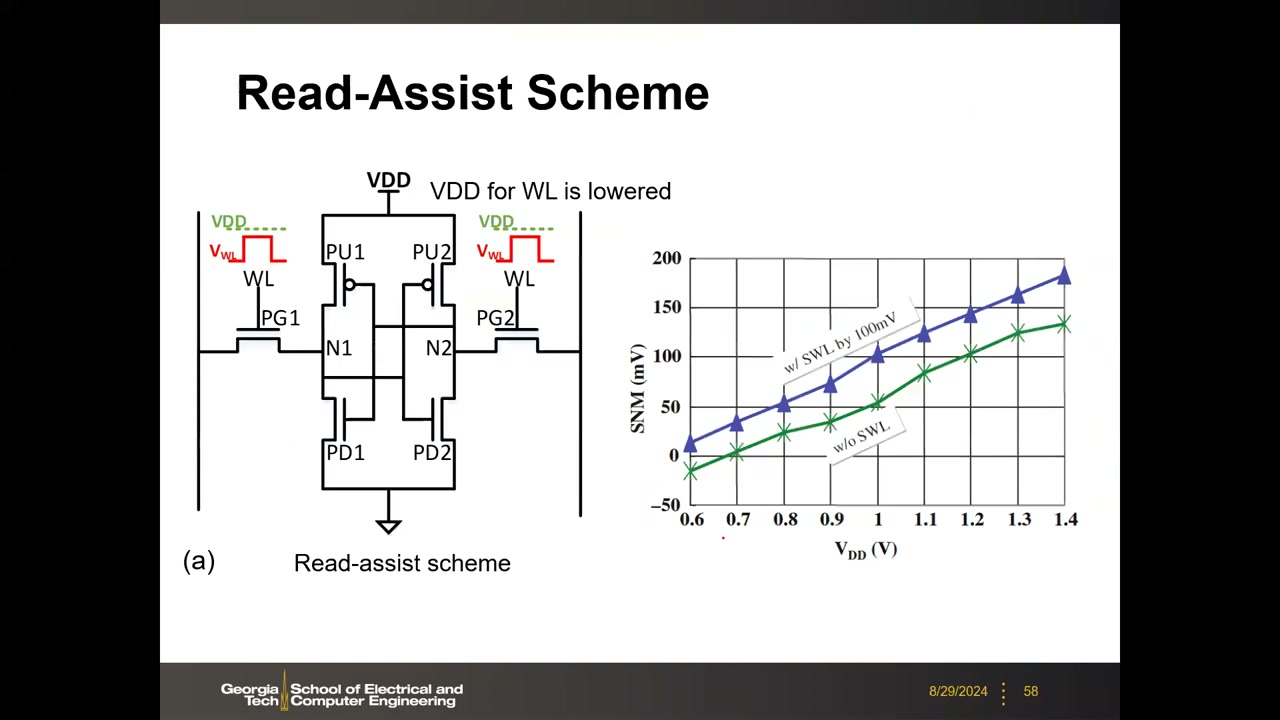
辅助电路技术 P2 00:47:43:
- Read-Assist(降字线电压):WL 电压低于 VDD → PG 相对变弱(等效增大 β 而不改尺寸)。实测 WL 降 100 mV,SNM 提升约 50 mV;代价是读速度下降("没有免费午餐")。
- Write-Assist(口诀:写希望 PG 强、PU 弱):① 负位线 NBL——写 0 时 BL = −ΔV(如 −100 mV),增大 PG 的 VDS 使其更强;② 降 cell 电源 LCV——cell 的 VDD 降为 VDD−ΔV,PU 变弱,写裕度提高。
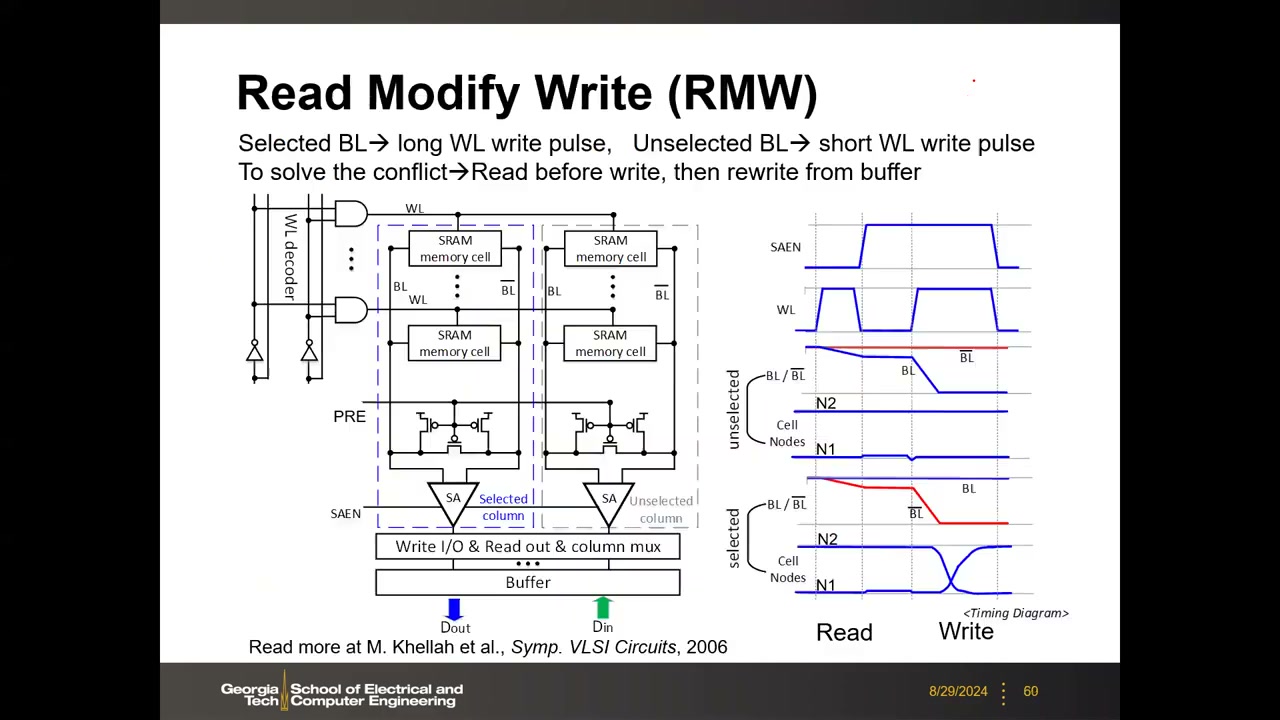
- Read-Modify-Write(RMW):写只选中部分列,同行未选中列也看到长 WL 脉冲(对它们相当于"读",可能被翻转)。解法:先整行读到 buffer,替换要写的位,再整行写回——每步整行经历同一操作。代价:两步操作变慢。
8T SRAM:读写路径解耦 P2 00:58:18:在 6T 基础上加两个串联 NMOS 读缓冲(一管栅接存储节点,一管由新增读字线 RWL 控制),读经专用读位线 RBL 放电;写与 6T 完全相同(原 WL 改称 WWL)。优点:读写可分别优化,读时内部节点不受扰动,Read SNM = Hold SNM。代价:每 cell 多 2 管 + 多一套 RWL/RBL 布线(L. Chang et al., JSSC 2008)。
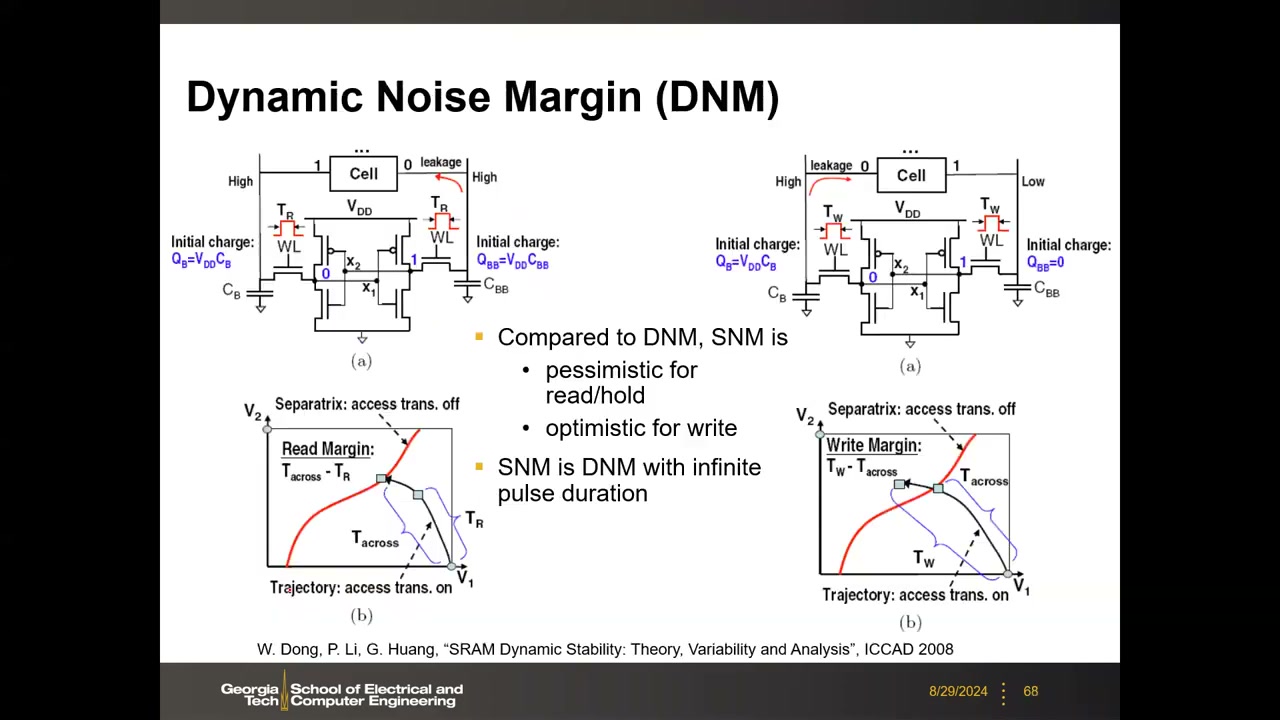
9. 动态稳定性:DNM、Tcrit 与 Shmoo 图 P2 01:03:16
静态分析的两个理想化假设在真实电路中都不成立:位线预充后是浮空的(不是恒压源),噪声也不会永久存在。动态分析把 V1(t)、V2(t) 映射到 V1–V2 相平面得到轨迹(trajectory):噪声撤去时若轨迹未越过分界线(separatrix,对称单元为 45° 对角线,失配时畸变),正反馈会把状态拉回原点;越过则翻转。是否翻转取决于噪声持续时间与电流幅度。
- Tcrit(临界翻转时间):轨迹从初始点运动到稳定边界所需时间(B. Zhang et al., ICCAD 2006 解析模型)。
- 写动态裕度:写字线脉宽 TW 必须长于轨迹越界时间 Tacross,TDNM(write) = TW − Tacross;TW < Tacross → 写失败。读希望 WL 脉冲短、写希望长——矛盾再现(这正是 RMW 分步的原因)。
Shmoo 图 P2 01:15:20:流片后在时钟频率 × 电源电压组合下按误码率画 pass/fail 边界。65 nm 示例:约 1.0 V/2.0 GHz 与 0.45 V/240 MHz 两个工作角。判别(课堂问答):高频角失败由写失败主导(时钟太快 TW 不足);低压角失败由读失败主导(VDD 太小读裕度不足)。最新数据(TSMC 5 nm, ISSCC 2020):L1 cache 达 4.1 GHz @ 0.85 V;HD macro 约 2 GHz @ 0.95 V。
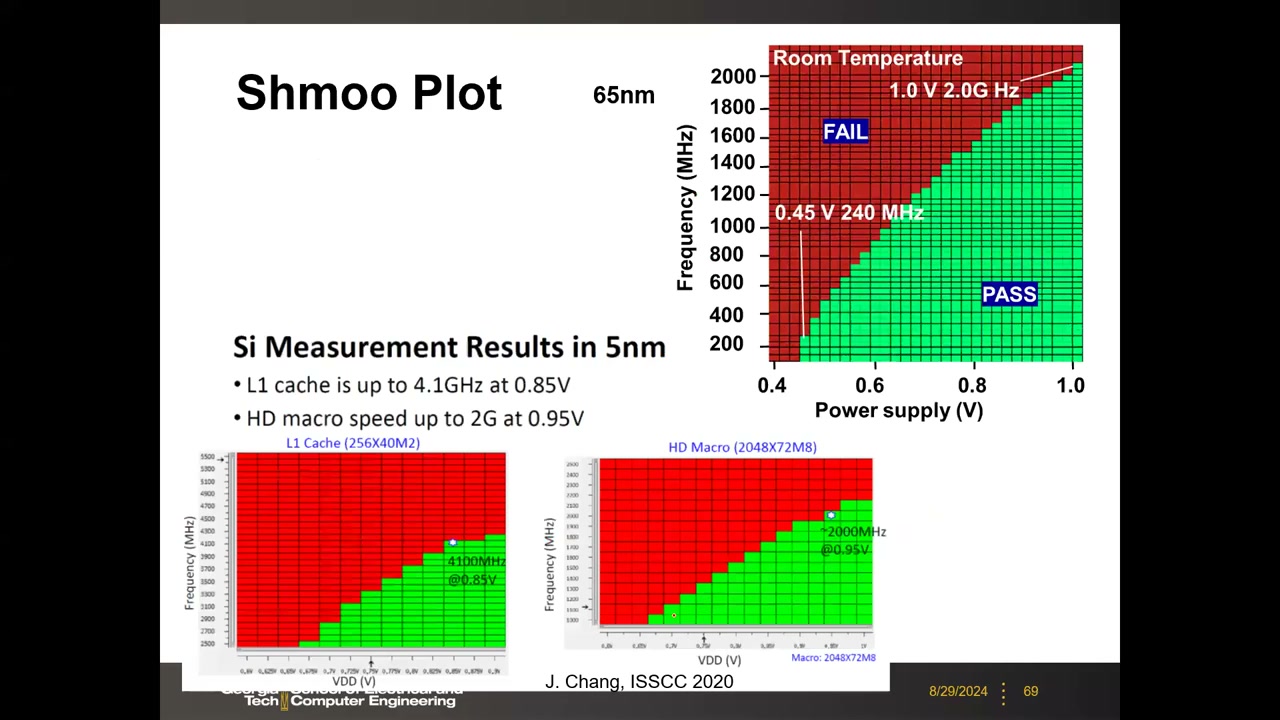
10. 单元设计考量:速度、漏电与互连优化 P3 00:02:20
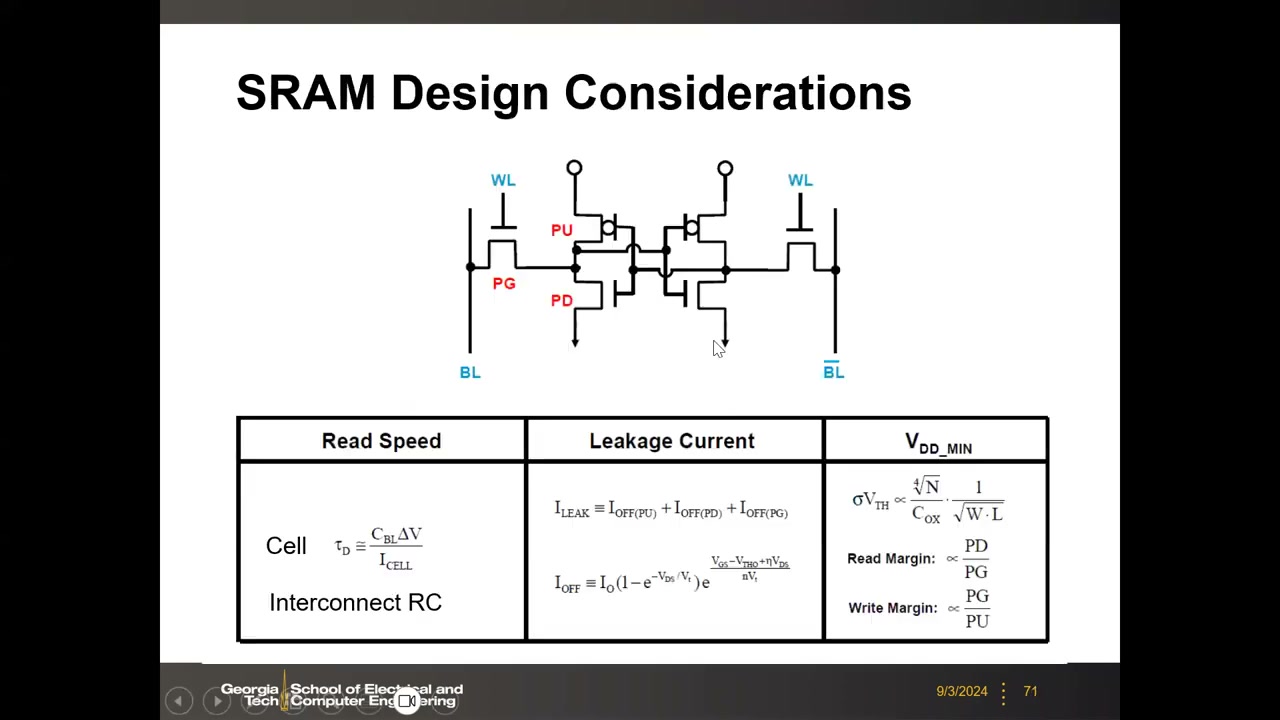
单元级三大设计指标汇总:
- 读延时:τD ≅ CBL·ΔV / ICELL(ΔV 典型 100–200 mV);阵列级还要叠加字线/位线互连 RC。SRAM 典型子阵列尺寸 32×32 到 256×256——1 Mb 级子阵列罕见,互连 RC 太大。
- 漏电:ILEAK ≡ IOFF(PU) + IOFF(PD) + IOFF(PG)——保持态下 6 管中有 3 管漏电(作业/考题),漏电功耗 = VDD × ΣIOFF。待机漏电是 SRAM 最大的功耗问题:大容量 cache 持续漏电耗电池,又不能断电(断电丢数据)。
- VDD_MIN:由阈值变异决定,σVTH ∝ 1/√(W·L)(见第 14 节)。
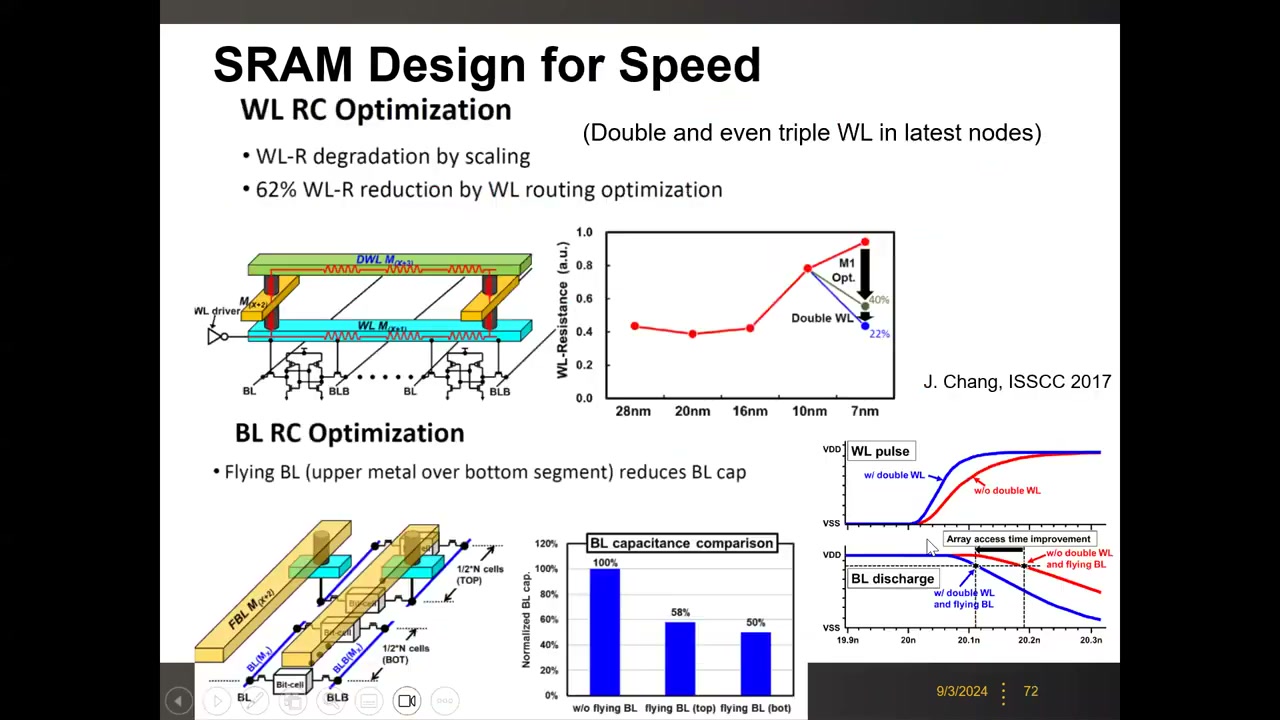
先进节点读速优化 P3 00:10:36(TSMC 7nm, ISSCC 2017):工艺微缩使字线电阻持续上升。Double WL(M1+M2 两层金属并联布字线,最新节点甚至 Triple WL)可降字线电阻 62%;Flying BL(上层金属跨接位线)把位线电容降到 50–58%。现代 SRAM 设计大量精力花在阵列级/互连级寄生优化。
漏电抑制技术 P3 00:14:04:保持态存在三类漏电——亚阈值 IOFF、GIDL(栅致漏极漏电,VGS<0 时带带隧穿,可高于 IOFF)、栅隧穿 IG(high-k/metal gate 后已可忽略)。对策:① 电场弛豫偏置——待机时降位线电压、抬虚地(如 1.5V 压差降到 0.5–1.0V),同时抑制多种漏电;② Dual-VT 单元——锁存 4 管用高 VT 切断漏电路径、pass gate 用低 VT 保速度,配合 boosted VDH 补偿稳定性,面积代价仅约 10%。
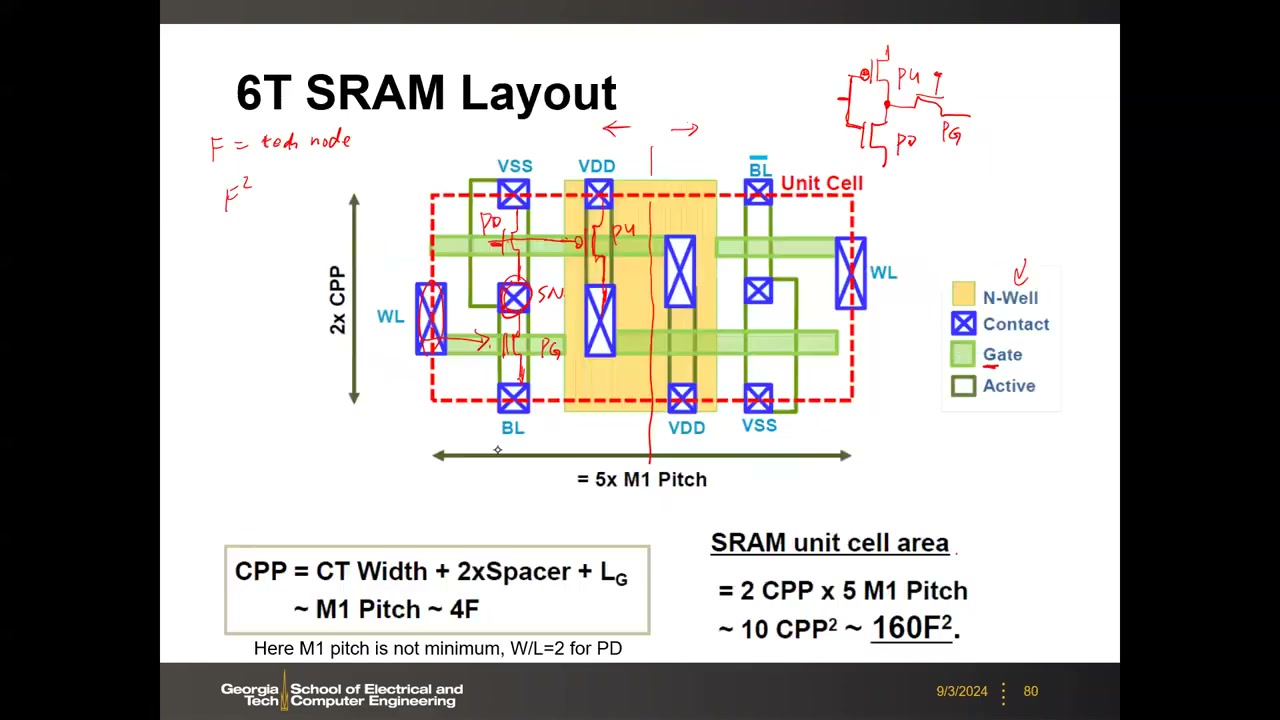
11. 6T 版图与 160F² 面积 P3 00:26:46
历史背景:350 nm 以前曾用 poly 负载 4T / TFT 负载等高密度单元(电阻无法关断,有直流漏电、非 rail-to-rail);250 nm 以后 6T 全 CMOS 成为主流——稳定性好、可降压、与逻辑工艺完全兼容。真正的水平缩放指标不是栅长 LG(130→20nm 期间几乎不缩),而是 CPP/CGP(接触栅距):CPP = CT 宽度 + 2×Spacer + LG,每 2 年缩 30%。
现代 6T wide-cell 版图(讲者强调"这页非常重要",考试要求识图):
- 识图方法:N-well 区域留给 PMOS → 上拉管(PU)在版图中间(接 VDD);与 PU 共栅(同一条 poly)的 NMOS 是 PD(反相器输入共栅);由 WL poly 控制的是 PG。
- 尺寸:水平 5 个 M1 pitch × 垂直 2 个 CPP;该版图管宽比 PD : PG : PU = 2 : 1 : 1。
- 经验关系:M1 pitch ≈ CPP ≈ 4F(适用于 65/40/28/22nm 等平面节点)→ 单元面积 = 2 CPP × 5 M1 pitch = 10 CPP² ≈ 160F²(高密度单元下限约 150–160F²;L1 提速版 4:2:1 约 300F²)。
- 90 nm 以下版图全面规则化:几乎全是直线和孔、所有栅极取向一致——因为特征尺寸远小于光刻波长的一半。45 nm 真实设计(H. Nii, IEDM 2006):单元 0.72 × 0.345 = 0.248 µm²。
12. 光刻与图形化:193nm 延寿到 EUV P3 00:40:25
主流光刻长期使用 193 nm(ArF)波长,基础分辨率 Resolution = k₁·λ/NA ≈ λ/2,原理上只能做 ~90 nm 特征,但业界用三类技术把 193 nm 用到了 14 nm 以下:
- 浸没式光刻:镜头与晶圆间填充高折射率液体,提高 NA。
- OPC(光学邻近校正)/计算光刻:制掩模时预先反向补偿光学畸变(如线端加凸起),抵消光刻胶图形端部圆化。
- 双重/多重图形化:① line+cut 流程——第一次只曝光单方向线条,第二次用切割掩模垂直切断(Intel 45nm SRAM 实例);② spacer 自对准技术——先做台阶(mandrel)→ 保形沉积薄膜 → 各向异性刻蚀留侧墙 → 去台阶,用侧墙作硬掩模可得几 nm 宽特征(25 年前 Berkeley 胡正明组就是用此法制造第一批 FinFET 的鳍)。谱系:SADP(2×)→ SATP(3×)→ SAQP(4×)。
sub-7nm 节点业界已转向 EUV(极紫外,ASML,波长约 13.5 nm)量产。

13. 单元面积缩放趋势及其饱和 P3 00:51:08 P5 00:10:21
6T 单元面积长期"虔诚地"每 2 年缩 0.5×(Intel:65nm 0.570 → 45nm 0.346 → 32nm 0.171 → 22nm 0.092 µm²),与 CGP × M1 pitch 乘积强相关。但近年明显放缓:14nm 0.0588 → 10nm 0.04 → 7nm 0.0262 → 5nm 0.021 → 3nm 0.0199 µm²——缩放几乎饱和。
三大厂对比(P5 汇总):5nm 时 SRAM cell ≈ 2 CPP × 6 MMP ≈ 0.021 µm²;Samsung 7nm→5nm 面积不再缩小(0.0262 → 0.0262)——这是引出 GAA、BS-PDN、CFET、DTCO 等"延续缩放手段"的核心动机。
| 节点 | Intel (µm²) | Samsung (µm²) | TSMC (µm²) |
|---|---|---|---|
| 14/16nm | 0.0588 | 0.0645 | 0.07 |
| 10nm | 0.0312 | 0.040 | 0.042 |
| 7nm | — | 0.0262 | 0.027 |
| 5nm | — | 0.0262 | 0.021 |
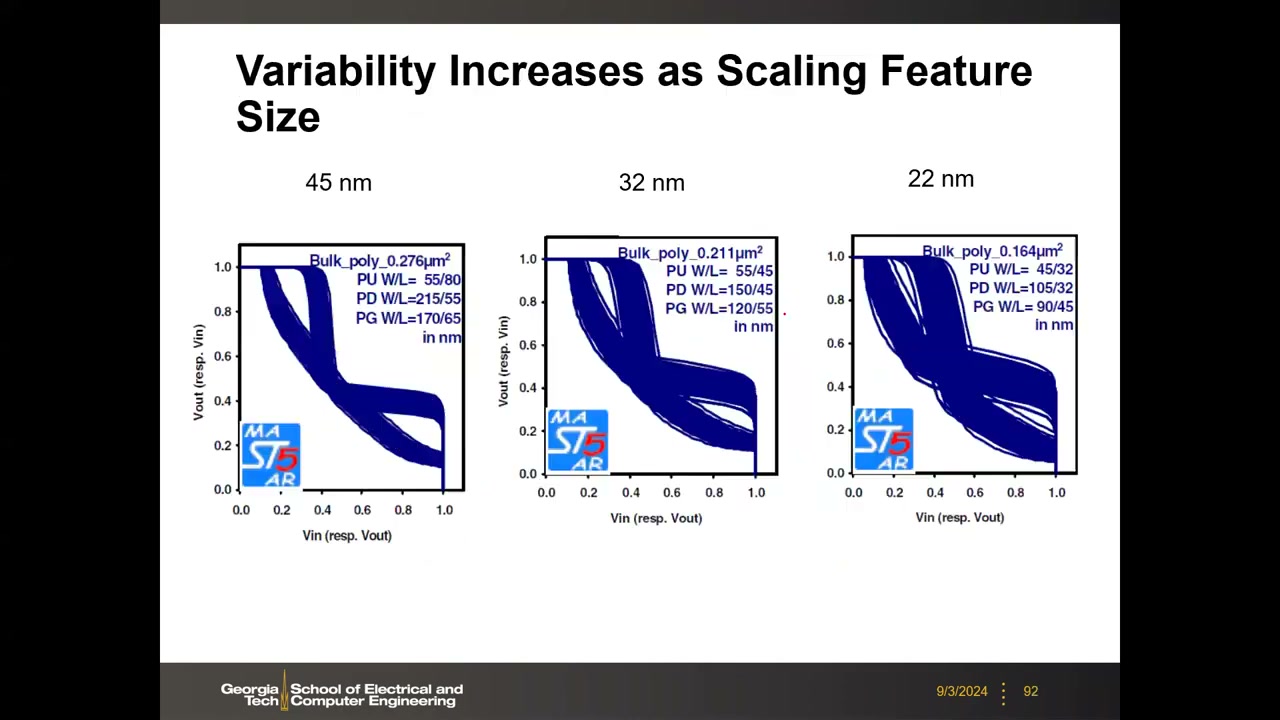
14. 空间变异性:RDF / LER / WFV 与 HKMG P3 00:58:32
失配使蝶形曲线畸变(SNM 取两眼较小者);阵列统计叠加后开口随样本增多而收窄,低压时更严重——低压 + 变异是先进 SRAM 设计的大挑战。SRAM 对变异特别敏感:① 用最小可行尺寸晶体管;② 读操作不达全逻辑摆幅。变异来源分两类(A. Asenov 框架):空间型(器件间不同):RDF、LER、WFV;时间型(同一器件随时间变):RTN、BTI(见第 15 节)。
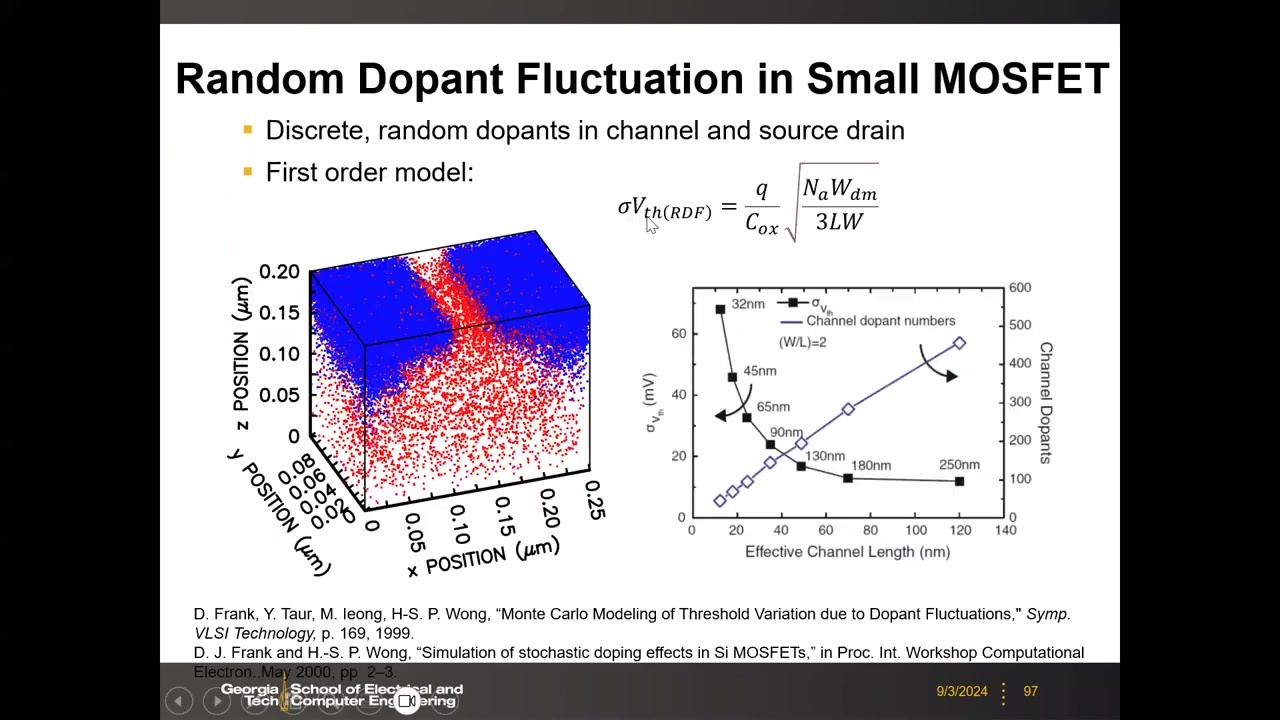
- RDF(随机掺杂涨落) P3 01:02:09:一阶公式 σVth(RDF) = (q/Cox)·√(Na·Wdm / (3·L·W)),即 σVth ∝ 1/√(LW)。沟道从 250nm 缩到 32nm 节点,掺杂原子数从约 500 个降到 20–30 个,σVth 升到 >60 mV。掺杂稀疏处势垒塌陷形成渗流(percolation)漏电路径(同为 130 个掺杂原子的两管,Vth 可差 0.97V vs 0.57V)。Pelgrom 图:σVth 对 1/√(LW) 作图,RDF 预测为过原点直线;小尺寸实测点系统性偏离直线上方——说明存在 RDF 之外的变异源。
- LER(线边缘粗糙度) P3 01:08:23:光刻胶是聚合物,分子尺寸几 nm,造成约 2–3 nm 的固有边缘粗糙(典型 LER 3–5 nm,与线宽无关)。200 nm 线宽时只占 ~1%,缩到 20–30 nm 就是 10–15% 的变异——器件尺寸已与光刻胶分子尺寸可比,LER 不可避免,造成有效 LG 的器件间差异。
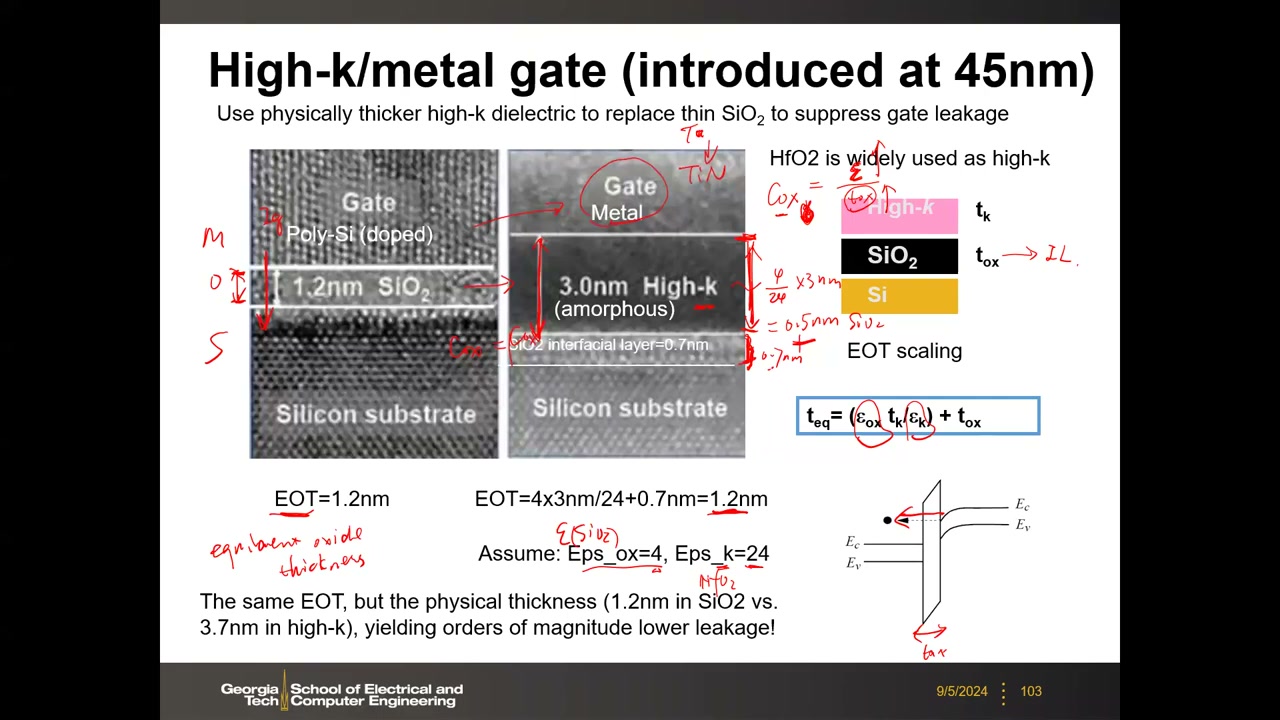
- HKMG 与 EOT P4 00:01:05:SiO₂ 减薄到 1–2 nm 时直接隧穿使栅漏电激增;45 nm 起用 high-k(HfO₂,K≈24 ≈ 6×SiO₂)+金属栅替代。EOT 公式:teq = (εox·tk / εk) + tox。算例:3 nm HfO₂ 等效 4×3/24 = 0.5 nm SiO₂,加 0.7 nm 界面层 → EOT = 1.2 nm,与 1.2 nm 纯 SiO₂ 同 Cox,但物理厚度 3.7 nm,漏电低几个数量级。
- WFV(功函数变异) P4 00:09:50:金属栅(TiN 基)是多晶的,不同晶粒取向功函数不同(4.40–4.60 eV)→ HKMG 工艺新增的 Vth 随机源。多 Vt 工程(RMG):TSMC N5 每种 N/P 器件提供 7 档 Vt。各独立来源按方差合成:σVth(total)² = σVth(RDF)² + σVth(LER)² + σVth(WFV)²(课堂算例:30/20/20 mV → 总 σ = √(30²+20²+20²) mV)。
15. 时间变异性:RTN 与 NBTI P4 00:15:38
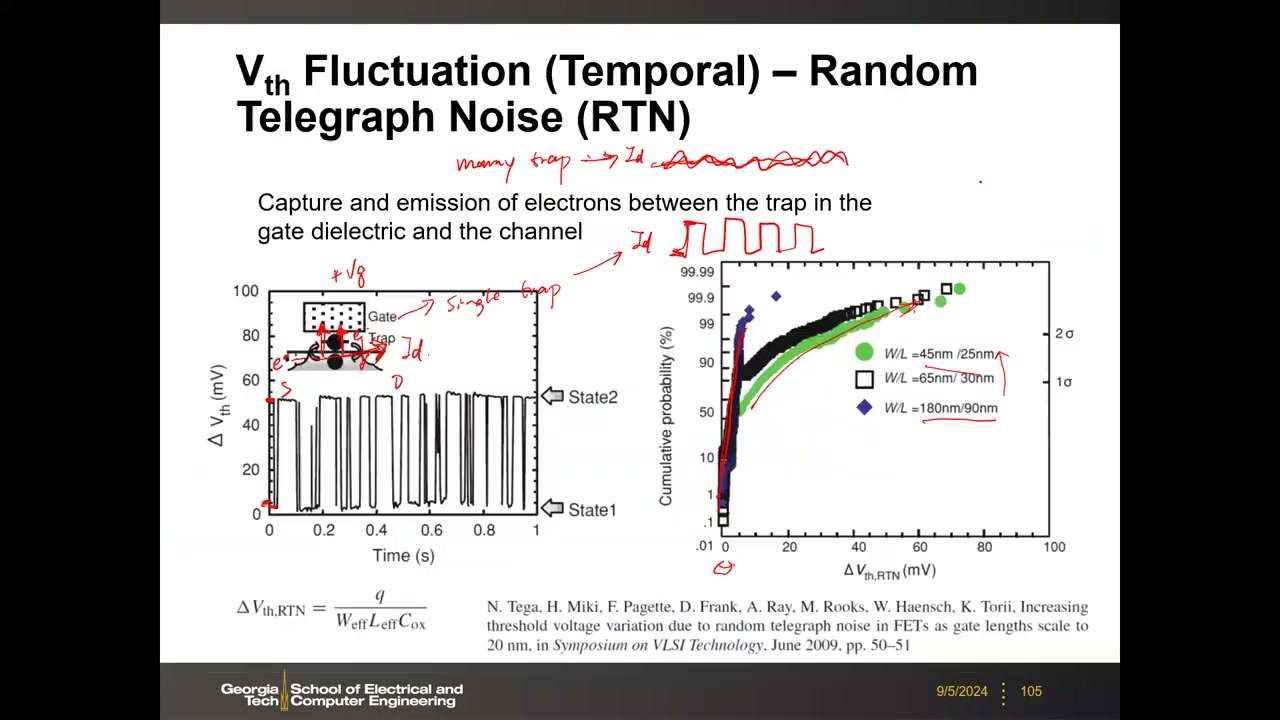
RTN(随机电报噪声):栅介质中的单个缺陷(如氧空位)随机俘获/释放沟道电子,使漏电流呈两电平开关波形(多陷阱大器件则平均化为普通噪声)。单电子俘获引起的阈值移动:ΔVth,RTN = q / (Weff·Leff·Cox)——与器件面积成反比,尺寸越小越严重。实验(VLSI 2009):W/L 由 180/90 nm 缩至 45/25 nm 时分布出现长尾,部分采样 ΔVth 达数十 mV。
BTI / NBTI(偏压温度不稳定性) P4 00:22:46:长期老化效应,电压/温度应力下 Vth 随使用时间漂移。NBTI 针对 PMOS(负栅压)、PBTI 针对 NMOS;硅基 HKMG 节点 NBTI 更严重。加速老化测试在高于标称的栅压与高温下拟合经验幂律 ΔVth,NBTI ≈ A·tn 做寿命预测。对 SRAM 的影响:蝶形曲线随应力时间收缩,SNM 不是静态数,会随时间退化——设计须按产品等级(手机 3–5 年 vs 服务器/车规更长)预留寿命裕量。RTN 与 BTI 的区别:RTN 来自初始固有陷阱,BTI 是应力产生的新陷阱。
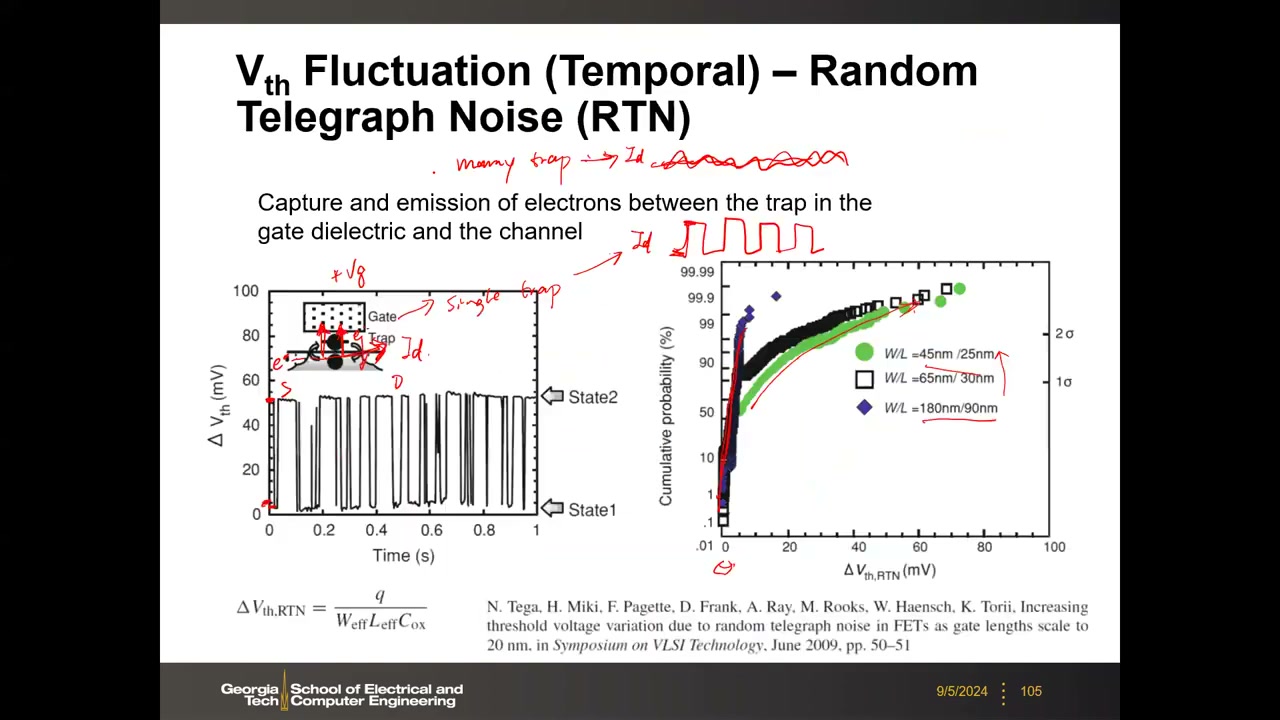
16. 软错误:辐射、SER 与多位翻转 P4 00:28:16
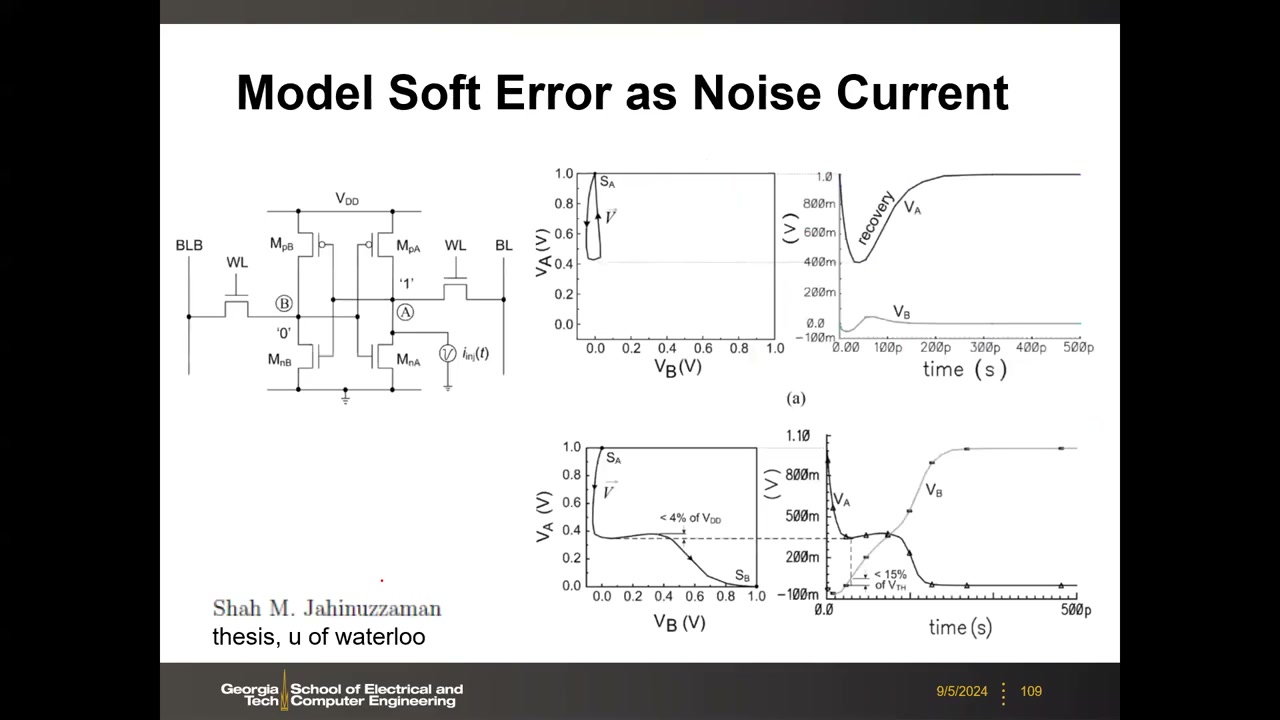
辐射使 SRAM 数据翻转,来源两类:① α 粒子(封装材料同位素衰变,可屏蔽);② 宇宙射线中子/重离子(无法屏蔽,更严重;高海拔与卫星上通量更高,航天芯片需抗辐射设计)。高能粒子击中硅衬底沿径迹激发电子-空穴对;反偏 PN 结是敏感区——结电场使电荷分离形成光电流(击中中性体区的对会复合,净电流为零)。这是暂时性失效,下次写操作即可恢复,故称"软"错误。
电路建模 P4 00:32:18:把粒子打击等效为挂在存"1"漏端的瞬态噪声电流源 iinj(t)(持续约 10–100 ps、幅值可达 mA 量级),用 SPICE 做动态仿真:电荷不足则沿轨迹恢复,越过 separatrix 则像一次"写入"翻转。
SER 缩放趋势 P4 00:37:05:判据是注入电荷是否大于临界电荷 Qs ∝ Cs·(VDD−VT)(SRAM 的 Cs 全是寄生电容)。缩放时敏感结面积变小(收集概率降)与节点电容变小(更易翻)两效应抵消 → SRAM 单元级 SER 大致不变,但系统级随 cache 容量增大而上升。DRAM 的存储电容是专门设计的、基本不随节点缩放 → 单元级 SER 急剧下降。所以今天软错误主要是 SRAM 问题。
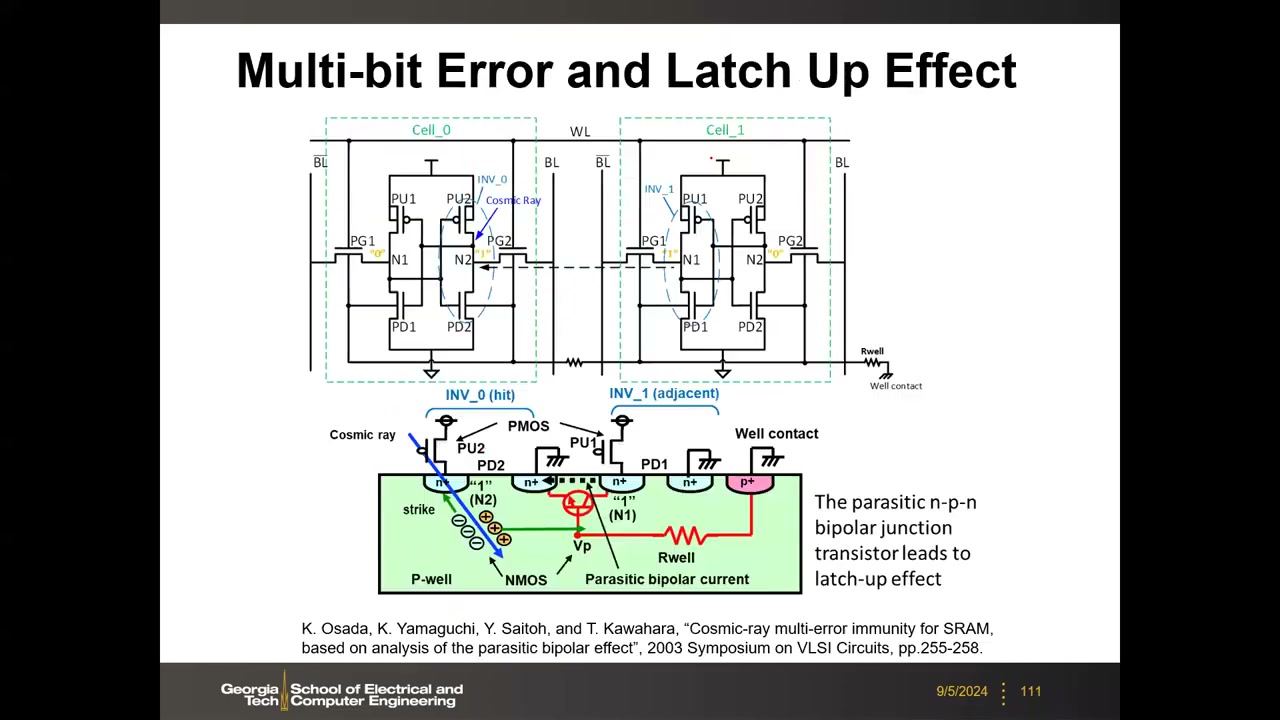
多位错误与寄生 BJT 闩锁 P4 00:42:02:一次重离子打击的空穴流经衬底电阻形成 IR 压降、局部抬升衬底电位,开启 P 衬底/n+ 源漏构成的寄生 NPN BJT,使相邻多个存"1"单元同时放电翻转(衬底电位沿途衰减,直到不足以开启 BJT)。多位翻转(MBU)对 ECC 极不利(如 ECC 只能纠同行 2 位却翻了 3 位),且随缩放波及更多单元。对策:冗余设计,或改用 SOI 工艺(消除共享体硅通路,大幅降低错误率,但更贵)。
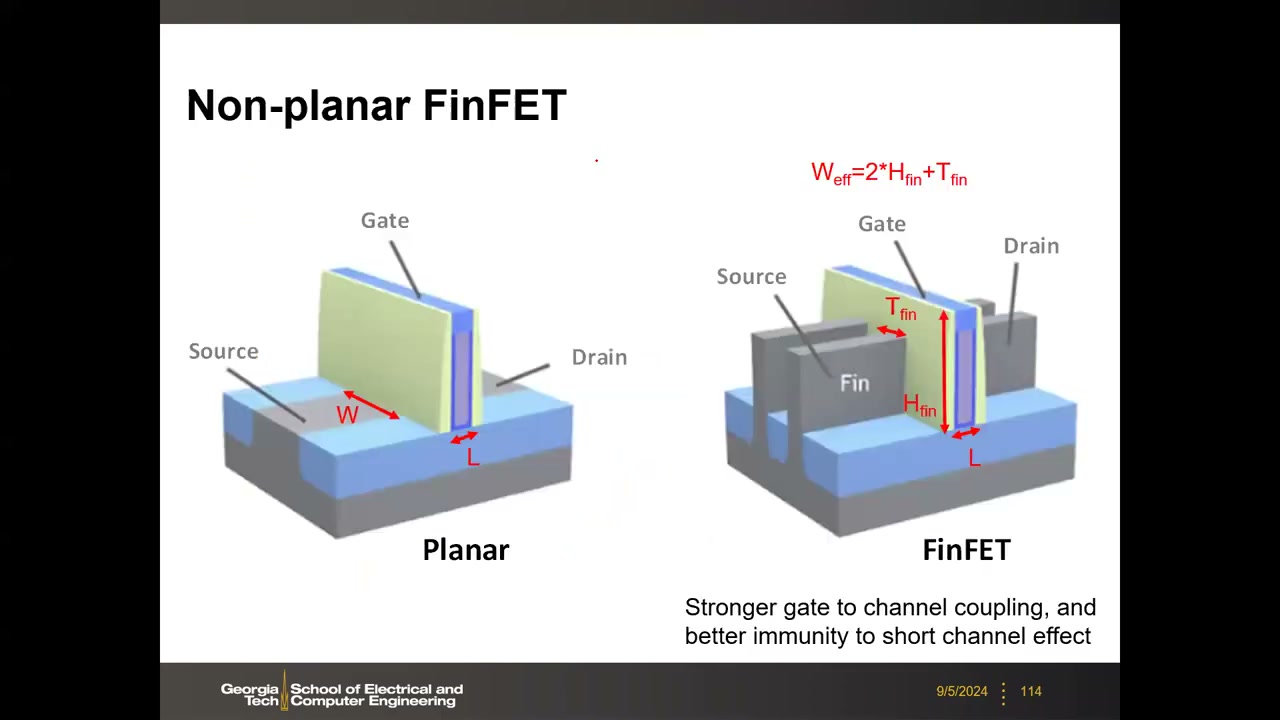
17. FinFET 时代的 SRAM P4 00:49:15
22 nm 节点起平面体硅晶体管被 FinFET 取代:薄硅鳍直立于衬底,栅从三面(两侧+顶)包裹沟道。短沟道效应的本质是漏极对源-沟道势垒的干扰,FinFET 通过几何工程获得更强的栅-沟道耦合与更好的短沟道免疫力。关键公式(考试重点):Weff = 2·Hfin + Tfin(电流沿鳍的三个表面导通);多鳍并联时 Weff = (2Hfin+Tfin)×N,物理占宽 Wphy = N×Pfin(鳍距)。
历史与 Intel 22nm 量产 P4 00:54:58:1998 年 Berkeley 胡正明(Chenming Hu)团队发表首个 NMOS FinFET(Lg=30nm);2012 年 Intel 22nm 首次量产(命名 Tri-Gate)。Intel 22nm 实测:鳍宽约 8 nm、鳍高 34 nm → Weff = 34×2 + 8 = 76 nm(课堂手算);栅距 90 nm ≈ 4F(验证 4F 经验规律);SS ≈ 69–72 mV/dec(接近 60 的理论极限)、DIBL ≈ 46–50 mV/V。若鳍距仅 50 nm 则 Weff(76) > Wphy(50)——同样占宽下 FinFET 电流大于平面管。
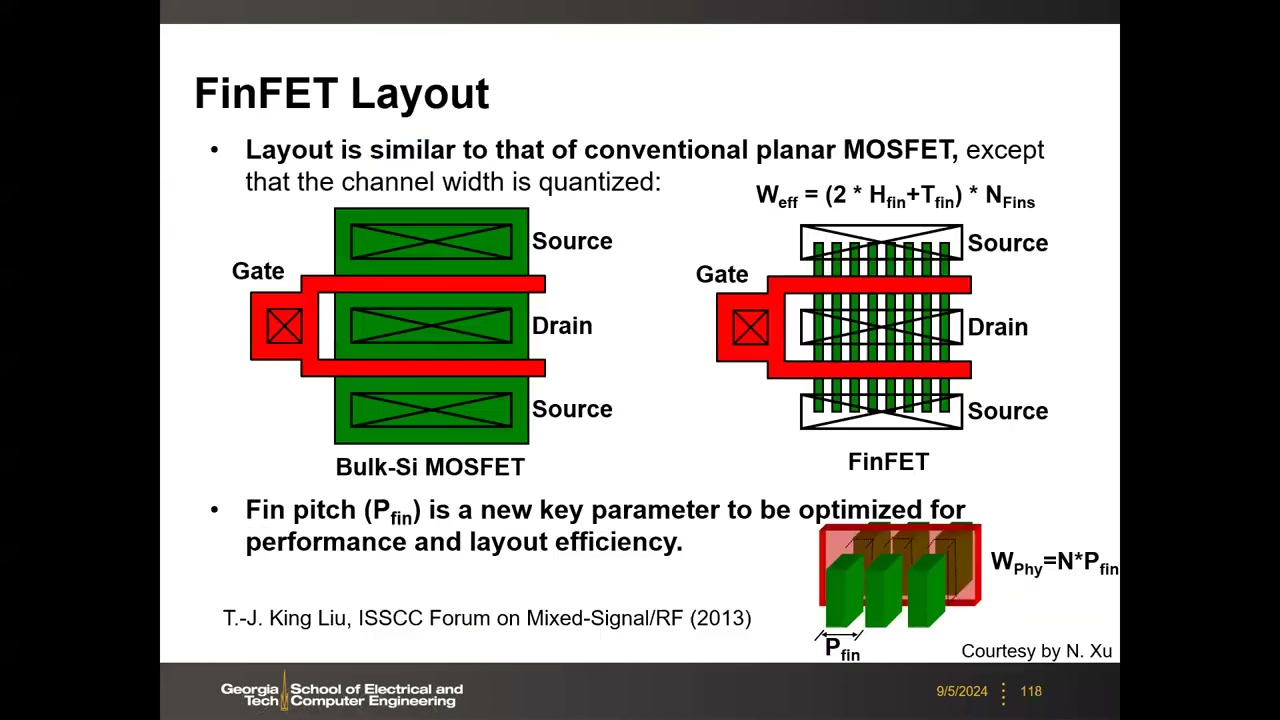
FinFET SRAM 优劣势 P4 01:08:15:优——SS 改善(同 IOFF 下 VTH 更低、读写电流更高)、DIBL 降低(VTC 更陡 → SNM 更大)、变异降低;鳍基本不掺杂,RDF 几乎消失(VTH 改由金属栅功函数设定),但新增鳍 LER 变异源。劣——宽度量化:W 只能取整数根鳍,设计灵活性下降、VTH 工程困难。平面用 W 比实现 PD:PG:PU = 2:1:1,FinFET 改用鳍数实现(PD 2 鳍 : PG 1 鳍 : PU 1 鳍)。
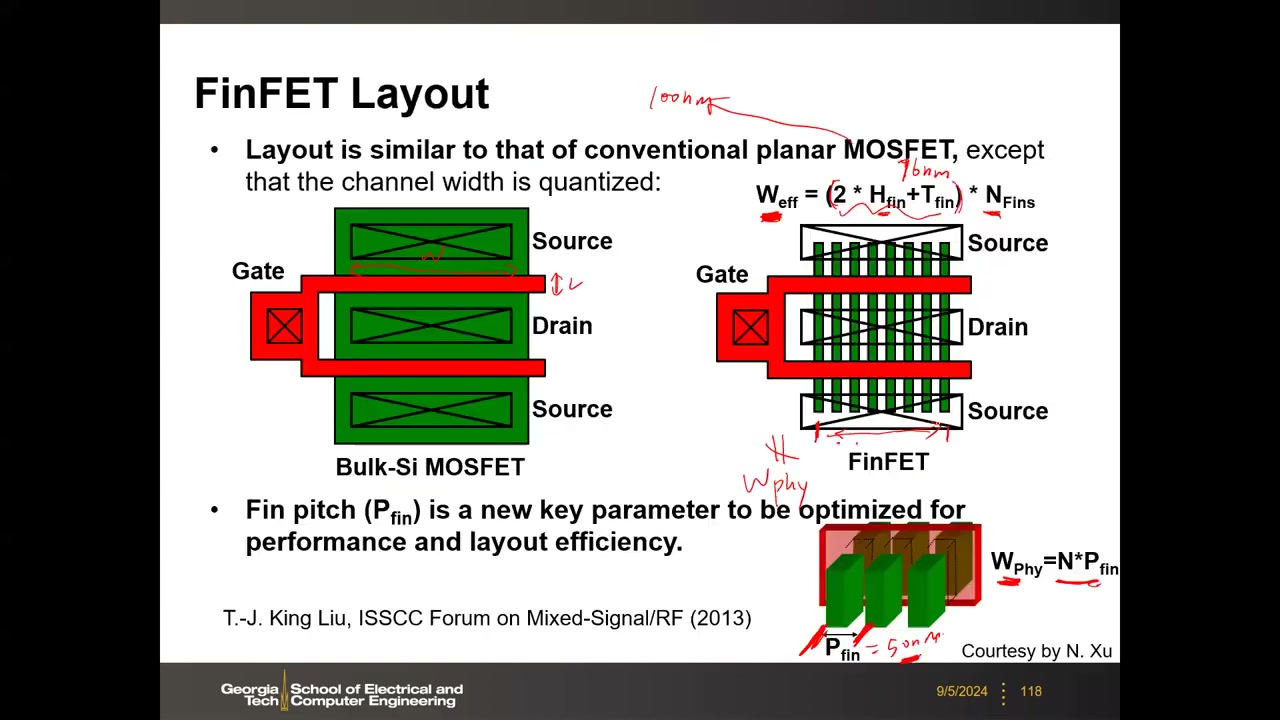
鳍配比设计惯例与各代实例 P5 00:00:03:Intel 22nm 同一工艺提供三种 cell 服务不同 cache 层级;跨厂商通用规则——高密度(HD)cell 永远 1:1:1,高性能/高电流 cell 为 2-2-1(PD 2 / PG 2 / PU 1)。FinFET 优异的短沟道控制使待机漏电比平面降低 4–5 倍,高速单元 1V 下达 4.6 GHz、Vmin 改善约 150 mV。
| Intel 22nm 单元 | 面积 (µm²) | 鳍配比 PD:PG:PU | 用途 |
|---|---|---|---|
| High Density | 0.092 | 1:1:1 | L3 等大容量缓存 |
| Standard | 0.108 | 2:1:1 | 通用 |
| High Speed | 0.130 | 3:2:1 | L1 等高速缓存 |
鳍尺寸缩放规律 P5 00:03:19:鳍越来越高、越来越薄、间距越来越小——鳍高增加直接提升单鳍电流(Weff = 2Hfin+Wfin),为后文"鳍减员"DTCO 埋下伏笔。TSMC 5nm 起 PMOS 鳍改用 SiGe 沟道提升空穴迁移率。
| 节点 | 22nm | 14nm | 10nm | 7nm |
|---|---|---|---|---|
| Fin height (nm) | 34 | 37 | 42 | 52 |
| Fin width (nm) | 8 | 8 | 6 | 6 |
| Fin pitch (nm) | 60 | 48 | 36 | 30 |
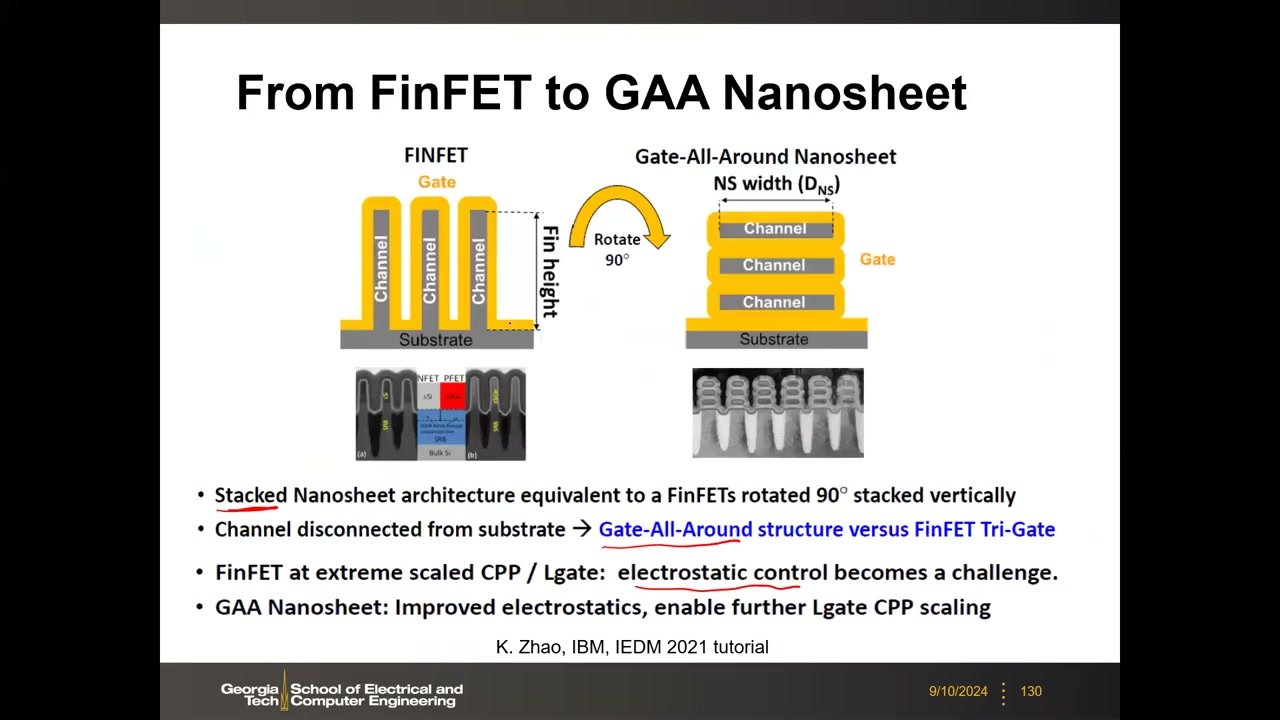
18. GAA 堆叠纳米片 P5 00:11:02
FinFET 缩放放缓后,业界再次改变器件结构:Gate-All-Around (GAA) 堆叠纳米片——可理解为把 FinFET 旋转 90° 再水平堆叠,栅从四面完全包裹沟道(FinFET 只有三面),静电控制最优,允许进一步缩短 Lgate/CPP。Samsung 3nm(2023)已量产 GAA;TSMC 与 Intel 在路线图上。
核心特性 P5 00:13:08:① 可堆叠多层沟道,单位占地电流高于 FinFET;② 有效宽度连续可调——教授板书公式 Weff = (D + T) × 2 × N(D 纳米片宽度、T 厚度、N 层数;每层周长 2(D+T))。纳米片宽度由版图光刻定义,可连续设计,摆脱鳍量子化限制。
工艺流程 P5 00:17:28:SiGe/Si 超晶格交替外延(最关键一步)→ 鳍状图形化与 STI → 伪栅 → spacer 与内侧墙(inner spacer)→ 双源漏外延 → 沟道释放(选择性化学刻蚀去除 SiGe 牺牲层,硅沟道悬空)→ HKMG 四面再生长 → MOL/BEOL。SiGe 作牺牲层是因为与硅晶格匹配可外延、且刻蚀液只攻击 SiGe 不攻击 Si。
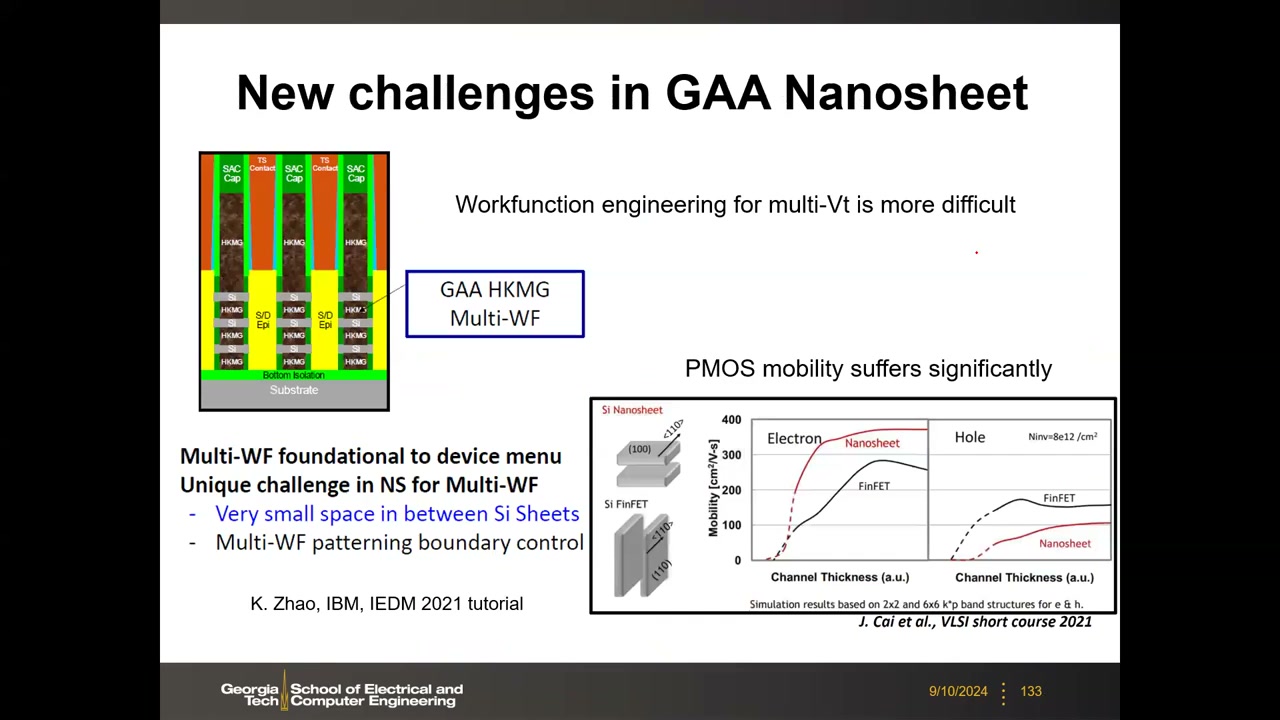
新挑战 P5 00:23:49:① 多功函数工程更困难——两层硅片之间空间由牺牲层厚度固定,金属栅厚度无法自由调节;② PMOS 迁移率退化——纳米片表面为 (100) 面利于电子、损害空穴(FinFET 侧壁 (110) 反而利于空穴),最新论文提出对 PMOS 做 SiGe 包覆等对策。
19. 背面供电(BS-PDN)与 CFET P5 00:26:17
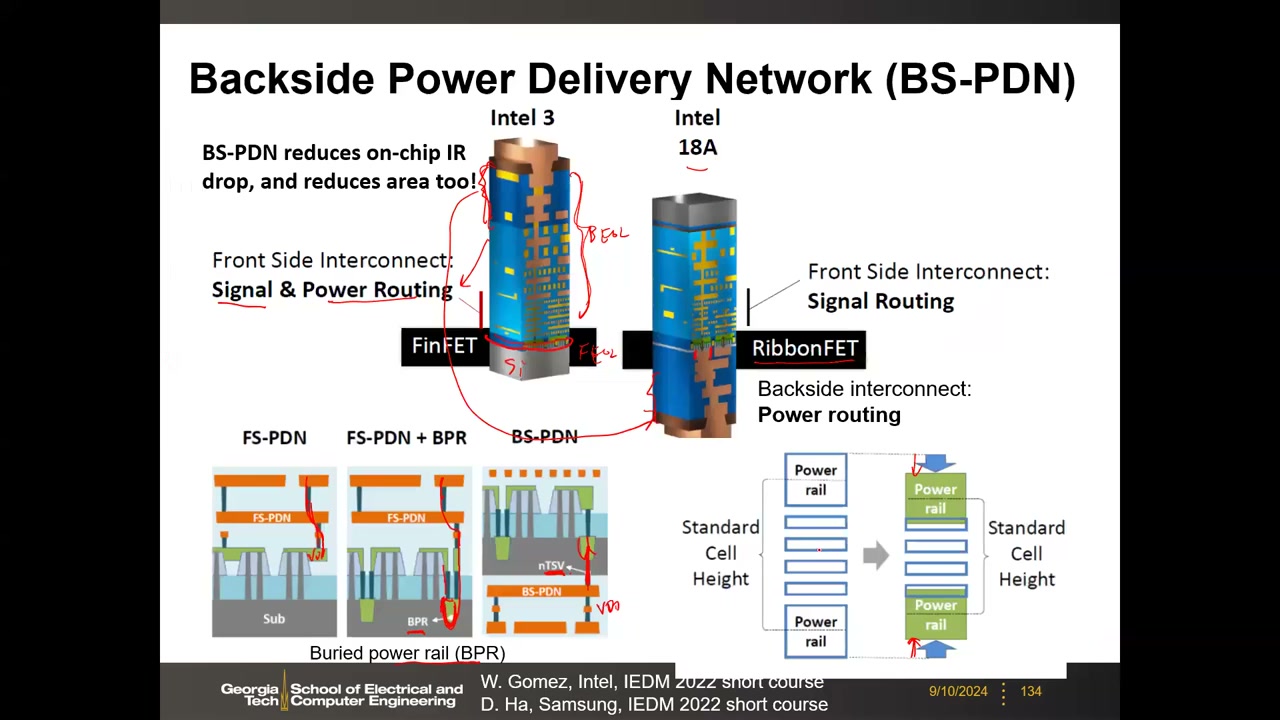
BS-PDN(背面供电网络):传统芯片 15–17 层 BEOL 金属同时承担信号与电源,布线拥塞。演进路径:FS-PDN(全正面)→ FS-PDN + BPR(埋入式电源轨,电源仍从正面进,中间方案)→ BS-PDN(电源完全从晶圆背面进,正面专走信号)。关键工艺:晶圆背面减薄(数百 µm → 约 1 µm),翻转后在背面做 3–4 层电源金属,用 nTSV(约 90–100 nm 见方的纳米硅通孔)连接正反面。收益:降低 IR drop、缩减标准 cell 高度、缓解正面布线拥塞。Intel 18A 即采用 RibbonFET(堆叠纳米片)+ PowerVia(背面供电)。
散热挑战 P5 00:34:49:传统倒装焊约 95% 热量经厚硅衬底(~750 µm)→ TIM → IHS 散出;BS-PDN 后 die 必须面朝上,硅已减薄到 <1 µm,热量须先穿过导热差的正面 BEOL(约 8 µm 金属/介质混合物)再到额外键合的硅载体晶圆——散热不如传统方案,仍是商业化的首要系统级风险,尚无最终解决方案。
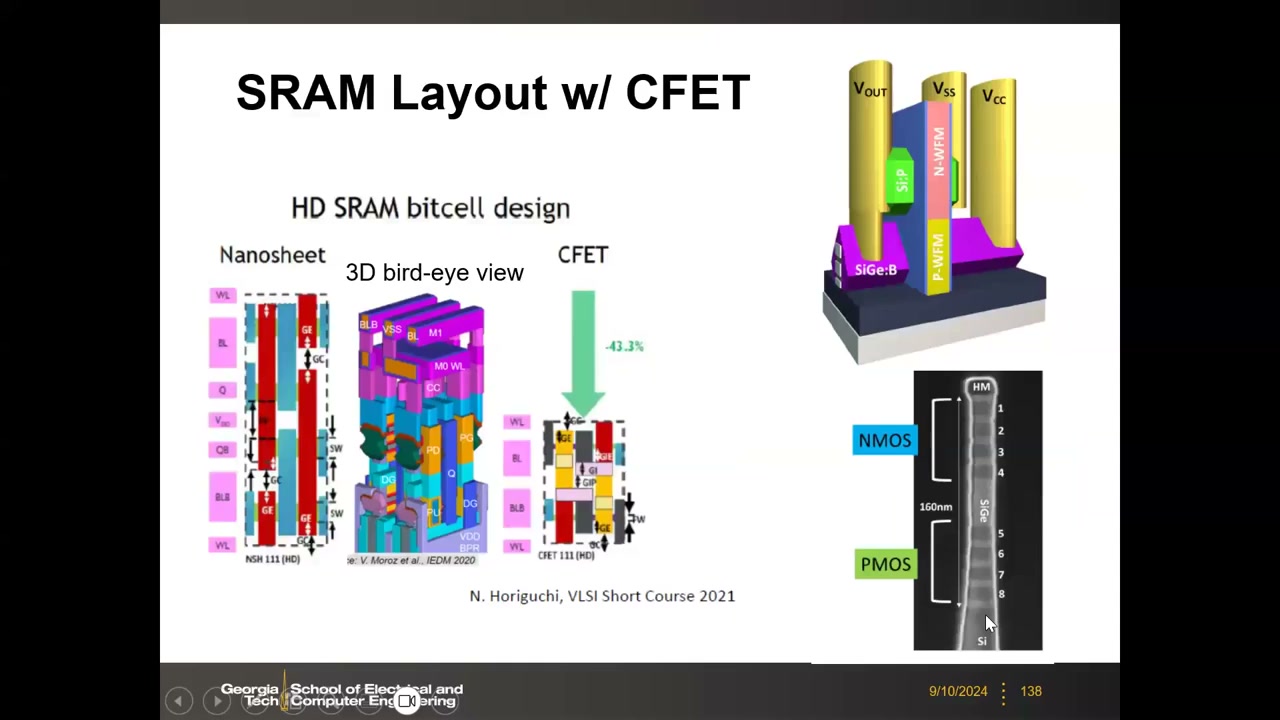
CFET(互补 FET) P5 00:39:59:晶体管演进路线 PlanarFET → FinFET(2011)→ GAAFET(2023,Samsung 3nm)→ CFET(约 2032?)——在纳米片框架内把 NMOS 垂直堆叠在 PMOS 之上。对 SRAM 的意义:利用第三维度,HD SRAM 面积可再缩约 40%(幻灯片 −43.3%)。已有 4 层堆叠的 monolithic CFET 演示,2023 IEDM 上 Intel 与 TSMC 均有论文;教授预计业界 8–10 年内走到 CFET。变异性展望:GAA 沟道厚度由外延(精度高)而非光刻定义,σVt 有望低于 FinFET 延长线(FinFET 在 2nm 节点变异已"失控")。
20. DTCO / STCO 与 AMD 3D V-Cache P5 00:44:22
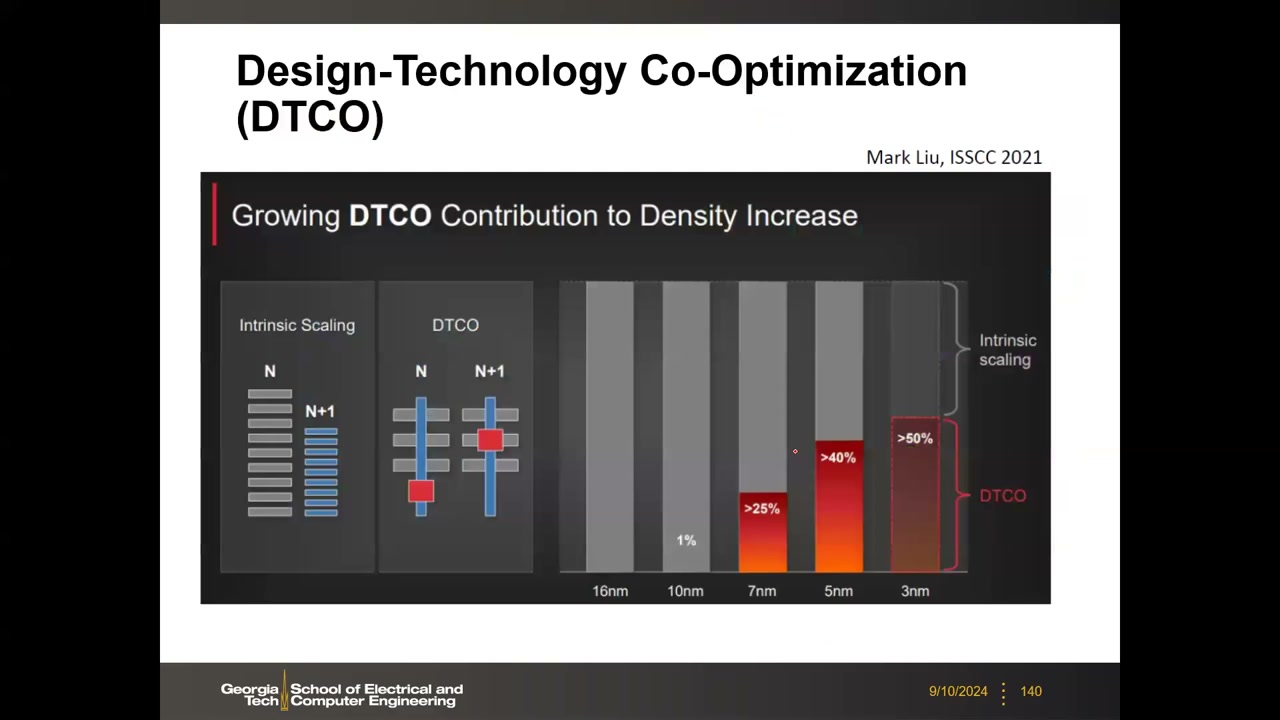
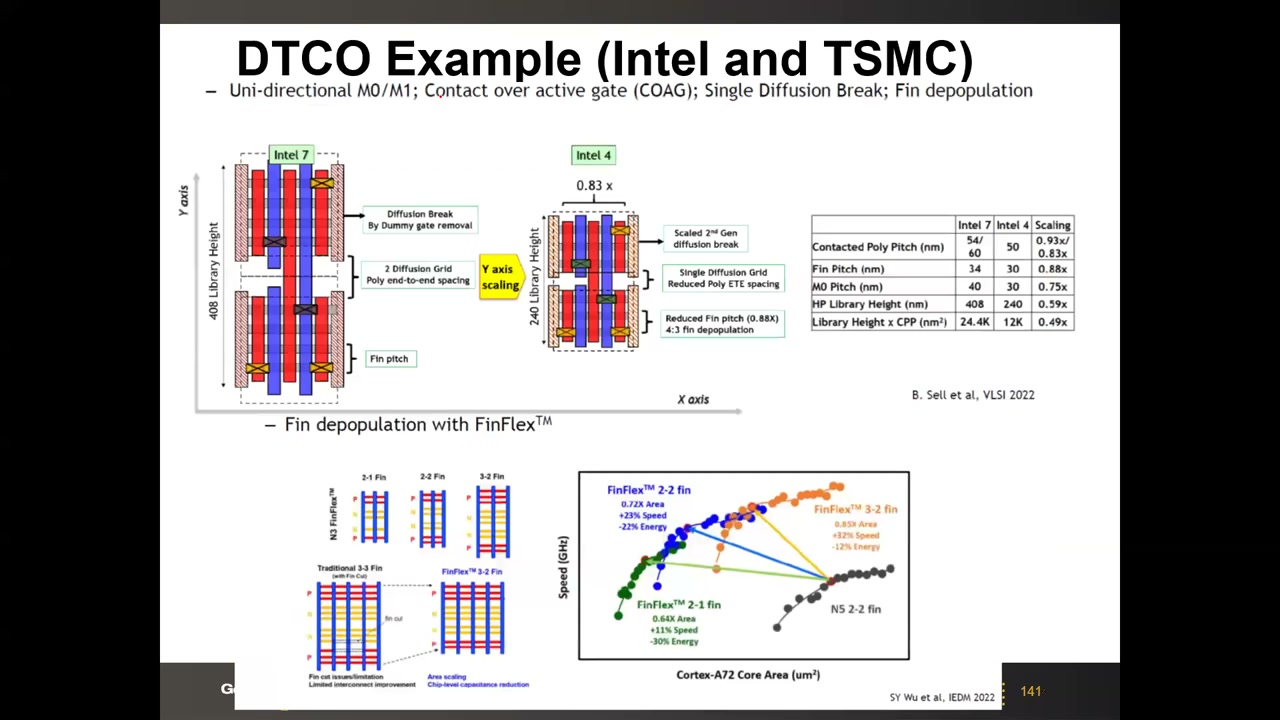
DTCO(设计-工艺协同优化):协同利用晶体管特性、版图效应与设计规则提升密度。关键数据(TSMC, ISSCC 2021):密度提升中 DTCO 的贡献——10nm 约 1%、7nm >25%、5nm >40%、3nm >50%——"本征缩放"越来越难,DTCO 取而代之成为密度增长主力。
实例 P5 00:46:53:通用手段包括单向 M0/M1 布线、COAG(栅接触移到有源区上方省面积)、单扩散隔断、鳍减员(fin depopulation,单鳍电流增强后 4 根鳍减到 3 根)。TSMC FinFlex(N3):标准 cell 可混搭 2-1、2-2、3-2 鳍组合,同一设计中按需选择性能/功耗/密度取向。
| 指标 | Intel 7 | Intel 4 | 缩放比 |
|---|---|---|---|
| Contacted Poly Pitch (nm) | 54/60 | 50 | 0.93×/0.83× |
| Fin Pitch (nm) | 34 | 30 | 0.88× |
| M0 Pitch (nm) | 40 | 30 | 0.75× |
| HP Library Height (nm) | 408 | 240 | 0.59× |
| Library Height × CPP (nm²) | 24.4K | 12K | 0.49×(面积减半) |
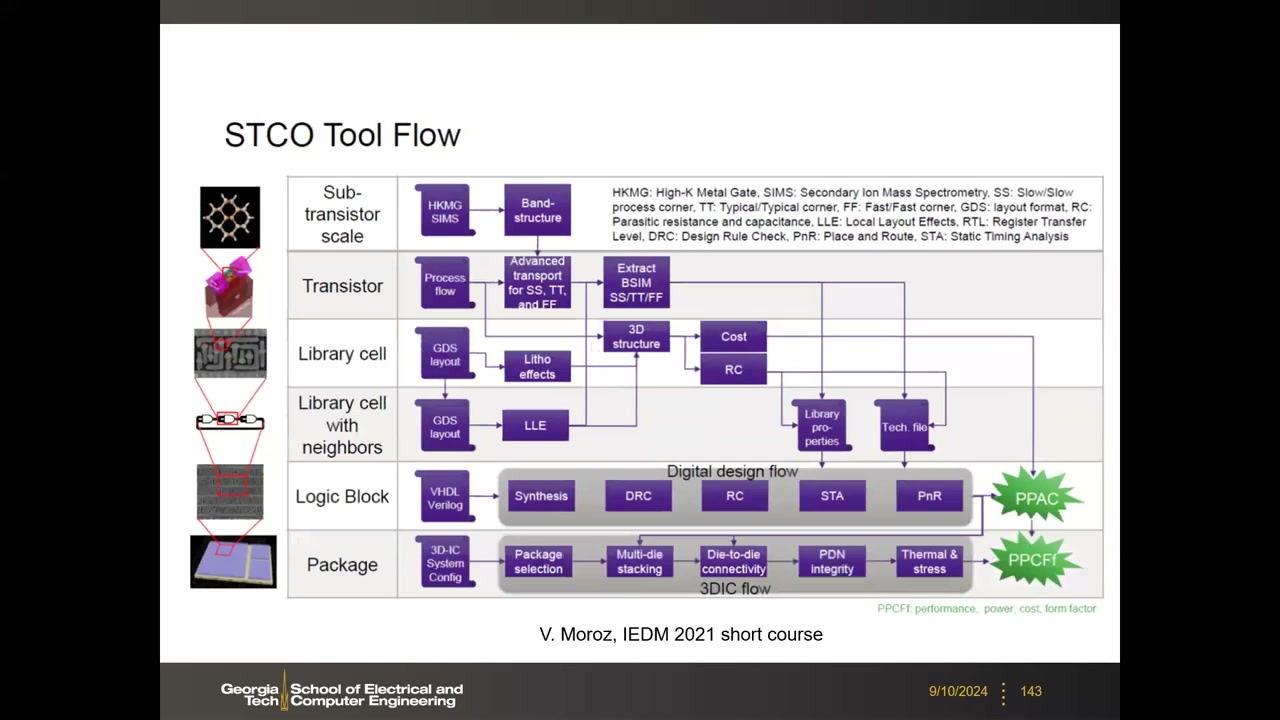
STCO(系统-工艺协同优化) P5 00:49:16:在 DTCO(从能带结构 → BSIM 模型 → 库单元 → 数字流 → PPAC 输出)之上再加封装层级——多 die 堆叠、die-to-die 互连、PDN 完整性、热与应力(3D-IC flow),输出 PPCF。
AMD 3D V-Cache:SRAM 进入 3D 键合时代 P5 00:51:18:第一代(Zen 3)把 64MB 的 7nm 纯 SRAM die(L3D)以混合键合(hybrid bonding)叠在 CCD(自带 32MB L3)背面,总计 96MB L3;带宽超 2 TB/s,延迟仅增加 4 个时钟周期。L3D 恰好覆盖 CCD 上功率密度低的 L3 区域以规避热问题,CPU 核心上方放结构 die 提供支撑与散热。第二代(Zen 4)底部 CCD 改为 5nm,顶部仍为 7nm SRAM die——证明"SRAM die 与逻辑 die 分离 + 3D 堆叠"是 SRAM 容量扩展的现实路径。
本讲收尾(Summary,P5 00:53:00):SRAM 随 CMOS 逻辑工艺"免费"获得;特殊设计规则实现高密度版图;器件参数变异影响单元稳定性且随尺寸/电压缩放恶化;变异与软错误越来越重要。三大趋势:电路+器件联合提升稳定性、DTCO 助力缩放;FinFET SRAM → 堆叠纳米片 SRAM;3D 集成(SRAM die 与逻辑 die 分离,TSV+混合键合堆叠)。这些手段至少能把缩放再延续十年。
本讲要点总结
- 6T SRAM = 交叉耦合反相器(PU×2 + PD×2)+ 两个 NMOS pass gate;N1/N2 互补存储,BL/BL̄ + WL 完成读写;Hold 时只靠锁存正反馈保持数据。
- 读稳定性约束:读路径 PG+PD 串联分压抬升"0"节点 → β ratio = (W/L)PD/(W/L)PG 要大(PD 强、PG 弱),否则正反馈导致读扰动翻转。
- 写由"1"→"0"转变发起(经 PU—PG 分压拉低存 1 节点),"0"→"1"被读约束设计为不发生 → γ ratio = (W/L)PU/(W/L)PG ≈ 1 即可(μn > μp 保证 PG 强、PU 弱)。
- 读速度一阶模型:Δt = C_BL×ΔV/I_read;典型 50 fF、100 mV、10 μA → 0.5 ns ≈ 2 GHz;SA 需 ΔV ≈ 100–200 mV,SAEN 必须等 ΔV 建立后才使能。
- SNM = 蝶形曲线最大内嵌正方形的边长(= 对角线 D1/√2,不是对角线本身);失配时取 min[SNML, SNMR];默认 SNM 指最坏的 Read SNM;经验值 150–200 mV 足够、<100 mV 棘手。
- N 曲线与蝶形曲线本质等价,但同时给出 SVNM(电压)与 SINM(电流)裕度、无需后处理,适合在线测试;SPNM = SINM × SVNM。
- 静态分析对 read/hold 悲观、对 write 乐观:SNM 是无限脉宽的 DNM;写要求 TW > Tacross,否则写失败——Shmoo 图上高频角失败是写失败、低压角失败是读失败。
- 读写冲突根源是共享 pass gate;对策:Read-Assist(降 WL)、Write-Assist(负位线 / 降 cell VDD)、RMW,或 8T 单元彻底解耦读写路径(Read SNM = Hold SNM,代价面积)。
- 保持态 6 管中 3 管漏电(亚阈值 + GIDL + 栅隧穿);电场弛豫偏置与 Dual-V_T 单元抑制待机功耗;HKMG(EOT = ε_ox·t_k/ε_k + t_ox)使栅隧穿可忽略。
- 6T 版图 30 年基本不变:2 CPP × 5 M1 pitch ≈ 160F²(PD:PG:PU = 2:1:1);先进节点 F² 归一化失效,记住 HD 单元绝对面积 ≈ 0.02 µm²(约 100×200 nm),且 5nm 后缩放几乎饱和。
- 变异性五大来源——空间型:RDF(σVth ∝ 1/√(LW),渗流路径)、LER(3–5 nm 固有粗糙)、WFV(金属栅晶粒);时间型:RTN(ΔVth = q/(W·L·C_ox))、NBTI(ΔVth ≈ A·tⁿ,SNM 随老化退化);总 σVth 按平方和合成。
- 软错误:α 粒子可屏蔽、宇宙射线中子不可屏蔽;判据 Q 注入 vs Qs ∝ Cs(VDD−VT);SRAM 单元级 SER 随缩放大致不变、系统级随容量上升(DRAM 则急剧下降);寄生 BJT 闩锁导致多位翻转,威胁 ECC,SOI 可大幅缓解。
- FinFET(2012 Intel 22nm 量产):W_eff = 2H_fin + T_fin(22nm:34×2+8=76 nm);RDF 基本消失(鳍不掺杂)但新增鳍 LER;宽度量化 → 用鳍数定配比:HD cell 1:1:1,HP cell 2-2-1;鳍逐代变高变薄变密。
- GAA 纳米片(Samsung 3nm 起):四面环栅静电控制最优,W_eff = (D+T)×2×N 连续可调;关键工艺为 SiGe/Si 超晶格外延与沟道释放;挑战是多 Vt 工程与 PMOS 迁移率。
- 延续缩放的组合拳:BS-PDN 背面供电(nTSV + 晶圆减薄,散热是最大风险)、CFET(N/P 堆叠再省 ~40% 面积,~2032)、DTCO(3nm 节点贡献 >50% 密度收益:COAG、鳍减员、FinFlex)、3D 键合(AMD 3D V-Cache:96MB L3、>2TB/s、+4 周期)。
术语表
| 术语 | 中文 | 解释 |
|---|---|---|
| SRAM (Static Random Access Memory) | 静态随机存取存储器 | 基于交叉耦合反相器锁存数据、无需刷新但掉电丢数据的存储器。 |
| Bit cell | 位元/存储单元 | 存储 1 bit 的最小电路单元,本讲为 6 管结构。 |
| Cross-coupled inverters / Latch | 交叉耦合反相器/锁存器 | 两个反相器输入输出互接形成的双稳结构,SRAM 保持数据的核心。 |
| WL / BL / BL̄ | 字线 / 位线 / 互补位线 | WL 控制 pass gate 选中一行;BL 对与单元交换数据。 |
| PU / PD / PG | 上拉管 / 下拉管 / 传输管 | 6T 单元三类晶体管:PMOS 上拉、NMOS 下拉、NMOS 存取管;三者相对强度决定读写裕度。 |
| β ratio | β 比 | (W/L)PD/(W/L)PG,须足够大以保证读稳定性(PD 强、PG 弱)。 |
| γ ratio | γ 比 | (W/L)PU/(W/L)PG,可约为 1(借助 μn>μp)以保证写能力(PG 强、PU 弱)。 |
| Current drivability | 电流驱动能力 | ∝ μ·W/L,衡量晶体管强弱的真正指标(不只是 W/L)。 |
| Read disturb | 读扰动 | 读时存 0 节点被 PG/PD 分压抬升、可能误翻数据的现象。 |
| Precharge | 预充电 | 读前把 BL/BL̄ 充到 VDD 并等位化的步骤/电路(3 个 PMOS 含 equalizer)。 |
| C_BL(位线寄生电容) | 位线电容 | 长位线导线固有电容,典型 0.2 fF/μm,决定读延时。 |
| Sense Amplifier (SA) / SAEN | 灵敏放大器 / SA 使能 | 锁存型电路把位线毫伏级 ΔV 放大为数字 0/1;SAEN 控制尾管,须等 ΔV(100–200 mV)建立后使能。 |
| Column mux / Write driver | 列选通 / 写驱动器 | 传输门在读写路径间切换;反相器链生成互补写数据驱动位线。 |
| VTC / Butterfly curve | 电压传输曲线 / 蝶形曲线 | 反相器输入输出关系曲线;两条 VTC 叠画即蝶形曲线,用于静态稳定性分析。 |
| Stable / Meta-stable point | 稳定点 / 亚稳点 | 蝶形曲线外侧两交点对应数据态;中间交点(~VDD/2)任何噪声都会使其滑向稳定点。 |
| SNM (Static Noise Margin) | 静态噪声裕度 | 噪声永久存在时单元不翻转的最大容忍度 = 蝶形曲线最大内嵌正方形边长(= D1/√2);失配时取 min[SNML,SNMR],默认指 Read SNM。 |
| W-SNM | 写静态噪声裕度 | 写偏置下两曲线(须只有一个交点)间可嵌入的最小正方形边长。 |
| N curve / SINM / SVNM / SPNM | N 曲线及其三裕度 | 存储节点接电压源扫描所得 I-V 曲线;SINM=最大可注入电流、SVNM=最大可容忍电压、SPNM=两者乘积;适合在线测试。 |
| DNM (Dynamic Noise Margin) | 动态噪声裕度 | 考虑噪声/写脉冲时长有限的裕度;SNM 是脉宽无限的 DNM;静态对 read/hold 悲观、对 write 乐观。 |
| Tcrit / Tacross / TW | 临界翻转时间 / 越界时间 / 写脉宽 | 状态轨迹越过稳定边界所需时间;写要求 TW > Tacross(写裕度 = TW − Tacross)。 |
| Separatrix / Trajectory | 分界线 / 轨迹 | V1–V2 相平面中翻转与恢复的边界(对称单元为 45° 线);节点电压随时间在相平面走过的路径。 |
| Shmoo plot | Shmoo 图 | 时钟频率 × 电源电压的 pass/fail 图;高频角失败由写失败主导,低压角由读失败主导。 |
| Read-Assist / Write-Assist | 读辅助 / 写辅助 | 降 WL 电压提高读裕度(等效增大 β);负位线 NBL 增强 PG 或降 cell VDD 削弱 PU 提高写裕度。 |
| RMW (Read-Modify-Write) | 读-改-写 | 整行读入 buffer → 替换目标位 → 整行写回,消除选中/未选中列的字线脉宽冲突。 |
| 8T SRAM / RWL / RBL | 八管单元 / 读字线 / 读位线 | 6T 加两管读缓冲实现读写解耦,Read SNM = Hold SNM,代价是面积与布线。 |
| Sub-array | 子阵列 | SRAM 基本阵列单位,典型 32×32 至 256×256(更大则互连 RC 太慢)。 |
| I_OFF / GIDL / 栅隧穿 I_G | 三类漏电 | 保持态 3 管亚阈值漏电;Vgs<0 时漏端带带隧穿(BTBT)漏电;薄 SiO₂ 直接隧穿(HKMG 后可忽略)。 |
| Dual-V_T cell / Boosted V_DD | 双阈值单元 / 抬升电源 | 锁存用高 V_T 抑漏、pass gate 用低 V_T 保速度;V_DH 补偿稳定性损失。 |
| Double/Triple WL / Flying BL | 双/三字线 / 飞线位线 | 多层金属并联布字线降电阻(−62%);上层金属跨接位线降电容(至 50–58%)。 |
| CPP / CGP | 接触栅距 | 源接触中心到漏接触中心距离 = CT + 2×Spacer + L_G;真正的水平缩放指标,老节点 ≈ 4F。 |
| M1 pitch / MMP | 金属一层间距 / 最小金属距 | 最底层金属布线最小周期;6T 面积 = 2 CPP × 5 M1 pitch ≈ 160F²(5nm 时 ≈ 2 CPP × 6 MMP)。 |
| Memory compiler | 存储器编译器 | 代工厂提供的 SRAM 宏自动生成工具,单元用特殊设计规则深度优化。 |
| Immersion lithography / OPC | 浸没式光刻 / 光学邻近校正 | 高折射率液体提高 NA;制掩模时预补偿光学畸变——193nm 延寿两大手段。 |
| Double patterning / SADP/SATP/SAQP | 双重/多重图形化 | line+cut 两次曝光或 spacer 自对准(mandrel+侧墙)把 pitch 增密 2/3/4 倍。 |
| EUV | 极紫外光刻 | 波长约 13.5 nm(ASML),sub-7nm 节点量产使用。 |
| RDF (Random Dopant Fluctuation) | 随机掺杂涨落 | 沟道离散掺杂原子数量与位置随机造成的 Vth 变异,σVth ∝ 1/√(LW);FinFET 未掺杂鳍使其基本消失。 |
| Percolation path / Pelgrom plot | 渗流路径 / Pelgrom 图 | 掺杂稀疏处势垒塌陷形成漏电通道;σVth 对 1/√(LW) 作图检验 RDF(小尺寸偏离直线说明有额外变异源)。 |
| LER / LWR | 线边缘/线宽粗糙度 | 线条边缘(线宽)变化的 3σ,典型 3–5 nm,源于光刻胶分子尺度;FinFET 时代主导变异源(含鳍 LER)。 |
| WFV (Work Function Variation) | 功函数变异 | 金属栅多晶晶粒取向不同导致的 Vth 随机源;总 σVth² = σ(RDF)² + σ(LER)² + σ(WFV)²。 |
| HKMG / EOT / IL | 高K金属栅 / 等效氧化层厚度 / 界面层 | HfO₂+TiN 替代 SiO₂/poly(45nm 起);t_eq = ε_ox·t_k/ε_k + t_ox;Si 表面天然 ~0.7nm SiO₂ 计入 EOT。 |
| RMG / Multi-Vt | 替换金属栅 / 多阈值 | 金属厚度调制或工程化偶极子实现多档 Vth(TSMC N5 达 7 档)。 |
| RTN (Random Telegraph Noise) | 随机电报噪声 | 单个介质陷阱随机俘获/释放电子使 ID/Vth 两电平跳变;ΔVth = q/(W_eff·L_eff·C_ox),与面积成反比。 |
| BTI / NBTI / PBTI | 偏压温度不稳定性 | 电压/温度应力下 Vth 随时间漂移的老化效应(NBTI 对 PMOS 更严重);ΔVth ≈ A·tⁿ 幂律,使 SNM 随时间退化。 |
| Soft Error / SER | 软错误 / 软错误率 | 辐射粒子使数据翻转的暂时性失效(下次写恢复);SRAM 单元级 SER 随缩放大致不变、系统级随容量上升。 |
| Qs (Critical charge) | 临界电荷 | 翻转存储节点所需最小收集电荷,SRAM 中 ∝ Cs(VDD−VT),Cs 全为寄生电容。 |
| SEU / MBU | 单粒子翻转 / 多位翻转 | 一次粒子事件造成的单/多比特错误;MBU 严重威胁 ECC 纠错能力。 |
| Latch-up(寄生 BJT 效应) | 闩锁效应 | 衬底 IR 压降抬升局部衬底电位、开启寄生 NPN,使相邻单元连锁放电翻转。 |
| ECC / SOI | 纠错码 / 绝缘体上硅 | 冗余位纠错(能力有限);SiO₂ 衬底消除共享体硅通路,大幅降低软错误但更贵。 |
| FinFET / Tri-Gate | 鳍式场效应晶体管 | 沟道为直立薄鳍、栅三面包裹的 3D 晶体管;1998 Berkeley 提出,2012 Intel 22nm 量产(Intel 称 Tri-Gate)。 |
| W_eff / W_phy / P_fin | 有效宽度 / 物理宽度 / 鳍距 | 单鳍 W_eff = 2H_fin + T_fin(多鳍 ×N);W_phy = N×P_fin;W_eff > W_phy 时电流密度优于平面。 |
| Width quantization | 宽度量化 | FinFET 宽度只能取整数根鳍,丧失连续调宽灵活性(GAA 纳米片解决此问题)。 |
| SS / DIBL | 亚阈值摆幅 / 漏致势垒降低 | SS 室温极限 60 mV/dec(Intel 22nm 约 69–72);DIBL = ΔVT/ΔVD 越小越好(约 46–50 mV/V)。 |
| SiGe channel | 硅锗沟道 | PMOS 用 SiGe 合金提升空穴迁移率(TSMC 5nm 起;GAA 中亦用作 PMOS 对策)。 |
| GAA / Stacked nanosheet | 全环绕栅 / 堆叠纳米片 | 栅四面包裹的水平堆叠薄片沟道(FinFET 旋转 90° 堆叠),静电控制最优;W_eff = (D+T)×2×N 连续可调。 |
| Channel release / Inner spacer | 沟道释放 / 内侧墙 | 选择性刻蚀去除 SiGe 牺牲层使硅片悬空;端部介质隔离保护源漏——GAA 核心工序。 |
| BPR / BS-PDN / PowerVia | 埋入电源轨 / 背面供电网络 | 电源轨埋入硅(中间方案)→ 电源完全从晶圆背面进(正面专走信号);Intel 18A 的实现叫 PowerVia。 |
| nTSV / RibbonFET | 纳米硅通孔 / Intel 纳米片 | 约 90–100 nm 见方的 TSV 连接减薄晶圆正反面;RibbonFET 是 Intel 对堆叠纳米片的命名。 |
| TIM / IHS / Structural die | 热界面材料 / 散热盖 / 结构 die | 封装散热路径组成;结构 die 是覆盖 CPU 核心的空白硅片,提供支撑兼散热。 |
| CFET (Complementary FET) | 互补场效应晶体管 | NMOS 与 PMOS 垂直堆叠的未来器件(~2032),可使 SRAM 面积再缩约 40%。 |
| DTCO / STCO | 设计-工艺 / 系统-工艺协同优化 | 设计规则与工艺特征协同提升密度(3nm 贡献 >50%);STCO 再加封装/3D-IC/热/供电的系统级协同。 |
| COAG / Fin depopulation / FinFlex | 有源区上方栅接触 / 鳍减员 / 混合鳍 | 典型 DTCO 手段:栅接触移到鳍上方省面积;单鳍电流增强后减少鳍数(4→3);TSMC N3 混搭 2-1/2-2/3-2 鳍 cell。 |
| PPAC / PPCF | 性能-功耗-面积-成本(-形态因子) | DTCO/STCO 流程的优化目标输出。 |
| 3D V-Cache / Hybrid bonding | 3D 垂直缓存 / 混合键合 | AMD 将 7nm 纯 SRAM die 键合叠在 CPU die 上(96MB L3、>2TB/s、+4 周期);铜-铜与介质同时键合的堆叠技术。 |
| Cache (L1/L2/L3) / Embedded memory | 缓存 / 嵌入式存储器 | 处理器片上多级 SRAM 存储层次;与处理器集成在同一芯片上的存储器。 |