Lecture 7:存内计算(In-Memory Computing)
1. 课程引入:存内计算的动机 00:00:03
在学完 SRAM、DRAM、NAND Flash 以及各种新兴存储器之后,本讲讨论一个前沿话题——如何"用存储器做计算"。这是包括 Yu 教授课题组在内的许多研究团队正在攻关的方向。驱动力非常明确:在片上加速 AI 算法。神经网络拓扑在过去十多年间快速演化——前馈网络(FF)、深度卷积网络(DCN)、带 bypass 连接的残差网络(DRN)、循环网络(RNN)、LSTM、生成对抗网络(GAN),直到注意力模型(Attention)——后者正是今天 Transformer 与大语言模型的基础。
无论哪种拓扑,内存都是大瓶颈,原因有二:(1)所有权重都存放在存储器中,训练要更新权重、推理也要读权重;(2)计算过程会产生大量中间数据(如部分和 partial sum),同样需要保存。这就是把计算搬进(或搬近)存储器的根本动机。

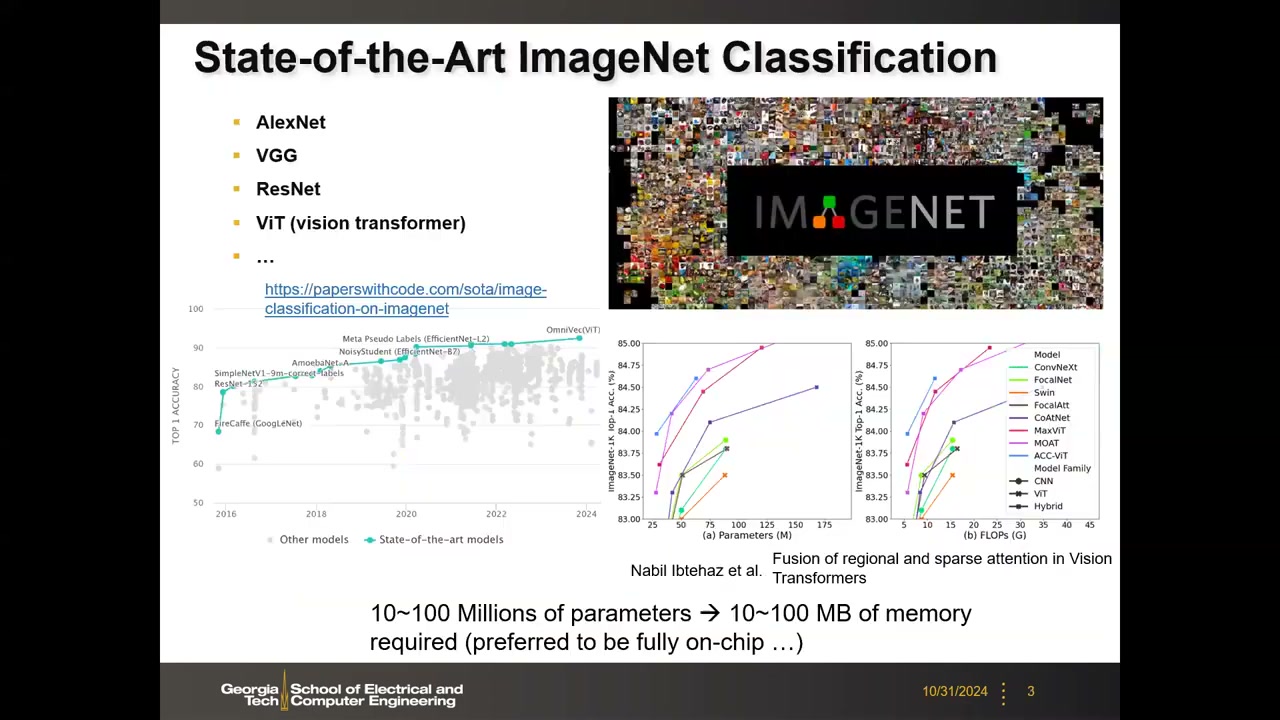
2. ImageNet 分类与片上存储需求 00:02:45
AI 的复兴始于 2012 年 AlexNet 在 ImageNet 竞赛中夺冠——它是首个跑在 GPU 上的里程碑模型;其后 VGG、引入 bypass 的 ResNet,再到近年的 ViT(视觉 Transformer),Top-1 精度从早年的约 70% 提升到今天 ViT 的 90% 以上。
典型 ImageNet 分类模型的参数量在 10~100 Million 量级。若权重量化为 8-bit 整数,10M 参数约等于 10 MB,因此模型需要 10~100 MB 的存储,而且最好全部放在片上——这样可以省掉片外 DRAM 访问的时间和能耗。堆叠 SRAM 有可能达到这一片上容量。
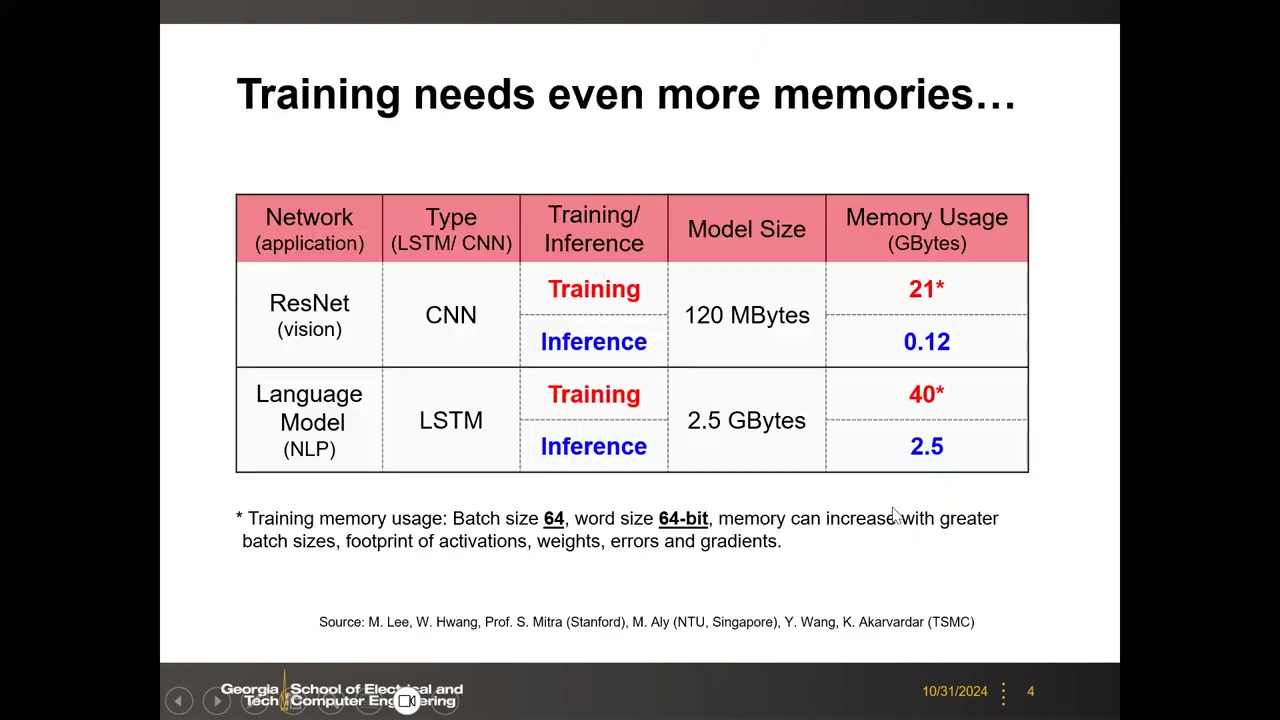
3. 训练 vs 推理的内存需求 00:06:13
推理只需要读权重,内存容量约等于模型大小再加少量缓冲/寄存器;而训练必须存储每一层的中间数据(激活、误差、梯度),并且要跨 batch 累积,内存需求远大于模型本身。幻灯片给出的数据(批大小 64、64-bit 字长):
| 模型 | 类型/应用 | 模型大小 | 训练内存 | 推理内存 |
|---|---|---|---|---|
| ResNet | CNN,视觉 | 120 MB | 21 GB | 0.12 GB |
| LSTM 语言模型(非 Transformer) | RNN,语言 | 2.5 GB | 40 GB | 2.5 GB |
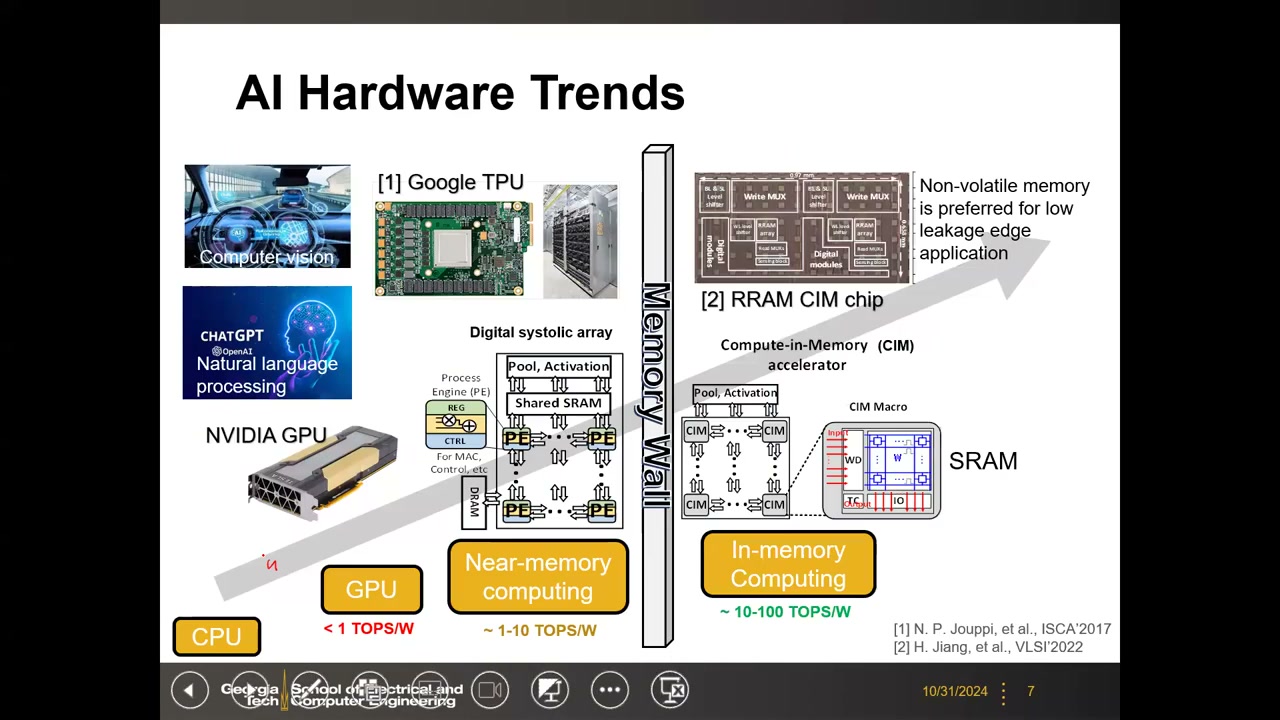
4. AI 硬件趋势与能效指标(TOPS/W) 00:09:18
AI 应用已从计算机视觉(自动驾驶等)扩展到近两年由 Transformer 驱动的 NLP / 生成式 AI(ChatGPT)。GPU 仍是 AI 训练和推理的主力(NVIDIA),依赖 HBM 与 2.5D 集成(如 TSMC CoWoS);但 GPU 非常耗电——单卡几百瓦到约 1000 W,集群达数十 kW,大规模系统达 MW 量级,已经引来碳排放方面的批评。
量级对比:CPU 最低;GPU < 1 TOPS/W;近存计算(TPU 类数字加速器)约 1–10 TOPS/W;存内计算的目标是约 10–100 TOPS/W。近存计算(TPU)采用数字脉动阵列:大量 PE(处理单元 = 数字乘法器 + 加法器 + 本地寄存器)加上共享 SRAM 全局缓冲,并配有池化/激活等专用功能单元,比通用 GPU 更定制化;模型放不下时仍需访问片外 DRAM。
但即便如此,"存储墙"(memory wall)依然存在:计算(PE)与存储(共享 SRAM)是分离的,片上数据搬运量仍然很大——这正是推动向存内计算范式转移的原因。
5. 存内计算范式与技术选型 00:17:18
存内计算的基本范式是权重固定(weight stationary):权重存在存储器(SRAM 或 RRAM 等)中不动,只搬运输入和输出。与常规存储访问的本质区别在于:常规读写一次只打开一行(wordline),而 CIM 要同时打开多行,把输入向量并行加载,在阵列内部完成计算,最大化并行度。
技术选型上,Yu 组多年流片得出的经验是:
- 云端/高性能计算:仍选 SRAM CIM。新兴存储器拿不到最先进逻辑节点(SRAM 可到 3nm,RRAM 量产只有 22nm),性能拼不过 SRAM。
- 低功耗边缘设备:非易失存储器(如 RRAM)CIM 有优势。边缘设备长时间待机、电池受限,SRAM 一直在漏电;把权重存进非易失存储器可以做动态电源门控(power gating),省掉静态漏电。
6. 现代 AI 模型的内存需求分级 00:23:39
近两年研究兴趣从小模型(图像分类,约 10~100 MB)转向大语言/多模态模型。GPT-4 约有 1.8 万亿(trillion)参数,超过 TB 级——SRAM、RRAM 等嵌入式片上存储对此完全无用(SRAM 再 scaling 20 年也达不到这个容量),这是 DRAM 甚至 NAND Flash 的领域(NAND 太慢,所以实际靠 DRAM)。
幻灯片给出的分级:图像分类类模型(10~100 MB 级)→ 计算嵌入到片上存储(与逻辑同芯片);语言/图模型(10 GB~TB 级)→ 计算结合存储级存储器(与逻辑分芯片)。量化估算:HBM 堆叠 12 层 2D DRAM,每片约 32 Gbit = 4 GB,一个 HBM 栈只有几十 GB;要装下 1 TB 模型需要约 10 块 GPU(每块配一套 HBM)。因此 DRAM 的持续 scaling(如 DRAM 讲中提到的单片 3D DRAM)一旦实现,将进一步推动大模型应用。

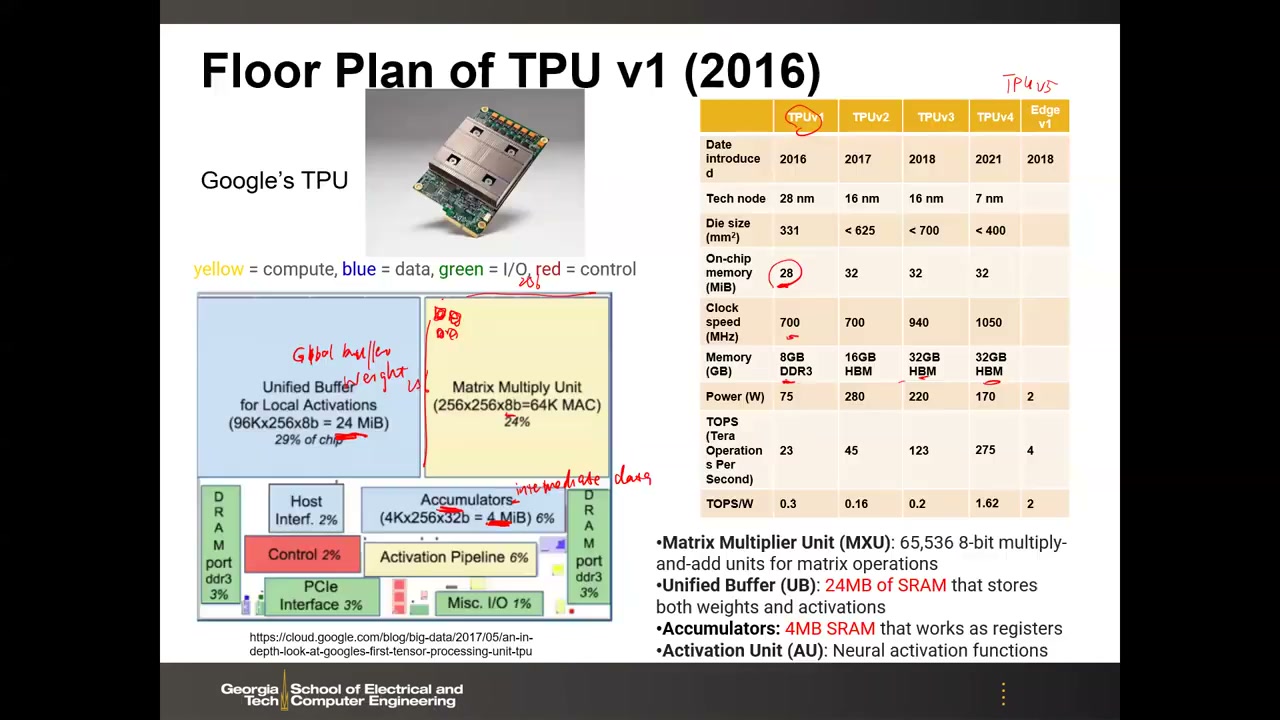
7. Google TPU v1 架构与各代参数 00:27:05
TPU(Tensor Processing Unit)约 2016 年问世。Google 只在 ISCA 2017 论文中公开了 TPU v1 的细节,最新已演进到 v5(细节未公开)。TPU v1 的关键参数:28nm 工艺,die 面积 331 mm²;矩阵乘法单元 MXU = 256×256 = 65,536 个 8-bit MAC(占芯片面积 24%);统一缓冲(Unified Buffer)24 MB SRAM(占 29% 面积,主要存权重和激活);累加器 4 MB SRAM(存中间数据/部分和)——片上 SRAM 共 28 MB,约占芯片面积 35%;时钟 700 MHz;片外 8 GB DDR3;功耗 75 W;峰值 23 TOPS,能效 0.3 TOPS/W。
| 代次(年份) | 工艺 | 时钟 | 片外存储 | 功耗 | 峰值吞吐 | 能效 |
|---|---|---|---|---|---|---|
| TPU v1(2016) | 28nm,331mm² | 700 MHz | 8 GB DDR3 | 75 W | 23 TOPS | 0.3 TOPS/W |
| TPU v2(2017) | 16nm | — | 16 GB HBM | — | 45 TOPS | — |
| TPU v3(2018) | 16nm | 940 MHz | HBM | — | 123 TOPS | — |
| TPU v4(2021) | 7nm,<400mm² | 1050 MHz | 32 GB HBM | 170 W | 275 TOPS | 1.62 TOPS/W |
| Edge TPU v1(2018) | — | — | — | 2 W | 4 TOPS | 2 TOPS/W |
可以看到:早期版本能效低于 1 TOPS/W,近期也只有几个 TOPS/W;片上 SRAM 只有几十 MB,跑大模型仍然需要挂 DRAM/HBM。
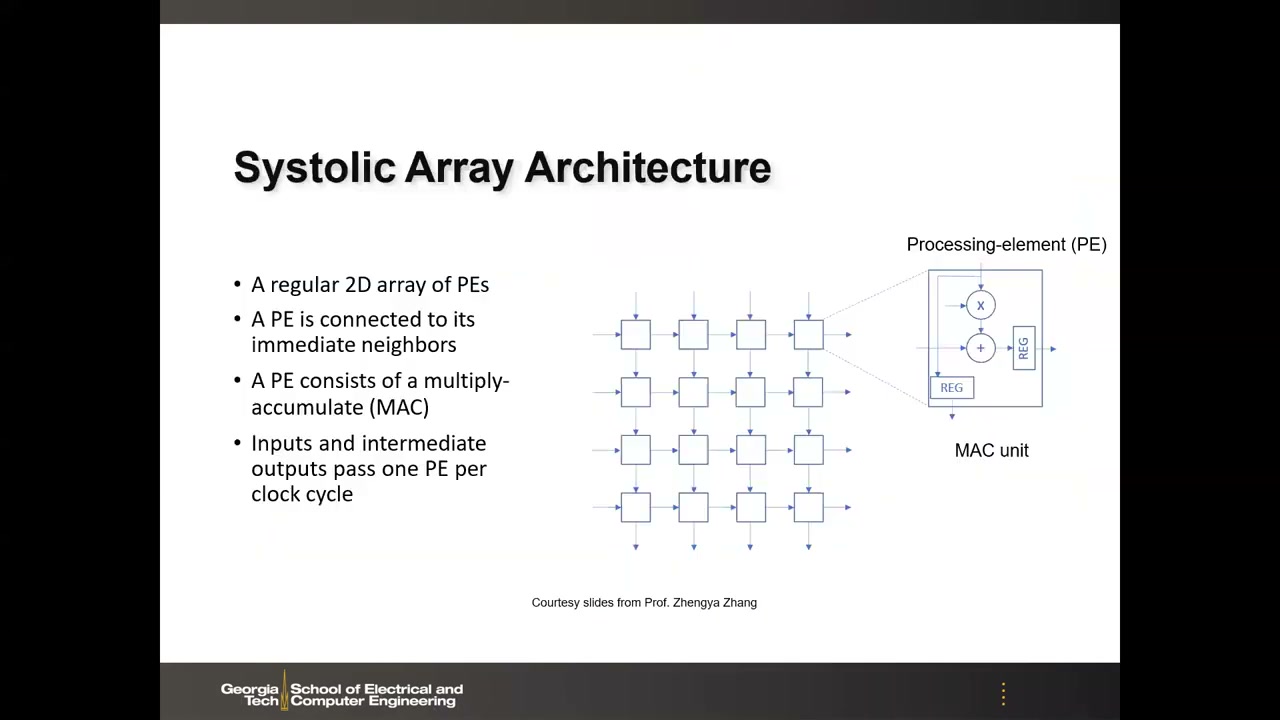
8. 脉动阵列架构与数据流 00:31:43
脉动阵列(systolic array)= 规则的 2D PE 阵列;每个 PE 只与最近邻相连;每个 PE 是一个 MAC 单元(数字乘法器 + 加法器 + 本地寄存器);输入和中间输出每个时钟周期前进一个 PE。其核心思想是数据流(dataflow)与数据复用:尽量减少 PE 与 SRAM 全局缓冲之间的往返。计算开始前,权重先从缓冲预取、存入各 PE 的本地寄存器。
以向量-矩阵乘法为例:输入 x1 与权重 W11 相乘得到部分和 y1 的第一项,部分和沿水平方向逐周期传递并累加(y1 = x1·W11 + x2·W12 + …);同时输入 x 沿垂直方向传给下方邻居复用——形成一个波前(wavefront)扫过整个阵列,最终在阵列边缘得到输出向量。优点:部分和不必写回全局缓冲、输入不必重复从全局缓冲读取,只有最近邻的短距离数据传输,同时节省延迟和能量。
矩阵-矩阵乘法则可以流水线化:输入矩阵的不同行对应不同波前依次泵入,PE 不空闲,计算密度高。这一架构被 Google 及众多设计公司、初创公司广泛采用。
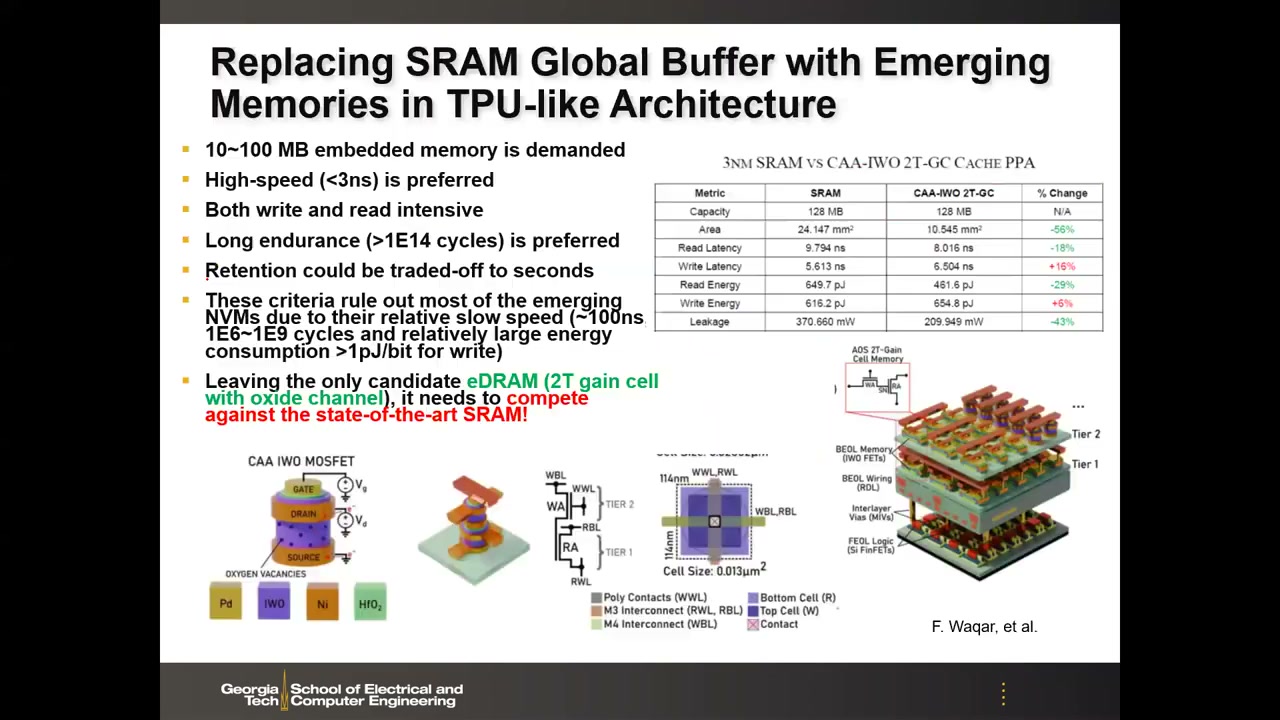
9. 替换 TPU 全局缓冲:判据与 2T 增益单元 eDRAM 00:41:01
TPU 架构中 MAC 部分用先进逻辑工艺即可,真正的瓶颈和改进机会在全局缓冲——越大越好。若想用新型存储器替换这块 SRAM,判据是:容量 10~100 MB 或更大;高速 <3 ns(兼容末级缓存,时钟约 700 MHz~1 GHz);读写都密集;长耐久 >1E14 次;保持时间可放宽到秒级(数据可以刷新)。
这些判据排除了大多数新兴 NVM——RRAM、PCM 甚至 STT-MRAM:写速度太慢(~100 ns)、耐久只有 1E6~1E9 次、写能耗超过 1 pJ/bit(MRAM 写能耗过大)。唯一的候选是 2T 增益单元(gain cell)eDRAM——无电容 DRAM:一个写晶体管加一个读晶体管,电荷暂存于存储节点,利用读晶体管的跨导实现非破坏性读出。关键挑战是保持时间由写晶体管漏电决定——硅沟道只有微秒级(刷新太频繁,收益尽失);改用宽禁带氧化物半导体沟道(如 IWO)后,保持时间可达秒级甚至 10 秒。
Yu 组的 benchmark(128 MB cache,3nm SRAM vs CAA-IWO 2T 增益单元,垂直晶体管,单元面积 0.013 µm²):
| 指标 | 3nm SRAM | CAA-IWO 2T-GC | 变化 |
|---|---|---|---|
| 面积 | 24.147 mm² | 10.545 mm² | -56% |
| 读延迟 | 9.794 ns | 8.016 ns | -18% |
| 写延迟 | 5.613 ns | 6.504 ns | +16%(略慢) |
| 读能量 | — | — | -29% |
| 写能量 | — | — | +6% |
| 漏电功耗 | 370.66 mW | 209.949 mW | -43% |
氧化物沟道是 BEOL 兼容的,可以堆叠多层(tier),容量潜力达数百 MB 甚至约 8 层堆叠下的 1 GB。该方向仍处研究阶段,但很多公司持续关注。

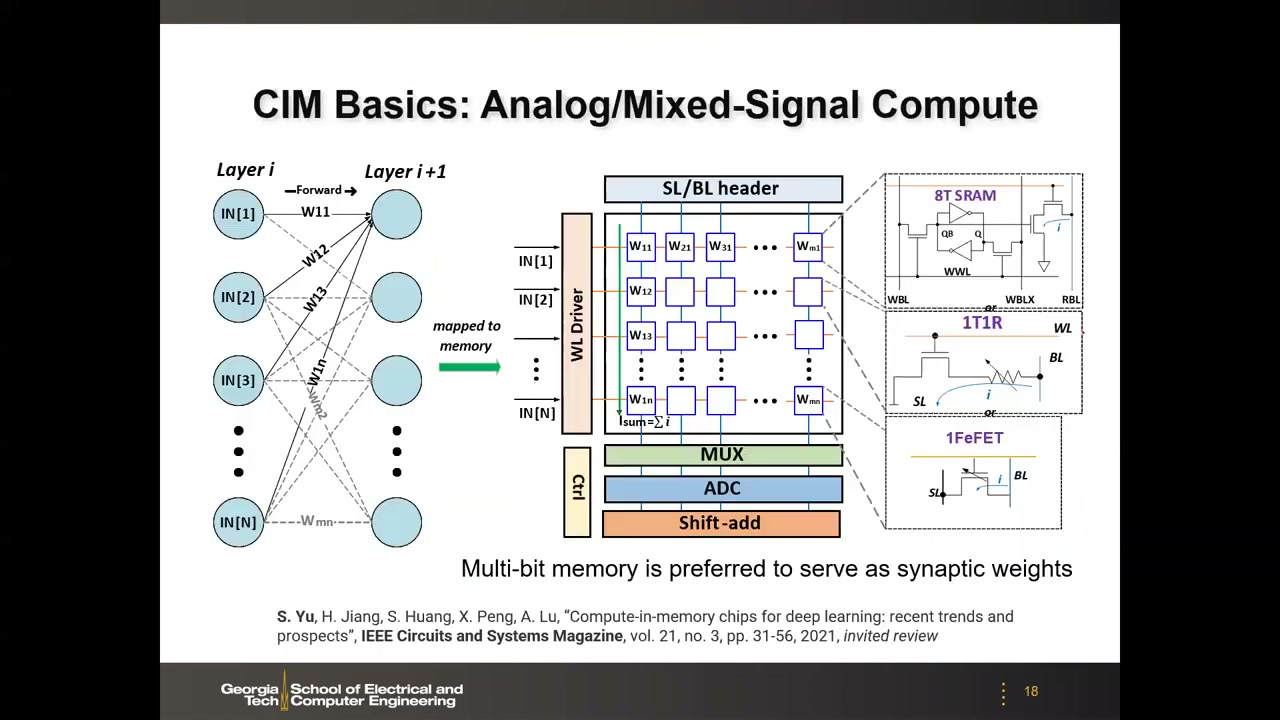
10. CIM 基础:模拟/混合信号计算 00:47:06
把神经网络层映射到存储阵列的方法:输入作为电压加到字线(WL),权重预先存为单元的电导。根据欧姆定律,电压 × 电导 = 单元电流;同时打开多行后,各单元电流沿位线(BL)自动求和(基尔霍夫电流定律),列底部的总电流就是部分和——乘累加完全在模拟域完成,"全靠物理定律计算":Isum,j = Σi VWL,i × Gi,j。
列尾用 ADC 把模拟电流量化回数字位。若权重是 8-bit 而每个单元只能存 1-bit,就用 8 个单元拼出 1 个权重,各列输出带有 MSB/LSB 的位权差异,需要移位累加(shift-add)重构部分和。阵列外围电路包括 WL 驱动、MUX、ADC 和 shift-add 单元;能存多位的单元更适合做突触权重。位单元的三类选择:
- 8T SRAM(读解耦):CIM 要开多行,常规 6T 的位线放电过大会扰乱存储数据(6T 是按单行开启设计的),8T 增加独立读路径避免读干扰;
- 1T1R(RRAM):用电阻/电导直接表示权重,更紧凑;
- 单晶体管 FET(如 FeFET):最紧凑,用可切换的阈值电压调制沟道电阻。
多行并行开启正是 CIM 吞吐量与能效提升的来源。
11. 为什么用 SRAM 做 ACIM:位单元变体 00:51:14
SRAM 是成熟的硅 CMOS 技术,随逻辑工艺一路 scaling 到 3nm 及以后;大容量缓存早已验证(7nm 256Mb [ISSCC 2017]、5nm 256Mb [IEDM 2019])。针对模拟 CIM(ACIM),领域内修改 SRAM 位单元的论文至少上百篇,主要变体有四种:
- 常规 6T:多行开启有读干扰风险,不推荐直接使用;
- Split-6T(分裂字线):把字线拆开、只开一侧 pass gate,消除另一侧的漏电/干扰,但需要 foundry 不支持的版图修改;
- 8T 读解耦(read decoupled):最常用——读写路径完全分离,多行开启没有干扰;
- 可转置 8T(Transposable):行、列两个方向都布字线/位线,可从两个方向读出,支持矩阵转置操作。

12. 实例:TSMC 7nm SRAM ACIM(ISSCC 2020)与 SRAM CIM 小结 00:53:13
代表作(Q. Dong et al., ISSCC 2020,TSMC):7nm 工艺、foundry 8T 读解耦单元、4 kb 演示阵列(64×64),输入/权重/输出精度均为 4-bit,宏面积 0.0032 mm²,工作电压 0.65~1 V;0.8 V 时周期 5.5 ns、最大功率 1.42 mW,吞吐 372.4 GOPS,能效 262.3~610.5(平均 351)TOPS/W——注意这是 4b×4b 口径。
设计亮点:多行同开、列电流累加表示部分和;模拟移位累加——不为每列单独配 ADC,而是用电容式 DAC 阵列(charge sharing)按电容位权放大不同列(MSB 列的电流权重是 LSB 列的 8 倍),在模拟域先完成 shift-add 再送入 4-bit Flash ADC;另加补偿电容平衡不同列的 RC 延迟。多位输入用 RWL 脉冲个数实现,4-bit 权重靠 ADC 前的电荷共享实现。

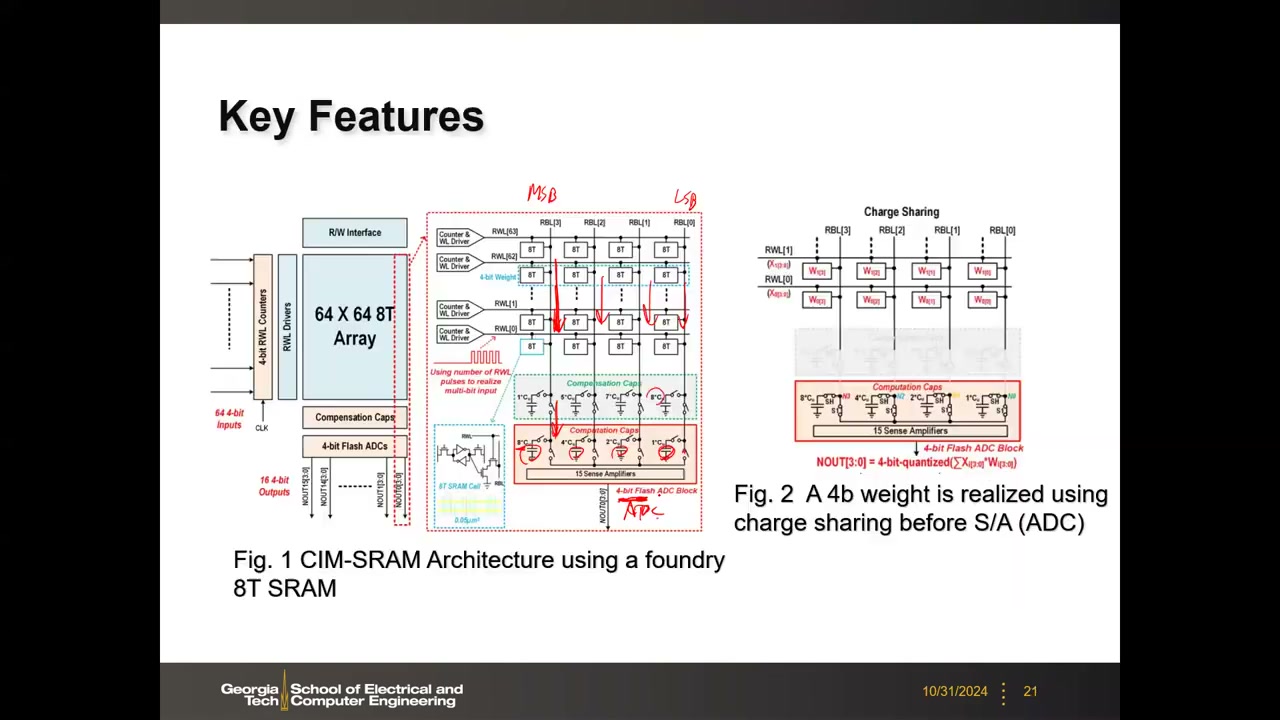
SRAM CIM 小结 00:56:31:SRAM 是 CIM 的成熟候选,3nm 及以后可用,原型能效亮眼;大容量 SRAM 阵列的主要劣势是漏电功耗。6T 最紧凑但读写不解耦,多行激活存在读干扰——降低 WL 电压有帮助,但可同开的字线数受限(例如 64 行);8T 解耦读写路径,CIM 设计更灵活。

13. 为什么用 RRAM 做 ACIM:NTHU/TSMC 22nm 实例 00:57:47
在同一技术节点下,RRAM 相对 SRAM 的好处:单元更小且可能做到多 bit/cell;约 100 MB 参数可以全片上;减少片外访问;非易失、几乎无漏电,可动态电源门控、即开即用(边缘场景的关键优势);还有 BEOL 3D 堆叠潜力。RRAM 工艺日趋成熟:TSMC 40nm RRAM(ISSCC 2018)、Intel 22nm RRAM(ISSCC 2019);厂商还有 Winbond、Sony、Panasonic 等,但商业上对外提供 RRAM 流片服务的主要是 TSMC。
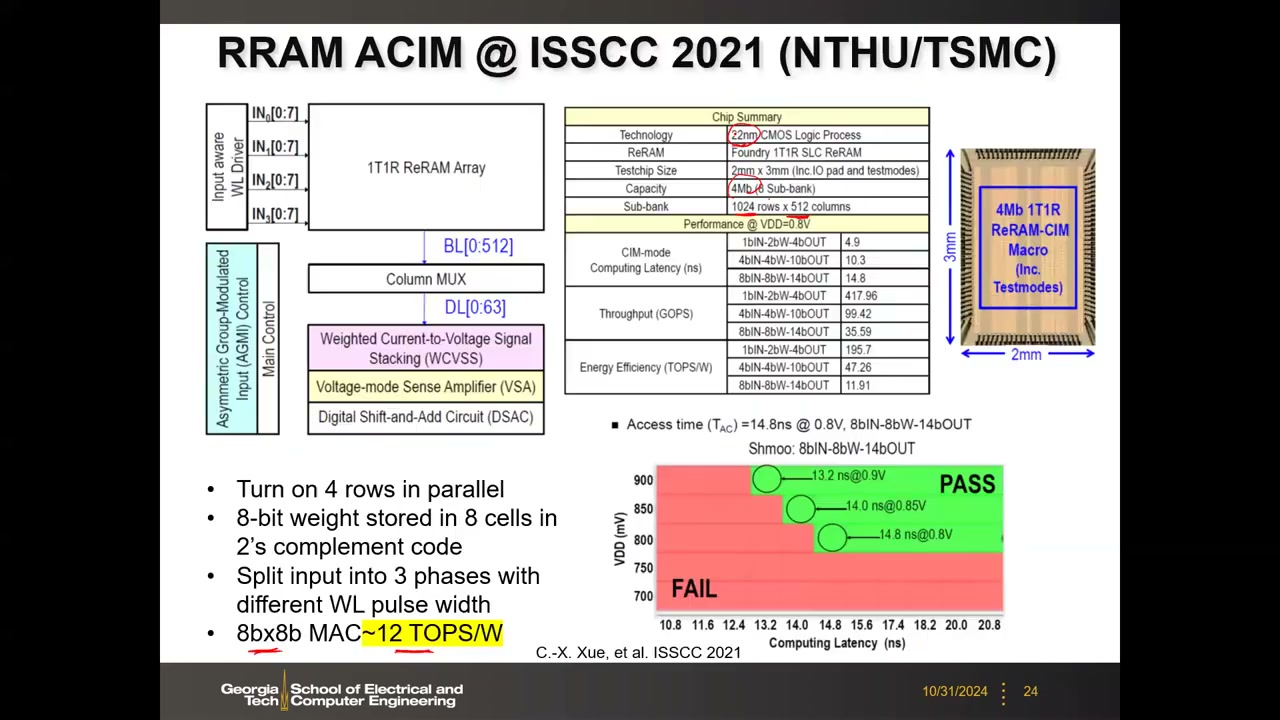
代表作(C.-X. Xue et al., ISSCC 2021,新竹清华大学 Marvin Chang 组 + TSMC):22nm CMOS 逻辑工艺、foundry 1T1R SLC ReRAM、容量 4Mb(8 个 sub-bank)、子阵列 1024 行 × 512 列;0.8 V 下 8bIN-8bW-14bOUT 延迟 14.8 ns。能效随精度配置变化:
| 精度配置(输入-权重-输出) | 能效(TOPS/W) |
|---|---|
| 1b IN - 2b W - 4b OUT | 195.7 |
| 4b IN - 4b W - 10b OUT | 47.26 |
| 8b IN - 8b W - 14b OUT | 11.91 |
归一化到 8b×8b 后约 12 TOPS/W,低于 SRAM 方案——部分原因是 22nm 对 7nm 的节点差距。设计要点:8-bit 权重存于 8 个单元(2 补码编码);输入分 3 相、用不同 WL 脉宽实现。

14. RRAM ACIM 的 PVT 挑战与小结 01:00:08
无论 SRAM 还是 RRAM,做模拟 CIM 都不可避免地受 PVT(工艺/电压/温度)变化引起的精度下降——这是模拟电路的固有问题,部分和结果天然带噪声。Yu 组 40nm RRAM-CIM 流片实测(W. Li et al., JSSC 2022,GaTech 设计 + TSMC 工艺):不同 VDD(1.0/0.9/0.8/0.7 V)下,即使加了 (16,10) MAC-ECC 纠错,高部分和值处的正确输出百分比仍会下降;不同温度(25~120°C)下同样如此。
把芯片实测统计注入神经网络仿真,即便是中等难度的 CIFAR-10,精度也有可感知下降:软件基线 92.0%;外部参考方案 25°C 时 91.5%、120°C 跌到 79.6%;片上参考方案 25°C 时 90.7%、120°C 时 85.8%——片上参考加偏移消除有缓解作用,但仍降低几个百分点。

RRAM CIM 小结 01:02:39:1T1R 或 2T2R 是典型位单元,单元面积约 30F²~60F²,同节点下密度约为 SRAM 的 2.5×~5×(但 22nm RRAM 对 7nm SRAM 就毫无优势了)。RRAM 有多级单元(MLC,如 2 bit/cell)潜力可再提密度,但 MLC 可靠性需要优化(编程后弛豫、阻值漂移、高温保持等)——对推理芯片来说,关键是中间阻态要稳定:阻值变了权重就变、精度就变。此外仍面临高编程电压(尤其 forming)和低导通电阻的挑战。

15. 系统级架构与卷积核权重映射 01:05:31
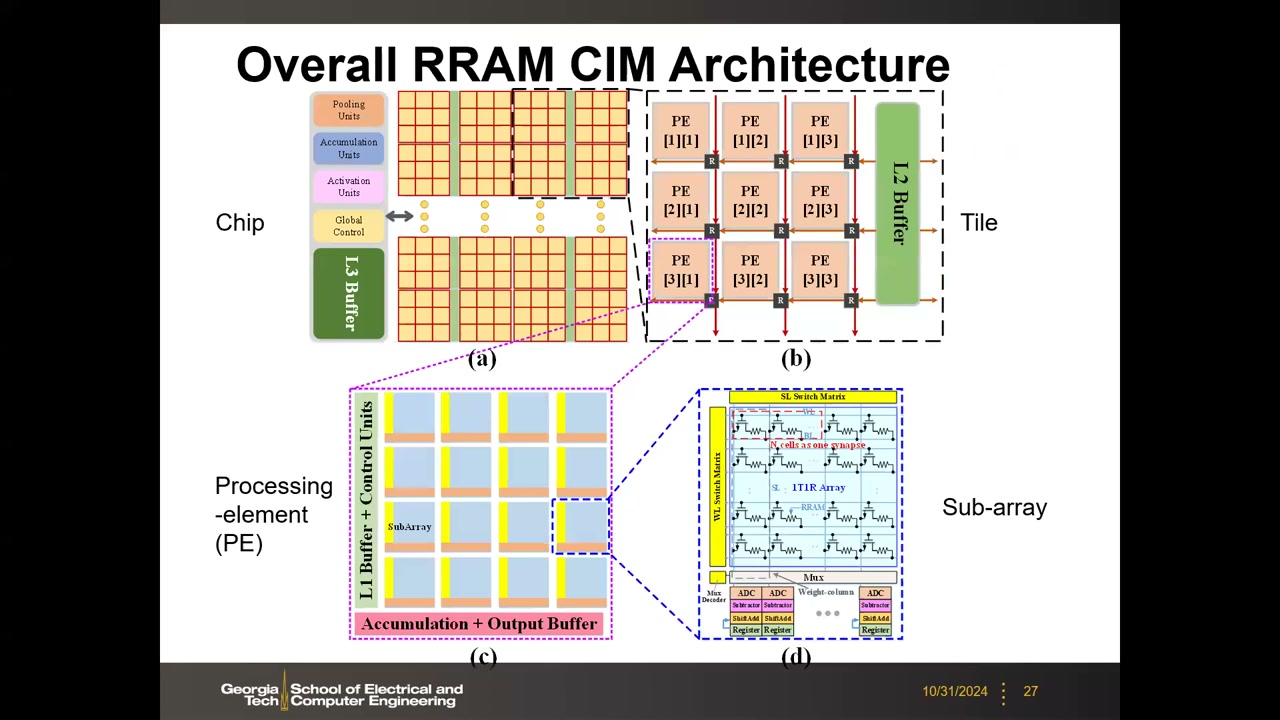
现状:ISSCC 上大多只演示单个宏(macro)或单个 PE,模拟 CIM 至今还没有系统级 demo——系统级需要集成多个宏、整体数据流、缓冲和专用功能单元,集成工作量很大。Yu 组提出的层级化系统架构:Chip(全局控制、池化/累加/激活单元、L3 buffer)→ Tile(PE 阵列 + L2 buffer)→ PE(子阵列 + L1 buffer + 控制)→ Sub-array(1T1R 阵列 + WL/SL 开关矩阵 + MUX + ADC + 减法/移位累加/寄存器)。
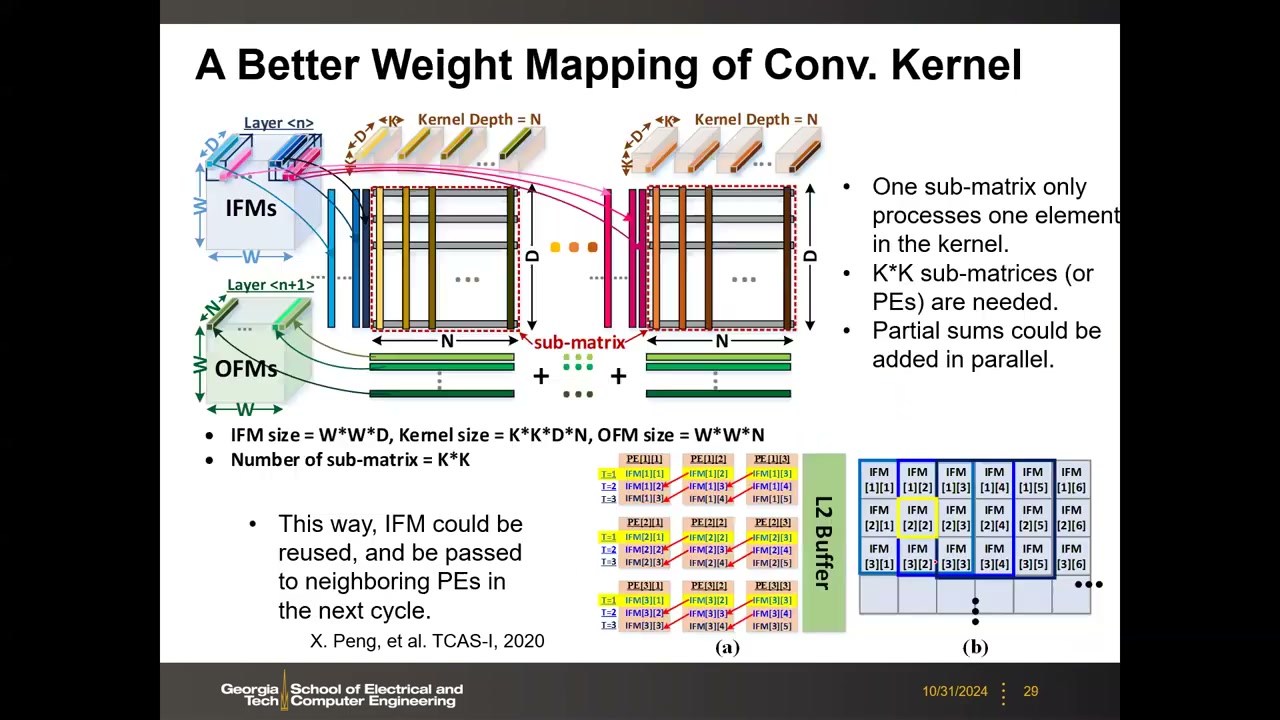
卷积是 4 维张量运算(输入特征图 IFM 三维 + 多个 kernel),必须展开(unroll)到二维存储阵列:
- 朴素映射:把整个 kernel(如 3×3×128 ≈ 1152 个元素)展成一条超长向量存为一列,输入窗口对应展开做一一对应乘累加——矩阵过大且低效,需要多周期滑窗。
- 改进映射(Yu 组提出,X. Peng et al., TCAS-I 2020,现已被社区广泛采用):按空间位置拆分——K×K(如 9)个子阵列各处理 kernel 的一个位置元素,部分和可并行相加;并借鉴脉动阵列原理,IFM 数据可在相邻 PE 间逐周期复用,映射效率大幅提高。
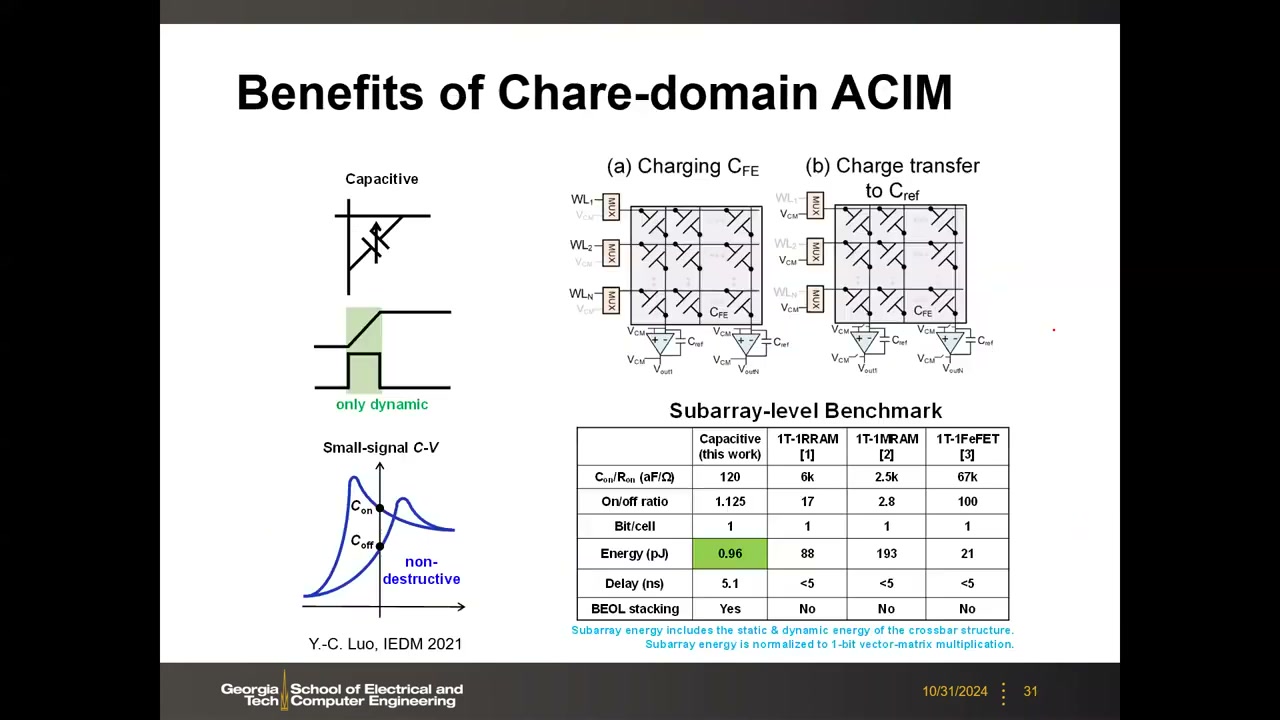
16. 电容式电荷域 ACIM 01:09:14
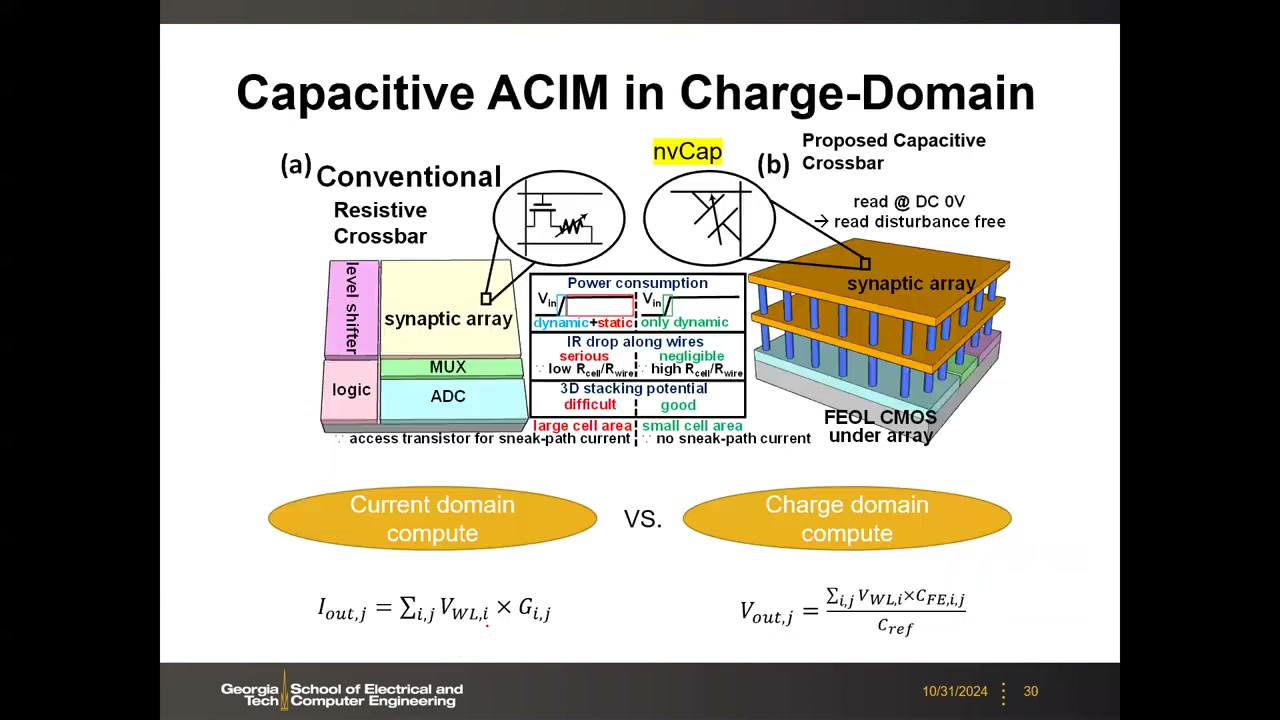
动机:电阻式电流域计算中,只要输入为高,每一行都持续流过电流,静态功耗占主导,这也限制了可并行打开的行数。Yu 组提出的思路:把交叉点换成可编程电容(nvCap,高/低电容两态,类比高/低阻态)。电容只在输入翻转时有瞬态充放电电流(只有动态功耗),输入稳定后零功耗。
计算公式从电流域的 Iout,j = Σ VWL,i × Gi,j(电压×电导→电流求和)变为电荷域的 Vout,j = Σ(VWL,i × CFE,i,j) / Cref(电压×电容→电荷转移),电荷转移到阵列边缘由运放/参考电容读出。其他优点:读在 DC 0V 下进行,无读干扰;导线 IR 压降可忽略(电容阻抗远高于 Rcell/Rwire);单元面积小、无潜行路径电流(无需选通管);BEOL 3D 堆叠特性好(FEOL CMOS 放在阵列下方)。
子阵列级 benchmark(128×128 阵列,1-bit 向量-矩阵乘归一化,Y.-C. Luo, IEDM 2021):
| 技术 | 能量 | 延迟 | BEOL 堆叠 |
|---|---|---|---|
| 电容式(nvCap) | 0.96 pJ | 5.1 ns | 支持(唯一) |
| 1T-1RRAM | 88 pJ | <5 ns | — |
| 1T-1MRAM | 193 pJ | <5 ns | — |
| 1T-1FeFET | 21 pJ | <5 ns | — |
电容式方案的能量比电阻式低数十到上百倍(10~100 倍量级),延迟与其他方案相当。
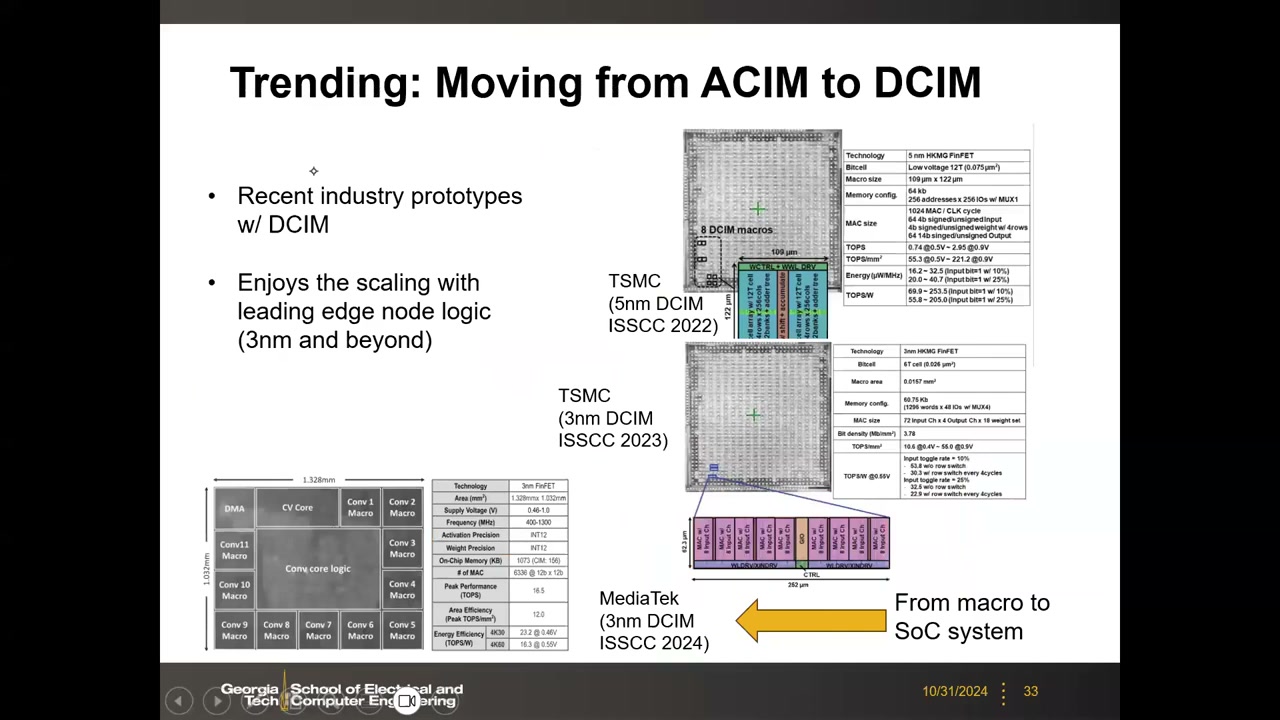
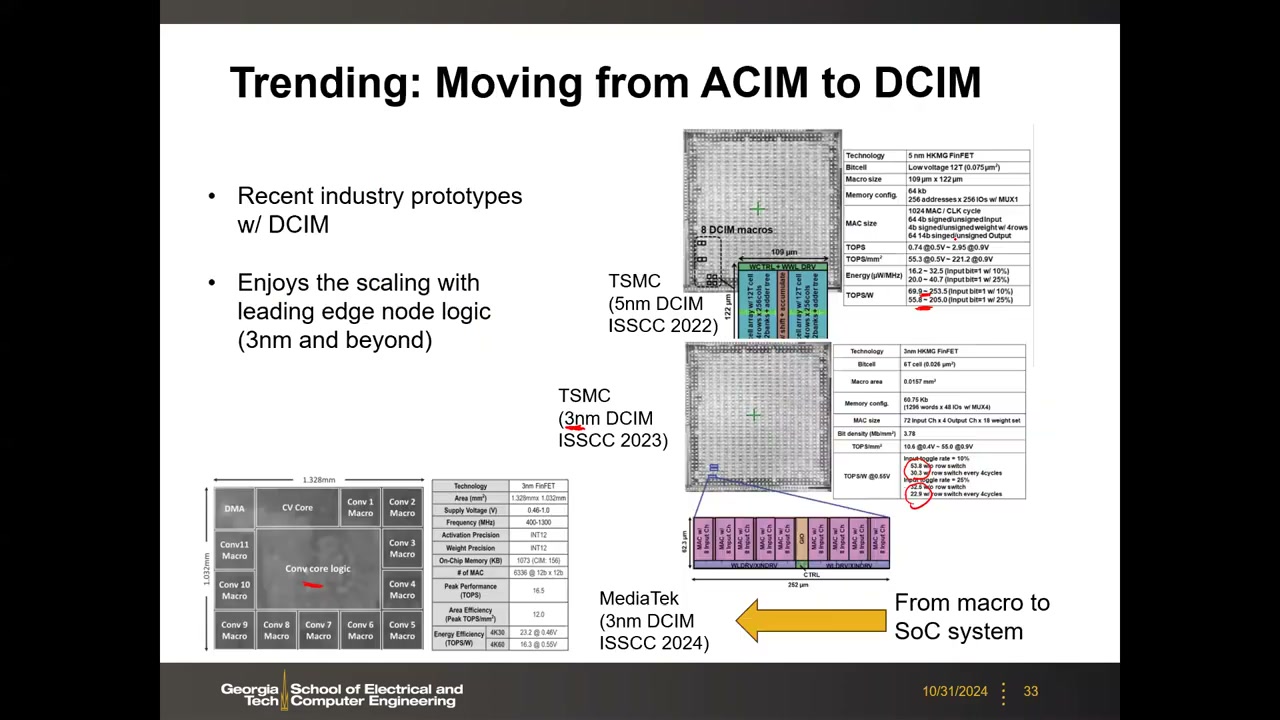
17. 数字 CIM(DCIM):从模拟回到数字 01:11:55
新趋势:由于模拟 CIM 深受变差导致的精度下降困扰,业界正在从模拟转回数字——数字计算无噪声、无精度损失。TSMC 提出的 DCIM 方案(Yu-Der Chih et al., ISSCC 2021):SRAM 存权重、输入并行加载,每个 SRAM 单元旁边加一个本地逻辑门做 1-bit 乘法——从真值表可知 1-bit 乘积恰好就是一个 NOR 门;仍然多行开启保持输入并行性;部分和不再用电流求和,而是经加法树(adder tree)做数字累加,再做 shift/add。
代价与收益:加法树的面积/能耗使 DCIM 的效率低于电流求和,加法树成为新的瓶颈;但它彻底消除了噪声、无精度损失,并且能完整享受先进逻辑节点的 scaling(3nm 及以后)。产业原型迭代:TSMC 5nm DCIM(ISSCC 2022,12T 单元)→ TSMC 3nm DCIM(ISSCC 2023,6T 单元,0.0157 mm² 宏)→ MediaTek 3nm DCIM(ISSCC 2024)把宏集成进带主处理器的完整 SoC——从宏走向系统。能效与输入稀疏度相关(输入翻转率 10%~25% 等不同条件):3nm 演示从几十到 100+ TOPS/W(4b×4b 口径),归一化到 8b×8b 后仍可达数十 TOPS/W 量级。
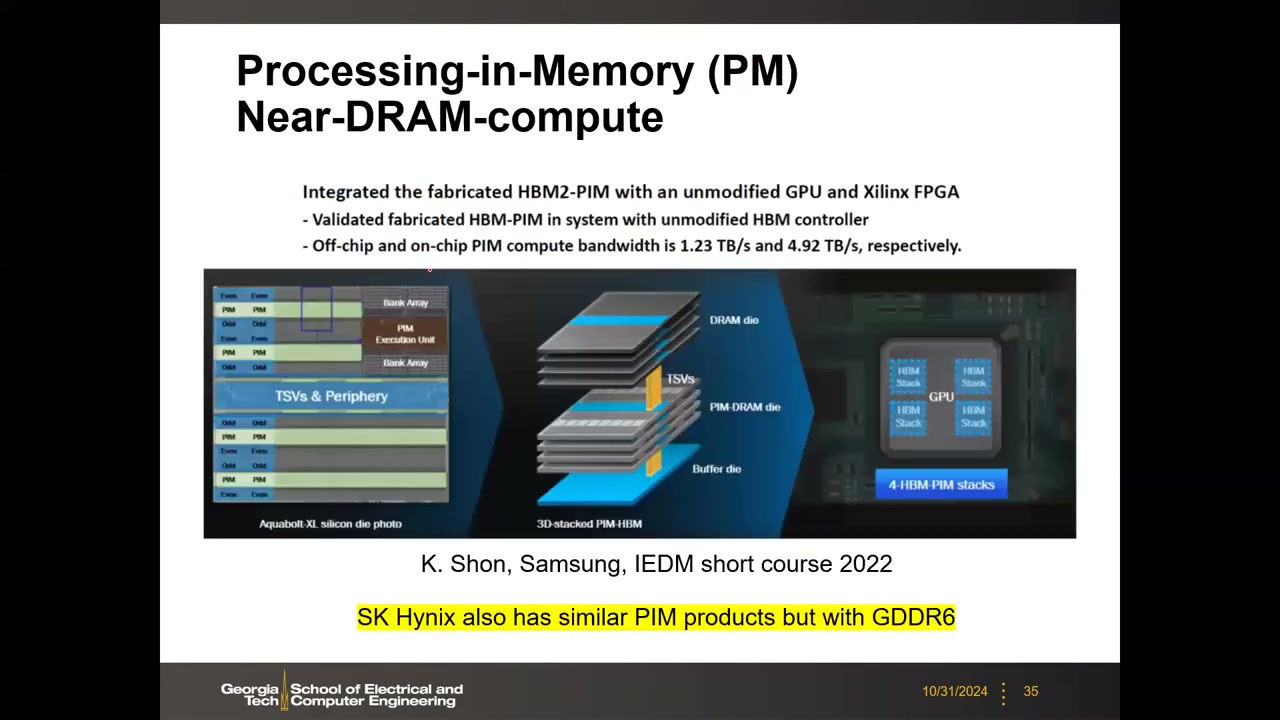
18. 大模型加速:DRAM PIM(近 DRAM 计算) 01:15:29
大语言模型是"DRAM 的天下",因此 Samsung、SK Hynix 都推出了 PIM(Processing-In-Memory)/ 近 DRAM 计算产品。Samsung HBM-PIM(Aquabolt-XL,已上市):在 DRAM bank 旁增加 MAC 单元。微架构三大组成:16 通道 FP16 SIMD FPU 阵列(16 个 FP16 乘法器 + 16 个加法器,支持浮点);命令/通用/标量寄存器堆(CRF、GRF、SRF);PIM 单元控制器(取指、译码、流水线控制)。PIM 单元位于每个 2D DRAM die 上,而不是逻辑基底 die 上。
系统验证:HBM2-PIM 与未修改的 GPU + Xilinx FPGA 集成验证;片外 / 片上 PIM 计算带宽分别为 1.23 TB/s 和 4.92 TB/s。SK Hynix 也有类似 PIM 产品,但基于 GDDR6 而非 HBM。

19. 总结与展望 01:18:34
Outlook 页要点(因时间关系讲者口头略过,以下为幻灯片内容):
- 存内计算省去中间数据搬运,可同时提升吞吐和能效。
- 先进节点的 Compute-in-SRAM(尤其 DCIM)在能效与吞吐上仍是最佳选择。
- 今日的 RRAM 可通过迭代编程调成多级阻态;离线训练 + 仅推理是最合适的应用,凭借低漏电、非易失优势面向边缘计算。
- 模拟 CIM 的轻微推理精度下降源于工艺变差与 ADC 偏移。
- RRAM 推理引擎仍面临高写电压、低导通电阻、ADC 开销等挑战。
- DRAM PIM 本质是近存计算方案,DRAM 外围逻辑工艺是其限制因素。
- 本领域仍在快速演进,学界与产业界都在积极投入研究。

本讲要点总结
- 动机:神经网络的权重存储与中间数据(部分和)搬运使内存成为 AI 加速的最大瓶颈;图像分类模型需 10~100 MB(最好全片上),训练比推理多 1~2 个数量级内存(ResNet:训练 21 GB vs 推理 0.12 GB),训练严重依赖 DRAM/HBM。
- 能效阶梯:能效 = 吞吐/功率(TOPS/W),1 OP 统一按 8b×8b MAC 归一化;CPU < GPU(<1)< 近存计算 TPU 类(1–10)< 存内计算目标(10–100 TOPS/W)。
- TPU/脉动阵列:TPU v1(28nm、65,536 个 8b MAC、28 MB 片上 SRAM、0.3 TOPS/W)→ v4(7nm、275 TOPS、1.62 TOPS/W);脉动阵列靠权重驻留 + 输入/部分和在最近邻 PE 间逐周期流动实现数据复用。
- 全局缓冲替换:判据(10~100 MB、<3 ns、>1E14 耐久、保持秒级即可)排除了 RRAM/PCM/MRAM;唯一候选是氧化物沟道(IWO)2T 增益单元 eDRAM——对 3nm SRAM 面积 -56%、漏电 -43%,且 BEOL 可堆叠。
- CIM 原理:输入加电压于字线、权重存为电导,欧姆定律做乘法、基尔霍夫电流定律沿位线求和,ADC 量化后移位累加;与常规存储的本质区别是同时开多行。
- SRAM ACIM:8T 读解耦单元最常用(6T 多行开启有读干扰);TSMC 7nm 宏(ISSCC 2020)归一化后约 88 TOPS/W,但 foundry 紧凑设计规则限制了位单元修改自由度。
- RRAM ACIM:NTHU/TSMC 22nm 4Mb 宏(ISSCC 2021)归一化后约 12 TOPS/W;低导通电阻限制一次只能并行开 4 行;同节点密度是 SRAM 的 2.5×~5×,适合低占空比边缘推理。
- 模拟 CIM 的根本挑战:PVT 变化导致不可避免的精度下降(GaTech 40nm 实测:CIFAR-10 在 120°C 从 92% 跌至约 80%/86%);安全攸关场景不宜采用。
- write-verify 与应用边界:CIM 要求阻值分布紧贴理想值,必须迭代写校验——因此 RRAM CIM 只适合离线训练后的推理,难以原位训练。
- 电荷域 ACIM:交叉点用可编程电容(nvCap),只有动态功耗,能量 0.96 pJ,比电阻式(21~193 pJ)低 10~100 倍,且唯一支持 BEOL 堆叠。
- DCIM 趋势:SRAM + NOR 门 1-bit 乘法 + 加法树数字累加,无噪声无精度损失、随逻辑节点 scaling(TSMC 5nm/3nm、MediaTek 3nm SoC);加法树是新瓶颈,归一化能效仍达数十 TOPS/W。
- 大模型加速:TB 级 LLM 是 DRAM 的天下;Samsung HBM-PIM(bank 旁 FP16 SIMD FPU,片上带宽 4.92 TB/s)与 SK Hynix GDDR6-PIM 本质是近存计算,受限于 DRAM 内老旧逻辑工艺(约 65nm 等效),理想方案是与先进逻辑 die 混合键合。
术语表
| 术语 | 中文 | 说明 |
|---|---|---|
| In-Memory Computing (IMC) / CIM | 存内计算 | 将计算(主要是乘累加)直接在存储阵列内/旁完成,避免数据搬运的架构范式。 |
| Near-Memory Computing | 近存计算 | 计算单元靠近存储(如 TPU 的 PE+共享 SRAM),但计算与存储仍分离,能效约 1-10 TOPS/W。 |
| Processing-In-Memory (PIM) | 存内处理 | 业界(三星/海力士)对在 DRAM bank 旁加计算单元方案的称呼,本质是近存计算。 |
| MAC (Multiply-and-Accumulate) | 乘累加 | 神经网络核心运算:先乘后加;能效统一以 8b×8b MAC 为 1 个操作计。 |
| TOPS/W | 每瓦太拉操作数 | 能效指标 = 吞吐量(TOPS)/ 功率(W)。 |
| Memory Wall | 存储墙 | 冯·诺依曼架构中处理器与存储间数据搬运成为性能/能耗瓶颈的现象。 |
| Weight Stationary | 权重固定 | 数据流策略:权重驻留在存储/PE 中不动,只移动输入和输出。 |
| Systolic Array | 脉动阵列 | 2D PE 阵列,数据像波前一样逐周期在相邻 PE 间传递,输入垂直流动、部分和水平流动。 |
| PE (Processing Element) | 处理单元 | 含数字乘法器、加法器和本地寄存器的基本计算单元。 |
| TPU (Tensor Processing Unit) | 张量处理单元 | Google 的数字脉动阵列 AI 加速器。 |
| Unified Buffer / Global Buffer | 统一缓冲/全局缓冲 | TPU 中存放权重与激活的大容量共享 SRAM(v1 为 24 MB)。 |
| Partial Sum | 部分和 | 乘累加过程中的中间累加结果,CIM 中对应位线求和电流。 |
| ACIM (Analog CIM) | 模拟存内计算 | 利用欧姆定律和基尔霍夫电流定律在模拟域做乘法与电流求和的 CIM。 |
| DCIM (Digital CIM) | 数字存内计算 | SRAM 单元旁加 NOR 门做 1-bit 乘法、用加法树数字累加的 CIM,无精度损失。 |
| ADC | 模数转换器 | 把位线求和电流/电压量化回数字位的电路,是 ACIM 的主要开销之一。 |
| Shift-and-Add | 移位累加 | 多个 1-bit 单元拼成多位权重时,按 MSB/LSB 位权重构部分和的操作。 |
| 8T SRAM (Read-decoupled) | 8 管读解耦 SRAM | 增加独立读路径的 SRAM 单元,多行开启时无读干扰,ACIM 常用。 |
| Read Disturb | 读干扰 | 多行同开时位线过度放电破坏 6T SRAM 存储数据的风险。 |
| 1T1R | 一管一阻 | 一个选通晶体管串联一个 RRAM 电阻的位单元,电导代表权重。 |
| RRAM (ReRAM) | 阻变存储器 | 基于氧空位导电细丝的非易失存储器,量产最先进节点 22nm。 |
| MLC (Multi-Level Cell) | 多级单元 | 一个单元存多于 1 bit(多个阻值/电容级),可提升密度但可靠性要求更高。 |
| Write-Verify | 写校验 | 迭代写入并验证以收紧阻值分布的编程方法;使 RRAM CIM 只适合推理而难以原位训练。 |
| PVT Variation | 工艺/电压/温度变差 | 模拟电路固有的变差来源,导致 ACIM 不可避免的精度下降。 |
| ECC (Error Correction Code) | 纠错码 | 用于缓解 CIM 输出误差的冗余编码(如 (16,10) MAC-ECC)。 |
| Gain Cell (2T eDRAM) | 增益单元 | 两晶体管无电容 eDRAM,靠读管跨导非破坏性读出;氧化物沟道(IWO)可把保持时间提到秒级。 |
| IWO (Indium-Tungsten-Oxide) | 铟钨氧化物 | 宽禁带氧化物半导体沟道材料,超低关态漏电,BEOL 兼容。 |
| BEOL (Back-End-Of-Line) | 后道工艺 | 金属互连层工艺;BEOL 兼容器件可堆叠在 CMOS 上方实现 3D 集成。 |
| Charge-Domain Computing | 电荷域计算 | 用可编程电容(nvCap)做 V×C 电荷转移计算,只消耗动态功耗,能耗比电流域低 10~100 倍。 |
| nvCap | 非易失电容 | 可编程为高/低电容两态的交叉点器件(如铁电电容 CFE)。 |
| Adder Tree | 加法树 | DCIM 中对各行 1-bit 乘积做数字累加的树状加法器结构,是 DCIM 的面积/能耗瓶颈。 |
| HBM (High Bandwidth Memory) | 高带宽存储器 | 多层 2D DRAM 的 3D 堆叠(如 12 层),通过 2.5D 集成(CoWoS)与 GPU 相连。 |
| HBM-PIM (Aquabolt-XL) | 三星 HBM 存内处理产品 | 在每个 DRAM die 的 bank 旁集成 FP16 SIMD FPU 的 PIM。 |
| Hybrid Bonding | 混合键合 | 将 DRAM die 与先进逻辑 die 直接键合的 3D 集成技术,可绕开 DRAM 内老旧逻辑工艺的限制。 |
| IFM / OFM | 输入/输出特征图 | 卷积层的输入与输出张量;权重映射需把 4D kernel 张量展开到 2D 存储阵列。 |
| Inference / Training | 推理 / 训练 | 推理只读权重,内存约等于模型大小;训练需存储并跨 batch 累积中间数据,内存需求高 1~2 个数量级。 |