Lecture 8:阵列设计(Array Design)
1. 子阵列与外围电路总体架构 P1 00:00:40
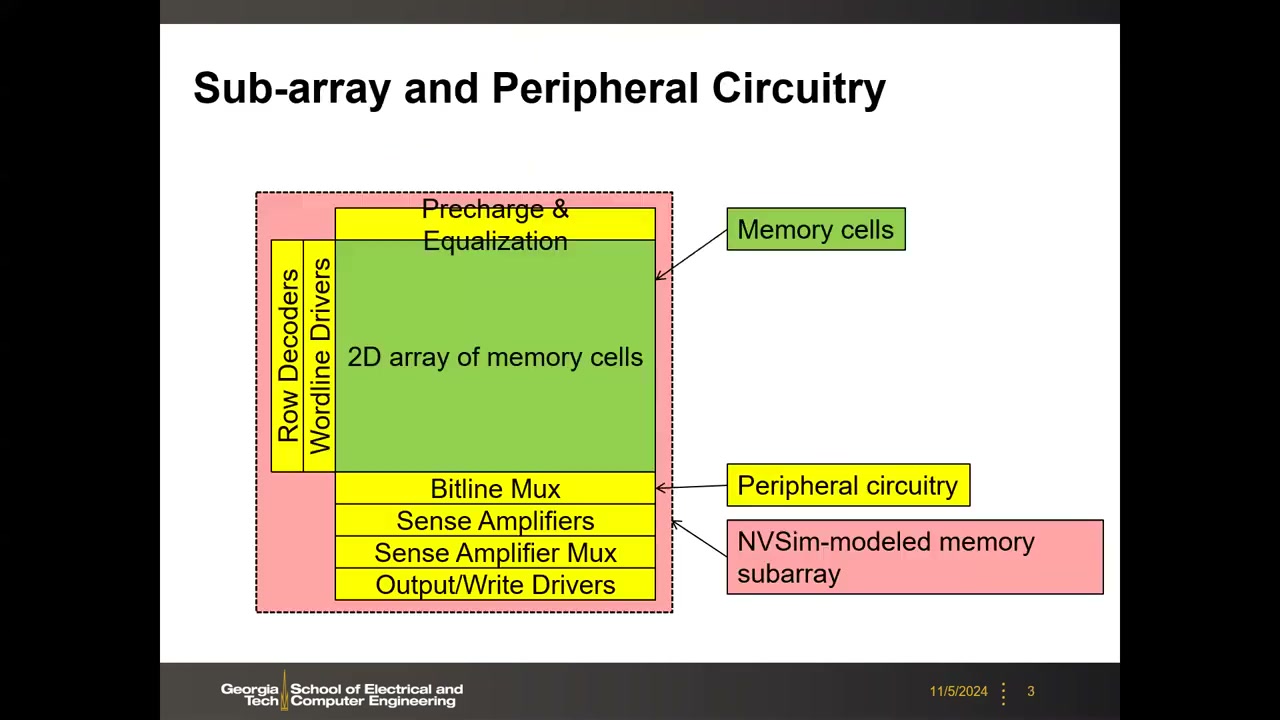
从前面几讲的存储器件转向阵列级设计。Sub-array(子阵列)定义为字线(WL)和位线(BL)被"截断"(break)的最小单元,是整个存储器层次结构的基本块。阵列主体是 2D 存储单元阵列(3D NAND 除外),单元可以是 SRAM、DRAM 或新型存储器(1T1R、cross-point),位于每个 WL 与 BL 的交叉点上(可能含选择晶体管 + 存储元件)。
围绕阵列的外围电路模块(NVSim 建模的 subarray 正是包含这些):
- 行译码器(Row Decoder):译码行地址;
- 字线驱动器(Wordline Driver):WL 很长、负载电容大,需驱动器保证 WL 充电满足时序;
- 位线 MUX(Bitline Mux):若不同时读出所有列,多列可共享同一个灵敏放大器,用 MUX 选列;
- 灵敏放大器(Sense Amplifier, SA):读出信号放大;
- SA 后级 MUX:并非所有 SA 结果都需送往外部 IO,再次选择;
- 输出/写驱动器(Output/Write Drivers):IO 驱动;
- 预充与均衡电路(Precharge & Equalization):如 SRAM 读操作前把 BL/BLB 预充到 VDD。
这张框图是全讲的"地图"——本讲前半部分逐一展开各模块,也是 NVSim 等阵列级仿真器的建模对象。
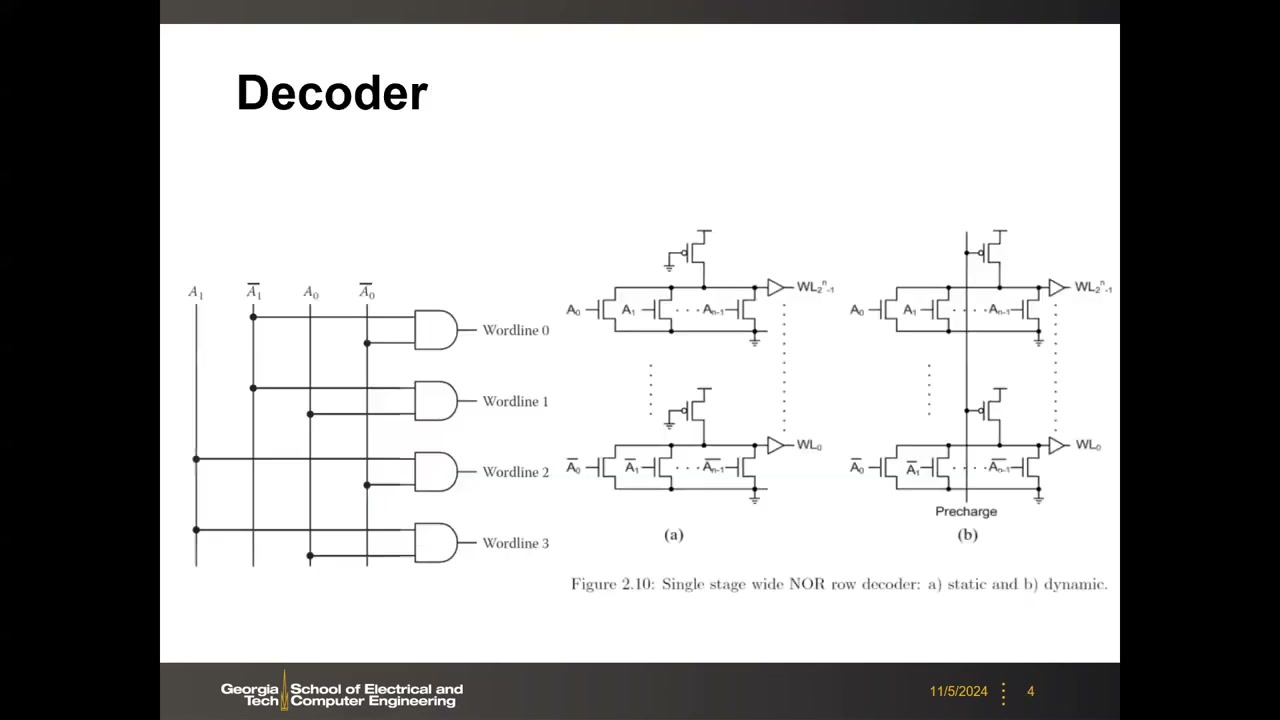
2. 译码器设计:静态/动态逻辑与两级预译码 P1 00:03:28
行/列地址都需要译码器:n 位地址输入 → 2n 条输出线(例:2 位地址 A1A0 及其互补信号 → 4 条字线,互补信号可用反相器产生)。幻灯片给出"单级宽 NOR 行译码器"的两种 CMOS 实现:
- 静态版本:NMOS 并联下拉 + PMOS 串联上拉(全 CMOS NOR 门)+ 输出缓冲驱动 WL;
- 动态版本:时钟控制的 PMOS 预充输出节点,再按译码结果通过 NMOS 网络放电——动态逻辑通常更快。
面积问题:地址位数多时,全 CMOS NOR 的 n 个 PMOS 串联堆叠开销极大。替代方案有伪 NMOS(单个常通 PMOS 作上拉负载,省面积,但非轨到轨、有静态功耗)和动态逻辑(需时钟控制,速度更快)。
两级译码(预译码 pre-decoding):输入地址 ≥ 6–8 位时必须采用。例:4 位输入 → 两个 2-to-4 预译码器(第一级),其输出作为第二级输入,最终得到 16 路输出。大阵列(128 行 = 7 位地址、256 行 = 8 位)必用两级,否则 8 输入逻辑门的扇入(fan-in)过大、不可接受。预译码是所有大容量存储器的通用做法。
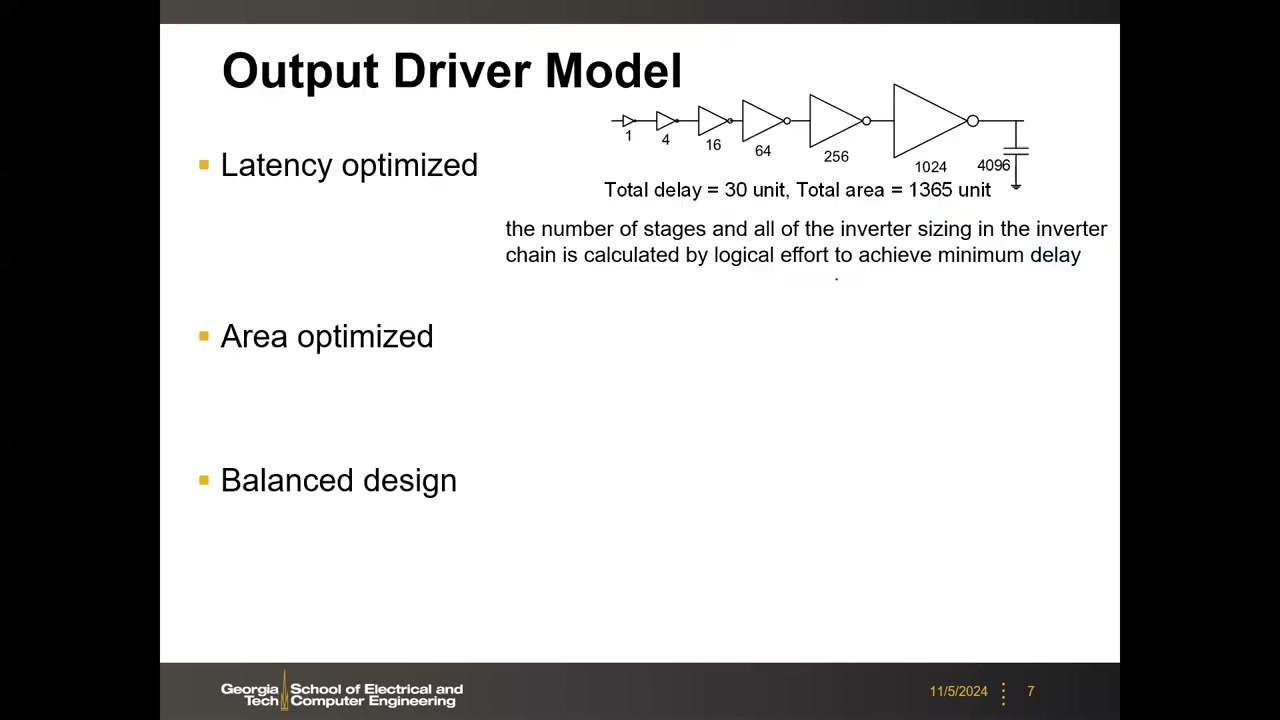
3. 字线驱动器:延迟—面积折中 P1 00:09:08
译码后的信号要驱动很长的字线(接很多列),等效为大电容负载;为满足时序要求,需在译码器后接若干级逐级放大尺寸的反相器链(driver = inverter chain)。最优级数与各级尺寸可用数字 VLSI 的逻辑努力(logical effort)方法求得。
量化例子(驱动 4096 单位电容,单位 = 最小 W/L 反相器;"单位延迟" = 信号通过一个单位反相器的延迟):
| 设计方案 | 反相器链 | 总延迟(单位) | 总面积(单位) |
|---|---|---|---|
| 延迟优化(latency-optimized) | 6 级:1→4→16→64→256→1024 | 30 | 1365 |
| 面积优化(area-optimized) | 仅 2 级 | ≈130 | ≈65 |
| 平衡设计(balanced) | 固定链 | ≈80 | 不显著增加 |
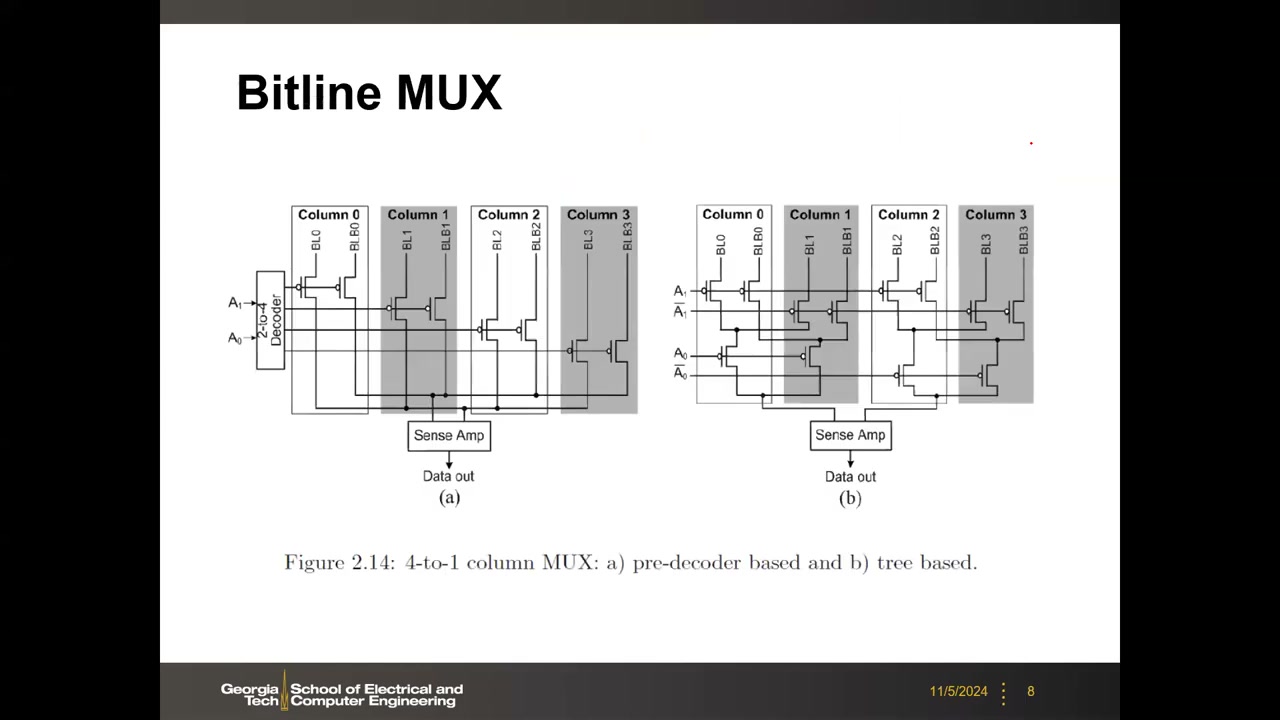
4. 位线 MUX(列选择):预译码式 vs 树形 P1 00:13:37
列 MUX 决定哪一列接入 SA,即 SA 的共享比。两种 4 选 1 设计:
- (a) 预译码式(pre-decoder based):2 位地址 → 2-to-4 译码器 → 4 路输出各控制一行传输门/单管 pass gate(NMOS 或 PMOS 取决于控制电平极性,高电平选通用 NMOS);任一时刻仅一路输出为 1,选通对应列(SRAM 为 BL/BLB 一对,其他存储器单根 BL);
- (b) 树形(tree based):pass 管排成 n 叉树结构,地址互补信号直接逐级控制,把译码功能并入树中。
选型结论:地址位数多时优先预译码式——译码后 pass 管只需一行、各列结构完全相同,布线(routing)更简单规整。
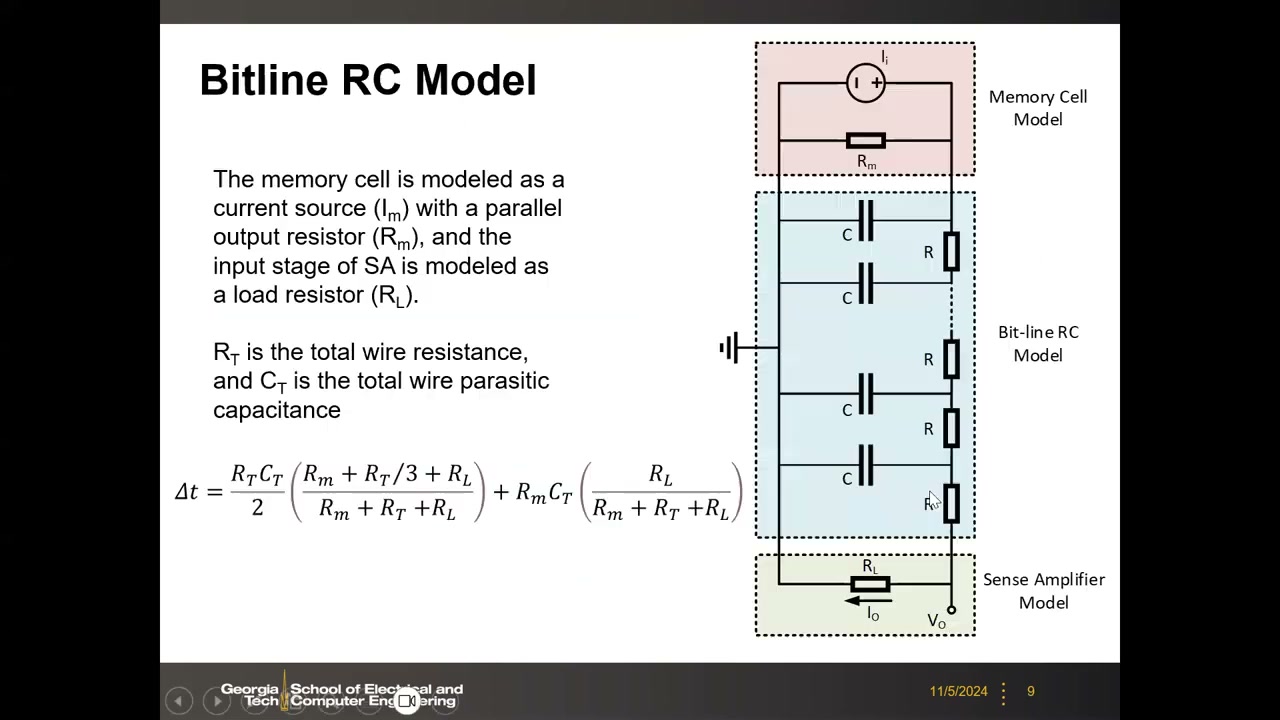
5. 位线 RC 模型与传播延迟通式 P1 00:16:31
目标:估算信号从存储单元传到 SA 的时间 Δt(位线 RC 延迟)。建模三要素:
- 存储单元 = 电流源 Im 并联输出电阻 Rm(诺顿等效;也可用电压源 + 串联电阻的戴维南形式)。Rm 的物理含义:RRAM 的单元电阻,或 SRAM 读通路(pass gate + pull-down 管沟道电阻)的等效电阻;
- 位线 = 分布式(分段)RC 网络,RT 为总导线电阻、CT 为总导线寄生电容;
- SA 输入级 = 负载电阻 RL。
解此 RC 网络得到延迟通式:
Δt = (R_T·C_T/2)·[(R_m + R_T/3 + R_L)/(R_m + R_T + R_L)] + R_m·C_T·[R_L/(R_m + R_T + R_L)]
这个公式把"器件电阻 + 互连寄生 + 读出电路输入阻抗"统一进一个延迟表达式,是阵列规模设计(每条 BL 挂多少单元)的理论基础。
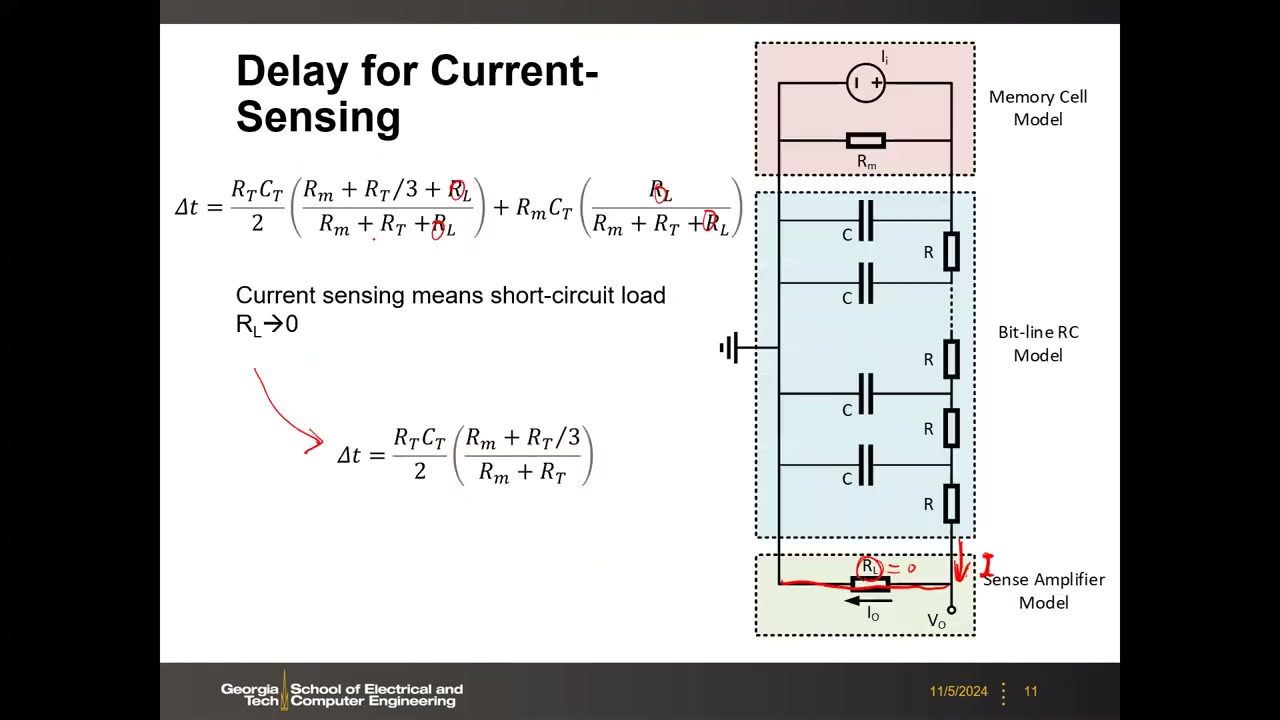
6. 电压检测 vs 电流检测:简化公式与数值对比 P1 00:20:08
区分两种读出模式只需看 SA 的输入阻抗——电压模式趋于无穷大,电流模式趋于零(实际晶体管电路只能做到"很大/很小")。对通式取极限:
- 电压检测(voltage sensing):如 SRAM/DRAM——预充 BL 后让其放电、检测电压。理想电压表 = 开路 → RL → ∞,两个含 RL 的分式都趋于 1:
Δt_v = R_T·C_T/2 + R_m·C_T - 电流检测(current sensing):测量流入 SA 的电流。理想电流表 = 零输入阻抗(近似接地)→ RL → 0,第二项消失:
Δt_i = (R_T·C_T/2)·[(R_m + R_T/3)/(R_m + R_T)]
数值算例(取自 Seevinck et al., "Current-Mode Techniques for High-Speed VLSI Circuits with Application to Current Sense Amplifier for CMOS SRAMs," IEEE JSSC, vol.26, no.4, 1991):
| 参数 | 取值 |
|---|---|
| Rm(单元等效电阻) | 2500 Ω |
| RT(位线总电阻) | 250 Ω |
| CT(位线总电容) | 2 pF |
| 电压模式延迟 δtv | 5.25 ns |
| 电流模式延迟 δti | 0.235 ns(快约 22 倍) |

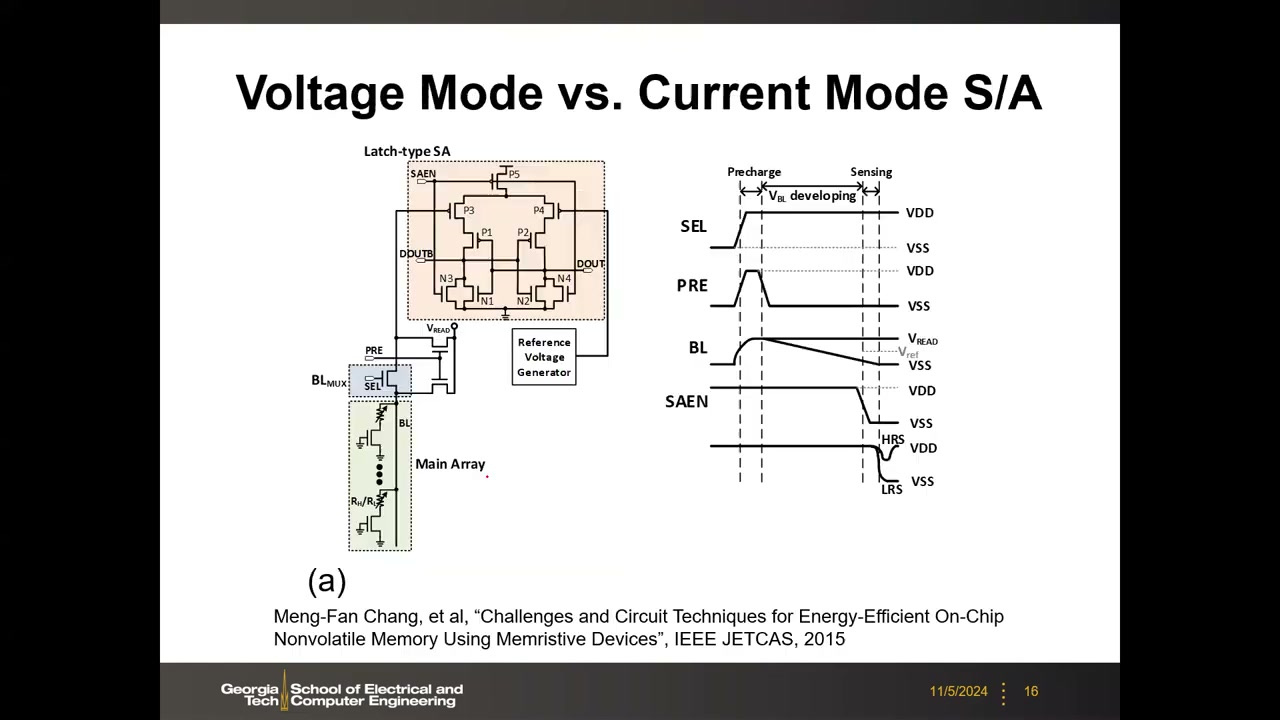
7. 灵敏放大器:外围电路创新的核心与两种电压型 SA P1 00:24:56
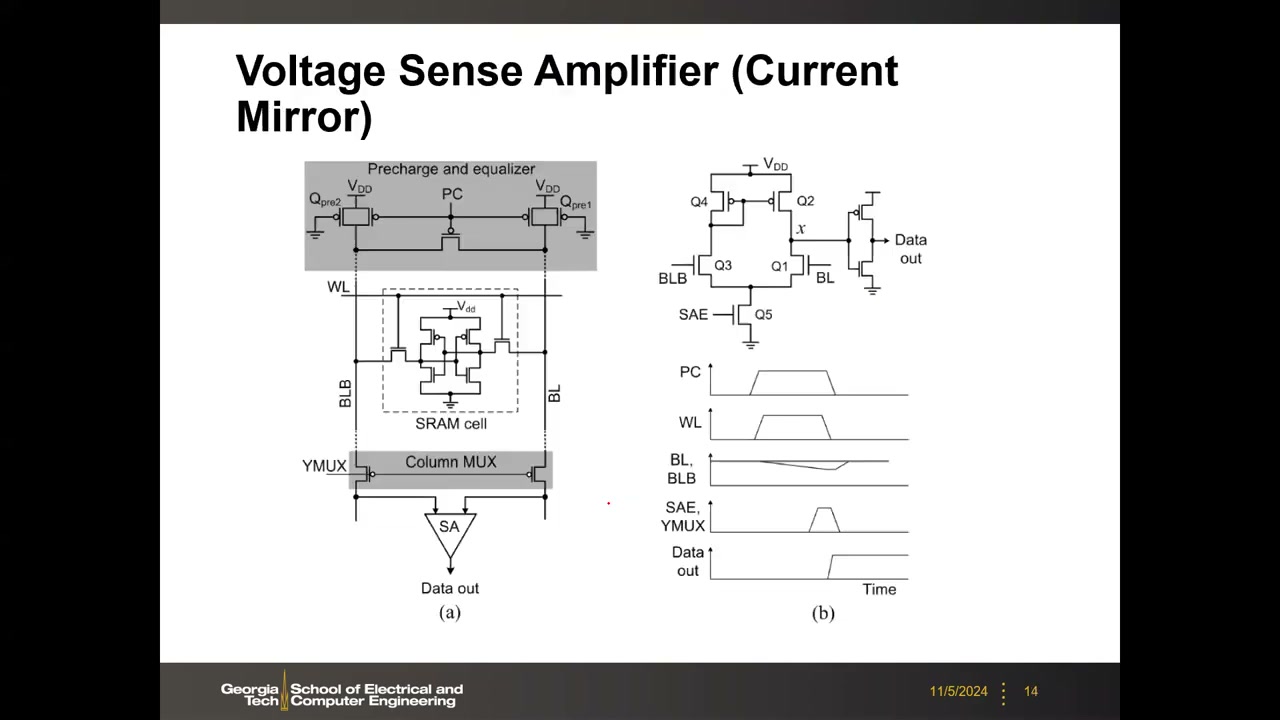
电压型 SA(一):电流镜差分放大器 P1 00:25:58
最简单的"真"差分 SA 即模拟电路的五管差分放大器:NMOS 差分对(栅极分别接 BL 和 BLB)、SAE(sense amp enable)控制的尾电流源 NMOS、PMOS 电流镜作负载(把一支电流镜像到另一支),输出经反相器得 Data out。
判别准则:信号进"栅极" = 电压模式(栅只感知电压差、不通电流);信号注入"漏/源" = 电流模式。参考端方面:SRAM 天然有 BL/BLB 互补对;单 BL 存储器需另设参考电压;DRAM 开放位线(open bitline)架构从相邻阵列借参考。配套的 Precharge & Equalizer(PC 控制)把 BL/BLB 预充至 VDD 并均衡,经列 MUX(YMUX)接入 SA。时序:PC → WL → BL/BLB 缓慢分裂 → SAE+YMUX 使能 → Data out。
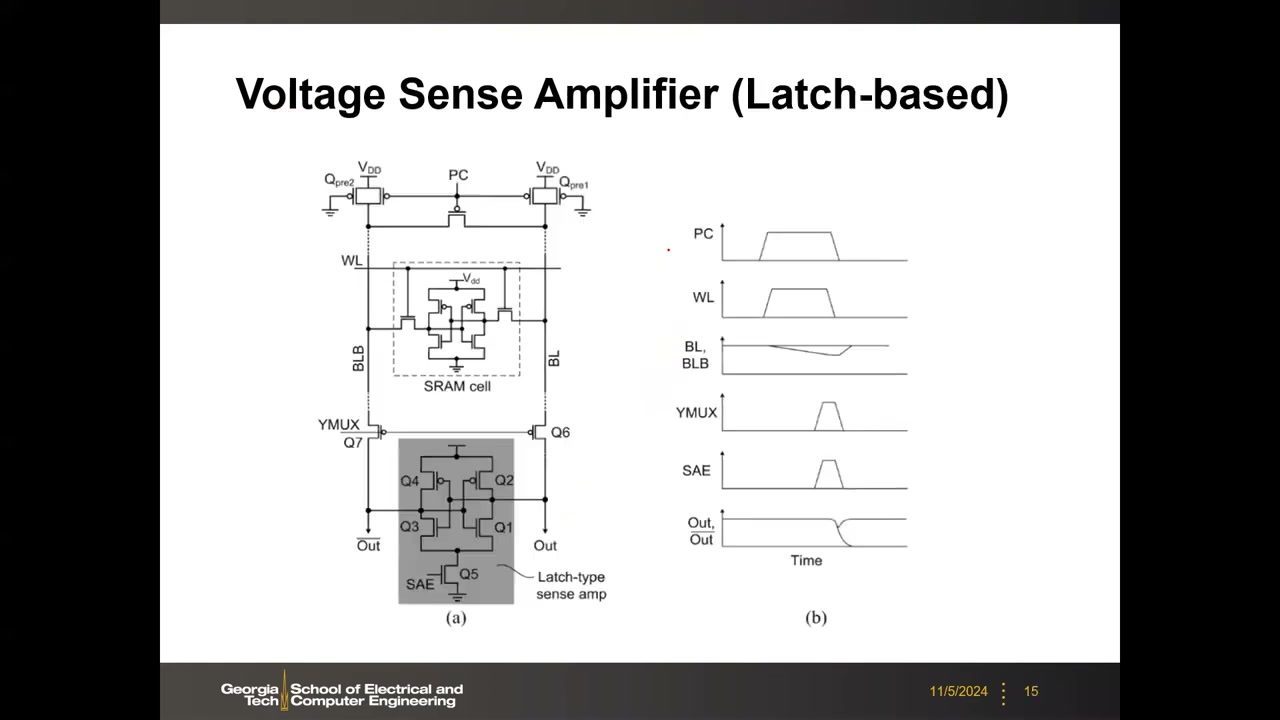
电压型 SA(二):锁存型(latch-based) P1 00:28:03
即 SRAM 讲中出现过的交叉耦合锁存结构(Q1–Q4 两个交叉耦合反相器 + SAE 尾管 Q5,经 YMUX 管 Q6/Q7 接 BL/BLB;实际通常还有 PMOS 侧的使能 SAE̅)。先预充,使能 SAE 后正反馈使 Out/Out̅ 迅速翻转,放大微小压差至全摆幅。锁存型速度快、结构省,是 SRAM/DRAM 的主流读出方案。
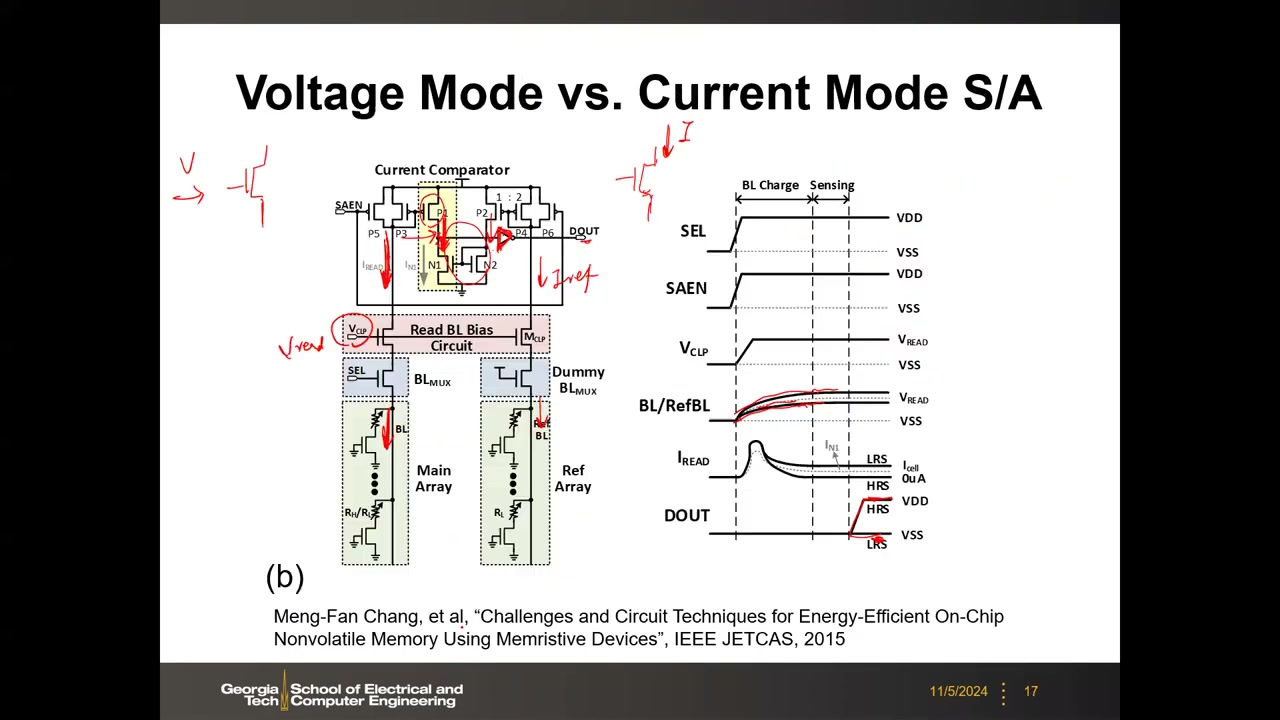
8. 实际电路:电压模式 vs 电流模式 S/A(Chang JETCAS 2015) P1 00:28:25
来源:Meng-Fan Chang 等, "Challenges and Circuit Techniques for Energy-Efficient On-Chip Nonvolatile Memory Using Memristive Devices," IEEE JETCAS 2015(Chang 教授为台湾清华大学教授、现任 TSMC 大学研究计划主任)。这一对实际电路把前面"输入阻抗 ∞/0"的抽象落实到真实晶体管,并示范了 NVM 读出的通用三阶段模板:预充 → 发展 → 判决。
| (a) 电压模式(latch-type SA) | (b) 电流模式(current comparator) | |
|---|---|---|
| 位线偏置 | PRE 管把 BL 预充到 V_READ,然后按单元电流大小放电:LRS(低阻)衰减快、HRS(高阻)衰减慢 | 钳位管(V_CLP)把 BL 电压钳在读电压附近,读电流 I_READ 由单元电阻决定 |
| 信号进入 SA 的方式 | BL 电压与参考电压分别进 PMOS 差分对的栅极 → 电压模式 | 电流镜复制 BL 电流后注入比较器晶体管的漏极 → 电流模式 |
| 参考 | Reference Voltage Generator 提供参考电压 | I_REF 来自 dummy/参考阵列:一半单元编程为高阻、一半低阻,取平均电流,再镜像 |
| 放大/判决结构 | NMOS 锁存节点正反馈翻转(比普通电流镜负载更快) | 两路电流以不同速率给节点充电产生压差,触发后级反相器翻转 |
| 时序 | ① Precharge(BL 充到 V_READ)② V_BL developing(BL 按 HRS/LRS 不同速率衰减)③ Sensing(SAEN 使能——本例为 PMOS 控制故拉低使能,DOUT 按状态保持或翻转) | ① BL 从 0 充电(按电流大小速率不同)至钳位电压(≈V_READ)② 使能 SAEN ③ 锁存翻转,经反相器输出高/低 |
| 额外灵活性 | — | 可通过电流镜尺寸比放大(电流太小用更大管子)或缩小镜像电流 |
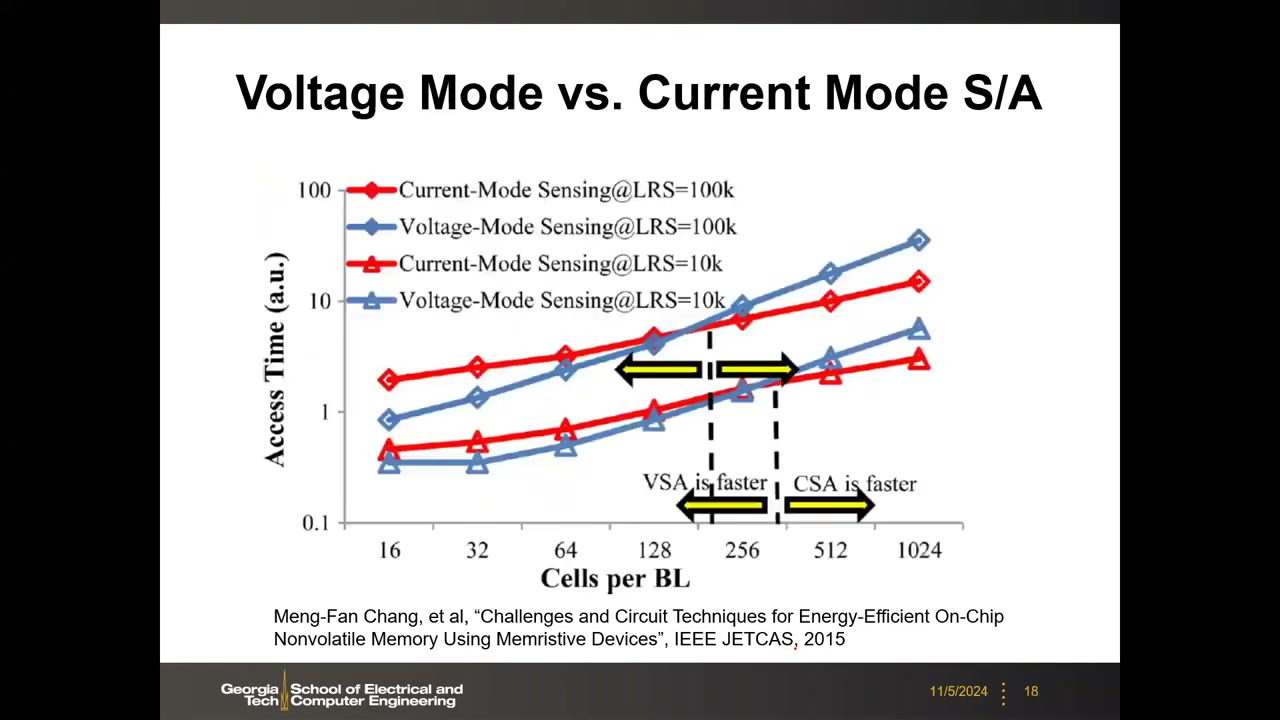
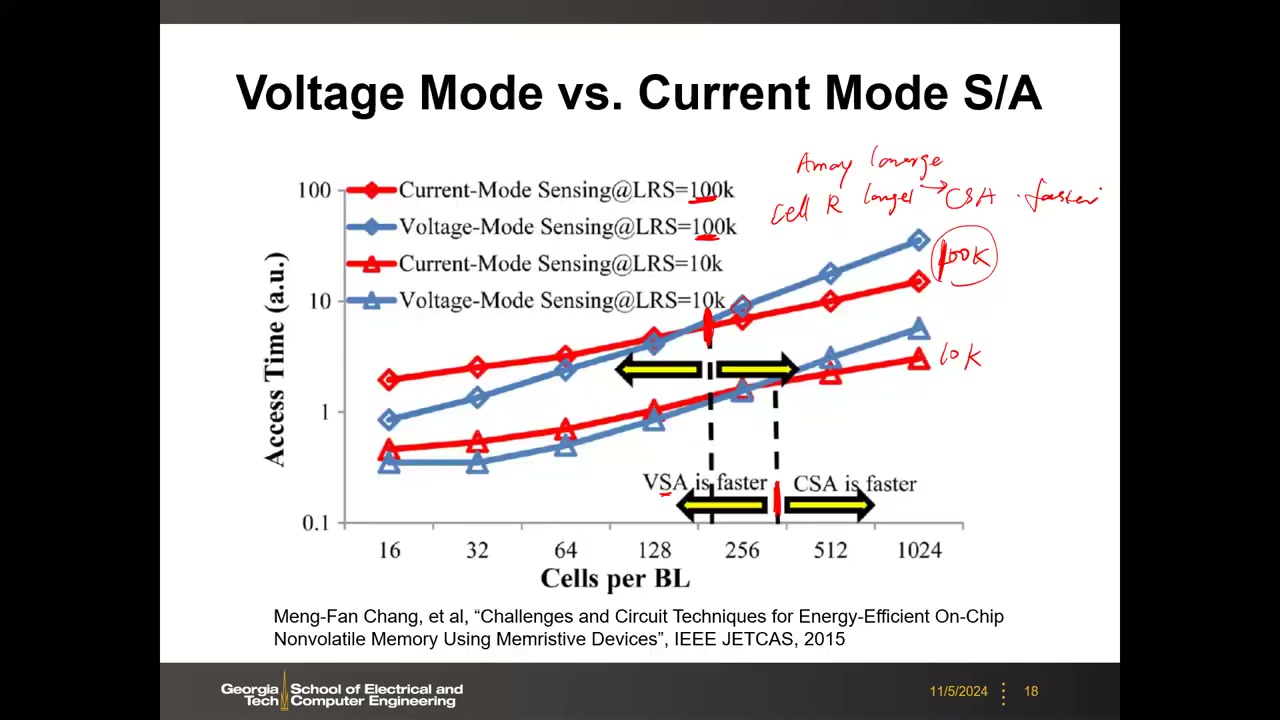
9. SA 模式选型仿真、小电流读出挑战与 NAND/NOR 速度根源 P1 00:36:38
用真实电路(非近似公式)做 SPICE 仿真:读出时间 vs 每条 BL 上的单元数(16→1024),LRS = 10 kΩ 与 100 kΩ 两组(Chang JETCAS 2015)。结论:
- 阵列小(BL 上单元少)→ 电压模式(VSA)更快;阵列大 → 电流模式(CSA)更快,存在盈亏平衡点(约几百单元/BL);
- 单元电阻越低读出越快(RC 小);电阻从 10 kΩ 提高到 100 kΩ,盈亏平衡点左移——即阵列越大、单元电阻越大(读电流越小),电流模式优势越明显(板书:Array large / Cell R larger → CSA faster)。
小电流快速读出的挑战与 offset P1 00:38:55
小电流/高电阻读出 → RC 时间常数大 → 读出极慢。应用到 Flash:NAND Flash 串中多个晶体管串联,每管都贡献串联电阻 → 等效 Rm 高、读电流极小(约 100 nA 量级)→ 典型读出时间 ≥10 μs;NOR Flash 每个单元直接并联接 BL、读电流大(μA 量级)→ 读出仅几十 ns。这就是 NAND 慢、NOR 快的电路本质。
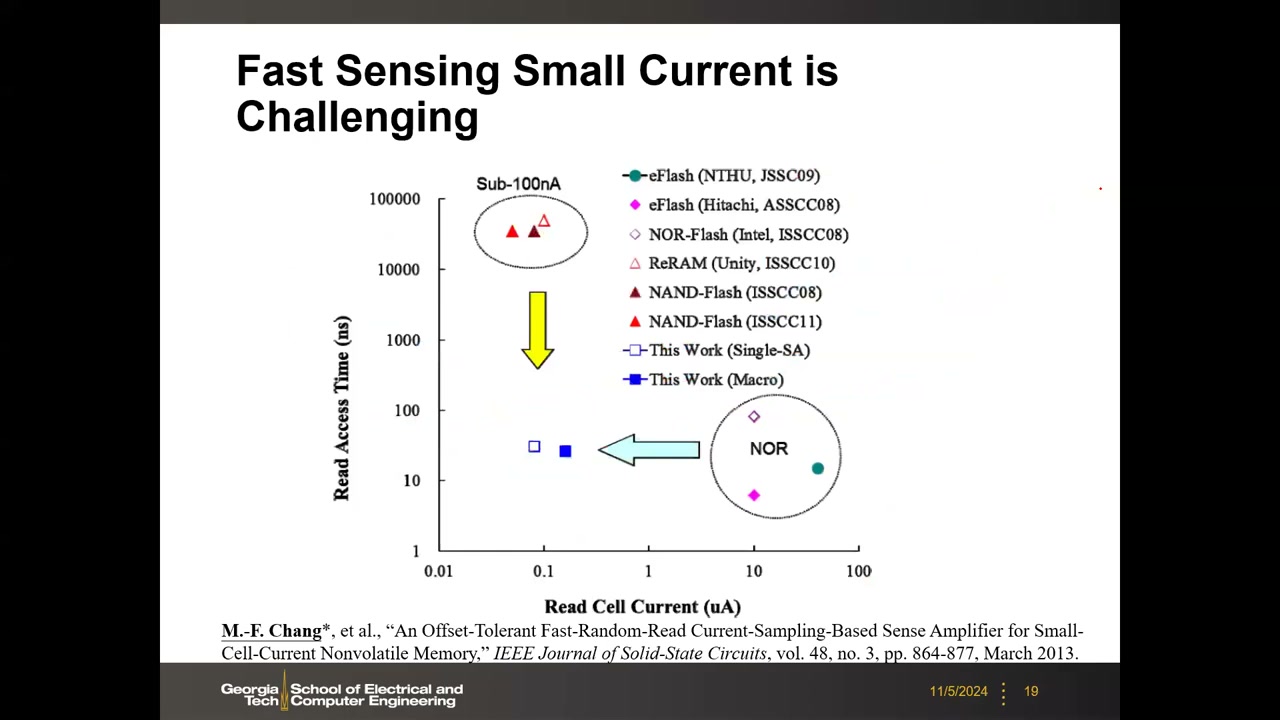
解决方向是电路创新:M.-F. Chang 等, "An Offset-Tolerant Fast-Random-Read Current-Sampling-Based Sense Amplifier for Small-Cell-Current Nonvolatile Memory," IEEE JSSC, vol.48, no.3, 2013——对 ~100 nA 小电流仍实现几十 ns 读出(散点图中"This Work":读电流 ~0.1 μA、读出时间 ~30 ns,相比 sub-100nA 的 NAND/ReRAM 的 10⁴–10⁵ ns 改善数个量级)。
Offset(失调)问题:所有 SA(无论电压/电流模式)都有差分对,晶体管失配(Vth 变异)造成内建偏置 → 每个 SA 的有效参考点偏离理想中点且各不相同;当单元信号接近参考时,不同 SA 可能给出不同判决。抑制 offset 与小电流快读并列为 SA 设计的两大研究主题(上述 2013 论文即"offset-tolerant"设计)。
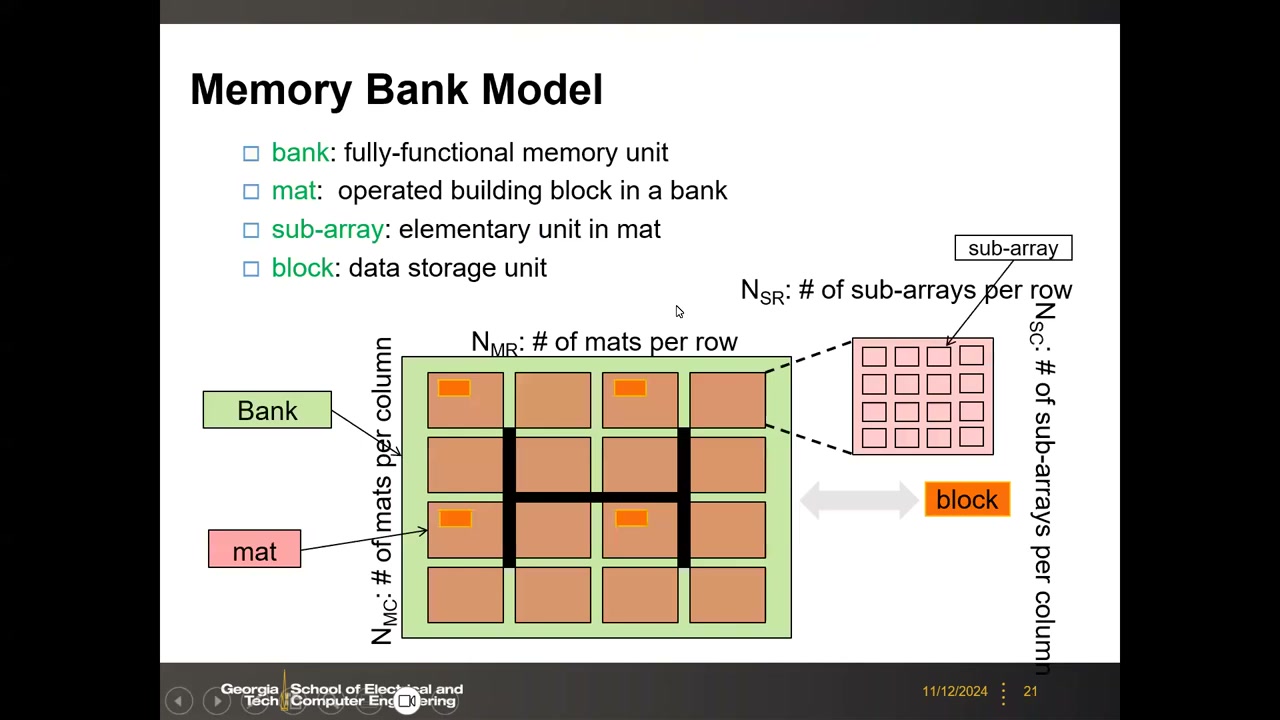
10. Memory Bank 层级组织与基本权衡 P2 00:00:24
存储器按层级组织:sub-array 是最小单元阵列(内部字线/位线不再分割);多个 sub-array 组成 mat;多个 mat 组成 bank(完整功能的存储单元);block 是数据存储单位(一次访问的数据可分布在多个 sub-array 中)。不同文献/技术对各层命名可能不同,但核心思想一致:至少 2 级层次,最多 3–4 级。关键参数(NVSim 术语):N_MR/N_MC = 每行/列 mat 数,N_SR/N_SC = 每行/列 sub-array 数。
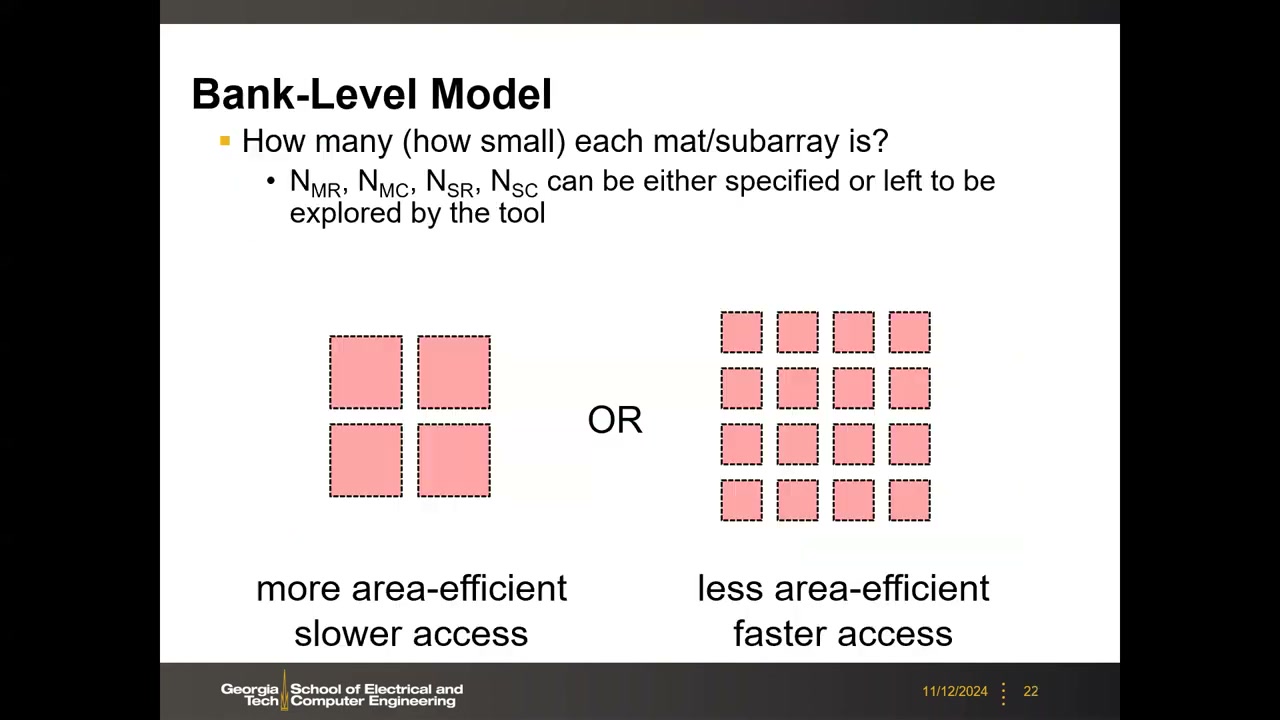
Sub-array 大小的基本权衡 P2 00:02:02
存储访问模型 P2 00:03:47:取数时不必从同一个 sub-array 取全部位(例如 64 bit 可分散到多个 sub-array 各贡献若干位),通过数据总线聚合。激活参数 N_AMR/N_AMC(每行/列激活的 mat 数)、N_ASR/N_ASC(每行/列激活的 sub-array 数)决定带宽、功耗与并行度——只激活一小部分阵列即可满足 IO 带宽,其余空闲省功耗。
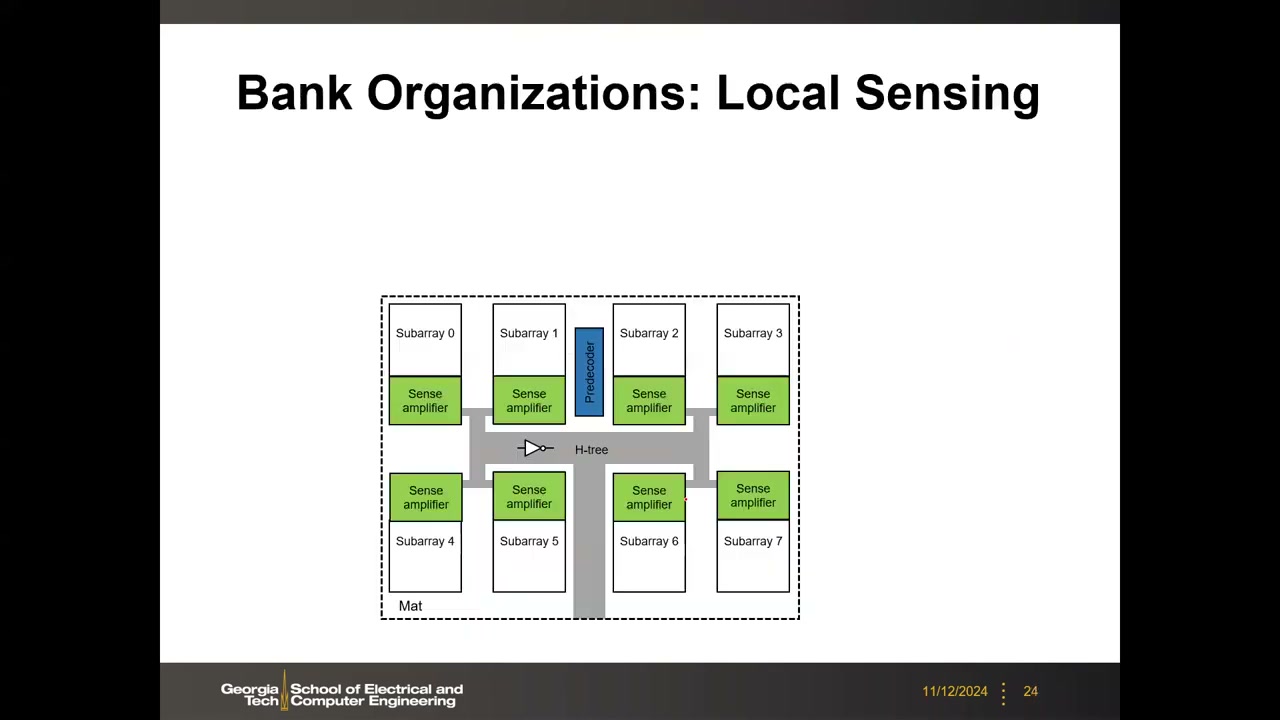
11. 局部感测(H-tree)vs 全局感测 P2 00:04:51
典型数据总线布线为 H-tree(H 形树状):全局总线逐级对称分叉(H 套 H),到各 sub-array 路径等长。两种感测组织方式对比:
| 局部感测(Local Sensing) | 全局感测(Global Sensing) | |
|---|---|---|
| S/A 配置 | 每个 sub-array 配自己的一组 S/A,在本地完成数字化 | S/A 在多个 sub-array 间共享(例:8 个 sub-array 只配 2 组 S/A,置于 mat 边缘) |
| 布线信号 | S/A 之后即为全摆幅数字信号,经 H-tree 聚合(例:8 个 sub-array 各出 8 bit,合计 64 bit) | 到达 S/A 之前是部分摆幅(partial-swing)的模拟电压/电流信号,需长导线传输 |
| 优点 | 数字信号长距离布线无信号完整性问题,速度快 | S/A 数量少,外围电路面积省 |
| 缺点 | S/A 数量多、面积开销大 | 失真与 RC 延迟副作用,信号完整性差、速度慢 |
选择取决于设计优先级:面积效率 vs 信号完整性/速度。后面 SanDisk 芯片与 NVSim 表格中的"Non-H-tree + External S/A"即全局感测方案。

12. 案例研究:SanDisk 32Gb RRAM 交叉点芯片 P2 00:08:11
出处:T. Y. Liu, et al., "A 130.7-mm² 2-Layer 32-Gb ReRAM Memory Device in 24-nm Technology", JSSC, vol.49, no.1, 2014(ISSCC 2013 首发)。当时 SanDisk(后被西部数据收购)开发的 RRAM 原型。
结构:两层交叉点(cross-point)阵列,类似 3D X-point,存储元件为"selector + RRAM 电阻"(材料未公开,标为 MeOx 金属氧化物开关层),集成在互连层之上、CMOS 外围电路之下方。关键规格:
| 指标 | 数值 |
|---|---|
| 容量 / Die 面积 | 32 Gb / 130.7 mm² |
| 接口 / 页大小 | NAND-Compatible / 2 KB |
| 读延迟 / 写延迟 | 40 μs / 230 μs |
| 半间距 F | ≈24 nm(阵列非常密) |
| 外围 CMOS 工艺 | 教授推测 180 nm 或 130 nm 老工艺(论文未公开) |
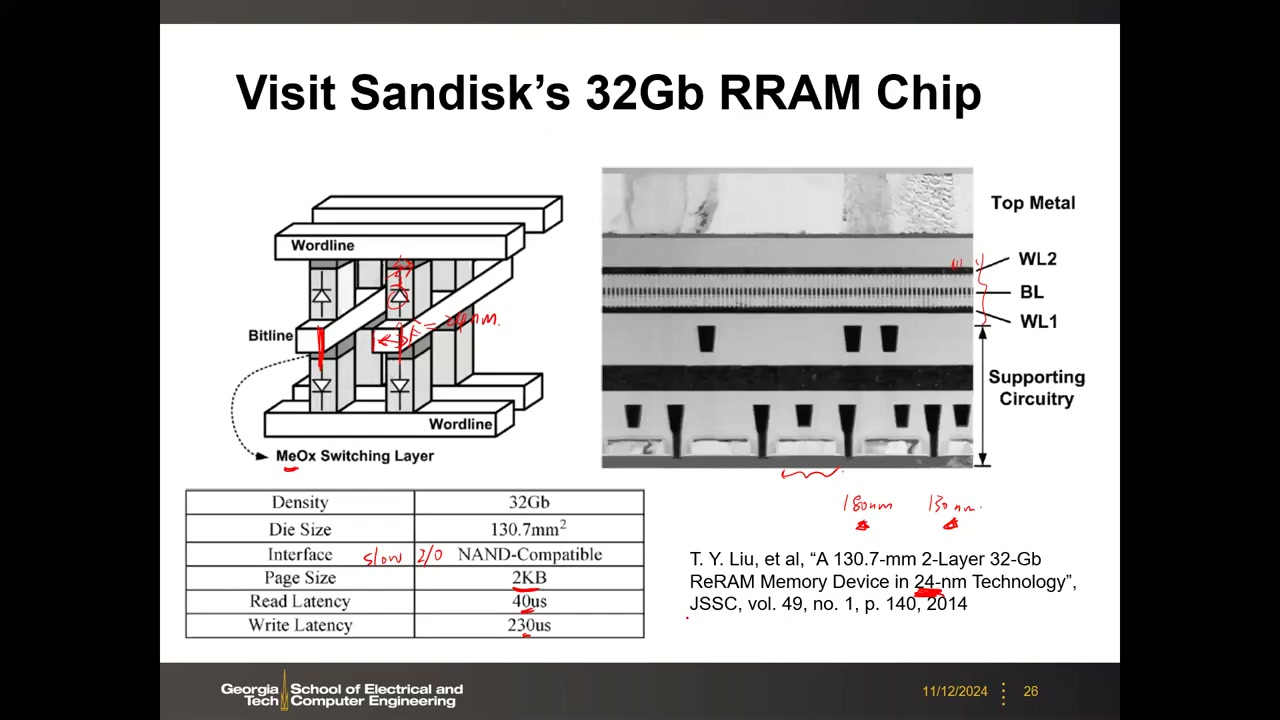
Bank 组织:共享感测导致慢速 P2 00:12:43
层级:16 个 Bay(相当于 bank)× 每 Bay 128 个 Block(4 stripes × 32 blocks);1 Block = 2K 位线 × 4K 字线 × 2 层(仅两级层次,block 即很大的 sub-array)。16 × 128 × 2K × 4K × 2 = 32 Gbit。关键限制:每个 Bay 只有 64 个 S/A 和 64 个页寄存器(每 block 对应 1 个 S/A 或 P/R)→ 一个 Bay 同时只能访问 64 bit。对比 SRAM/DRAM"每条位线一个 S/A",这是 S/A 在整个 block 范围共享的非局部感测。页大小 2KB → 每传一页需要多个内部周期把数据搬到页缓冲——这就是它只能做 NAND 兼容慢接口的原因;根本原因仍是外围逻辑工艺太老,一个 block 下方塞不下太多 S/A 晶体管。
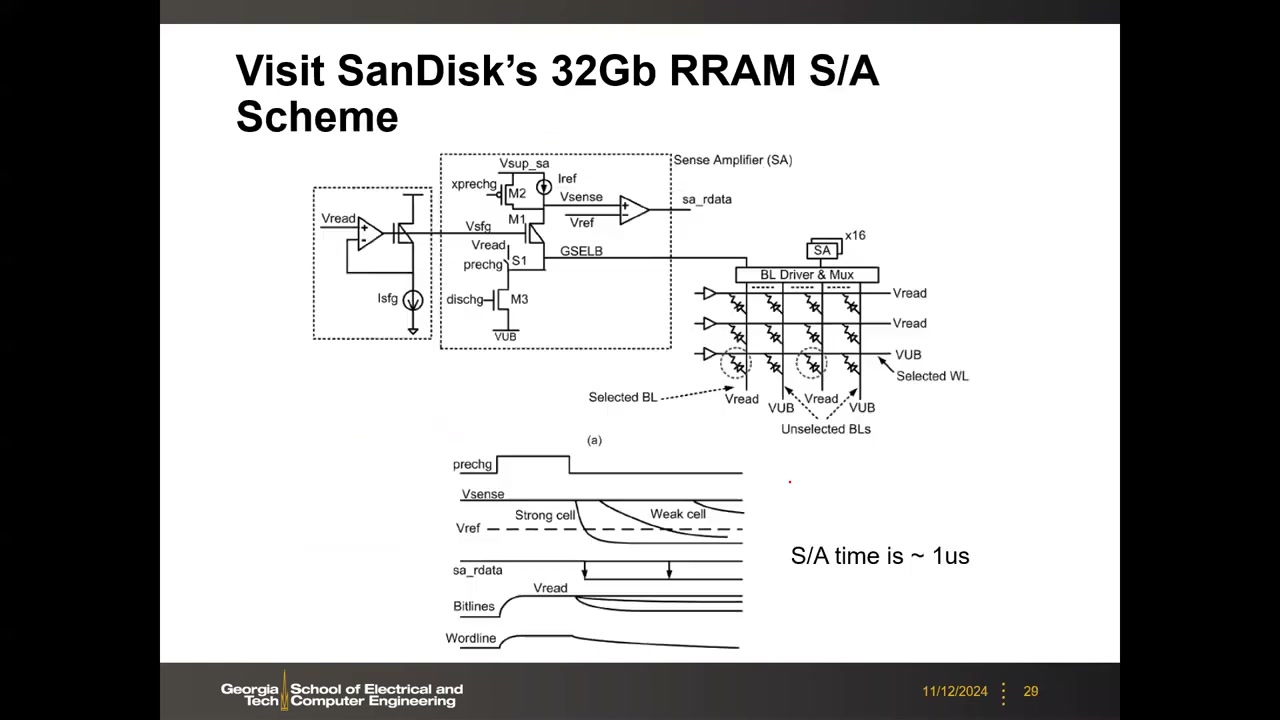
S/A 方案:电压模式感测,~1 μs/次 P2 00:17:42
电压模式感测流程:选中位线预充至 V_read,依所选单元电阻放电快慢(强单元/低阻态快、弱单元/高阻态慢),经选择 MUX 把该节点电压送入比较器与参考电压 V_ref 比较得到数字输出(sa_rdata)。未选行/列偏置在 V_UB(unselected bias)以最小化经过其他单元的漏电(潜行电流)——与前一讲交叉点阵列读偏置方案一致。电路要素:V_read 产生电路(运放+源跟随)、预充管 S1/prechg、M1/M2/Vsense/Iref、放电管 M3/dischg、BL Driver & Mux(×16 S/A)。单次感测约 1 μs;每次只得 64 bit,需多周期填满 2KB 页 → 总读延迟约 40 μs——定量解释了规格表中读延迟的来源。

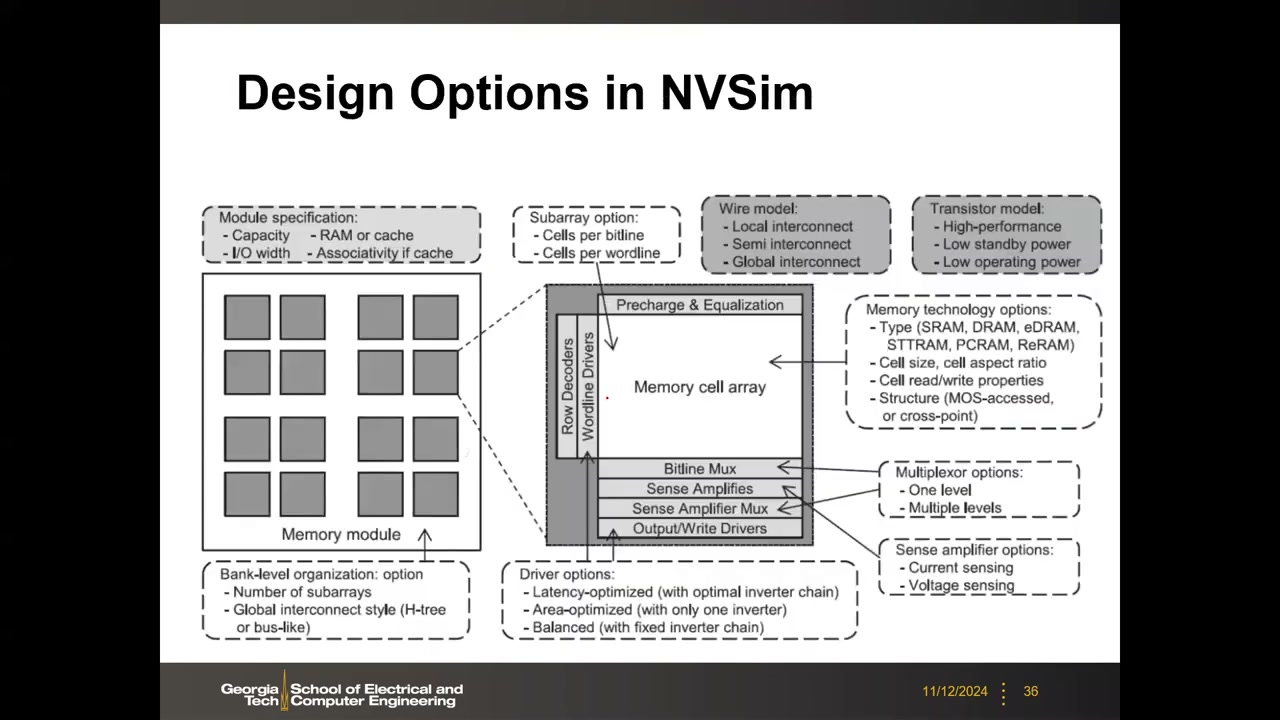
13. 为什么需要电路级模拟器:从 CACTI 到 NVSim P2 00:21:42
阵列架构设计选项太多,需要在面积、速度、功耗(动态读写功耗 + 待机漏电)之间快速权衡;早期设计阶段不可能为每个技术生成详细版图,也不是每个工艺都有 memory compiler → 需要快速估算工具。
CACTI:1990 年代起源于 HP 实验室,最初用于 SRAM 缓存估算,后扩展到嵌入式 DRAM(1T1C eDRAM)缓存;CACTI-D 针对 DRAM 主存。原作者 Norm Jouppi(HP Labs)后加入 Google 设计 TPU,是第一代 TPU 论文(ISCA 2017)第一作者。但 CACTI 不支持非易失存储器;2011 年前后 RRAM/MRAM/PCM 兴起,且 NVM 器件参数差异巨大——做架构研究时从多个来源随机拼凑器件参数是不正确的,需要自洽模型。
NVSim P2 00:24:28:由 Yuan Xie 教授课题组(当时在 Penn State,后移 UCSB、香港科大)于约 2010–2012 年开发。继承 CACTI 的 SRAM/DRAM/eDRAM 模型,在 sub-array 级和 bank 级加入修改以支持 NVM(STT-RAM、PCRAM、ReRAM 等)。本质是解析模型(analytical models)计算延迟/功耗/面积(PPA),不是 SPICE 仿真、不是综合、不是 memory compiler → 跑得快;C++ 编写,不依赖 EDA 工具。其 sub-array 模型结构与本讲第 1 节的外围电路框架完全一致。
设计选项(设计空间维度) P2 00:26:21:晶体管类型(HP / LP / Low-standby-power)、互连类型(local/semi/global wire pitch、repeater)、灵敏放大器(电流/电压感测,沿用前述解析公式)、驱动器(面积优化/延迟优化/平衡)、阵列结构(MOS-accessed 1T1R / Cross-point)、存储技术(SRAM/DRAM/eDRAM/STTRAM/PCRAM/ReRAM)、Mux 级数、bank 级组织(sub-array 数量、H-tree 或 bus-like 全局互连)。每个模块约 5 个选项相乘 → 数百甚至上千种组合,这就是设计空间探索(design space exploration)。

模型验证 P2 00:28:10:与实测芯片对比——
| 芯片 | 指标 | 实测 | NVSim 预测 | 误差 |
|---|---|---|---|---|
| 64Mb MRAM(ISSCC'10,clamped-reference) | 面积 | 39.1 mm² | 38.05 mm² | -2.69% |
| 读延迟 | 11 ns | 11.47 ns | +4.27% | |
| 写延迟 | <30 ns | 27.50 ns | — | |
| 90nm 512Mb 二极管开关 PRAM(JSSC'08) | 面积 | 91.50 mm² | 93.04 mm² | +1.68% |
| 读延迟 | 78 ns | 59.76 ns | -23.40% | |
| 写延迟 | 430 ns | 438.55 ns | +1.99% | |
| 写能耗 | 54 nJ | 47.22 nJ | -12.56% |
多数指标误差在个位数百分比、个别约 20%——这是解析模型可信度的量级,足以支撑架构探索。
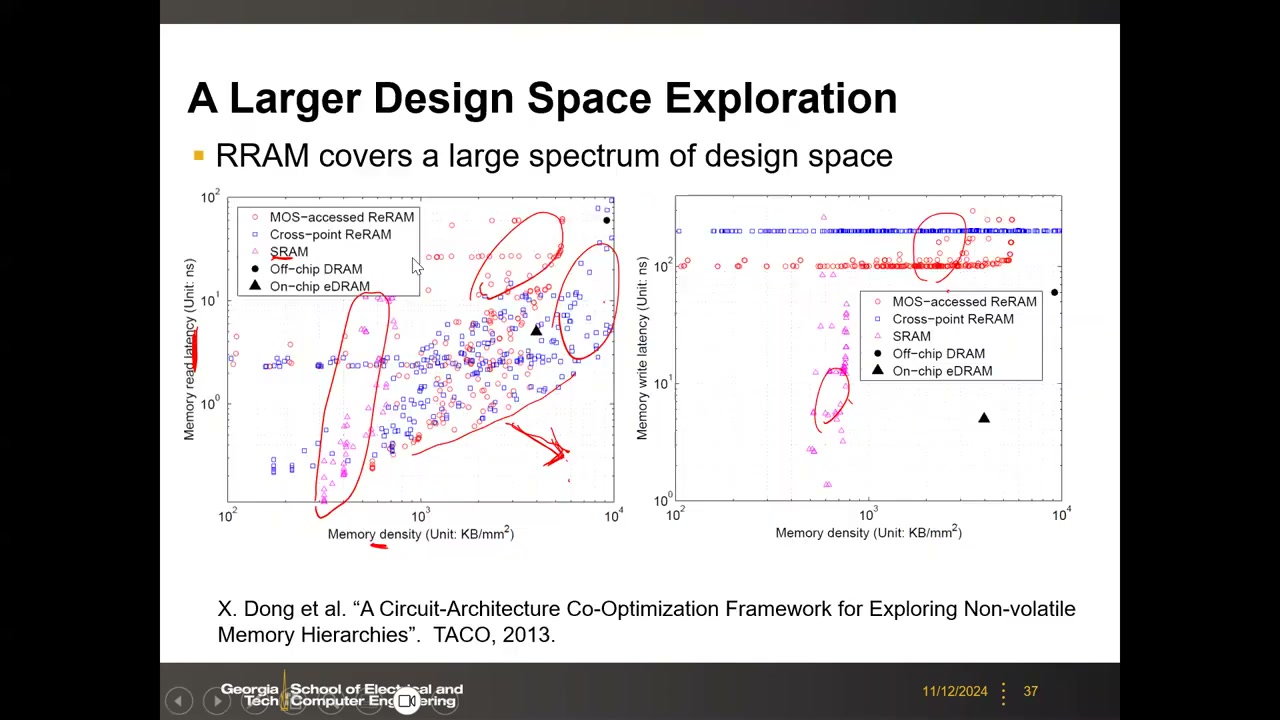
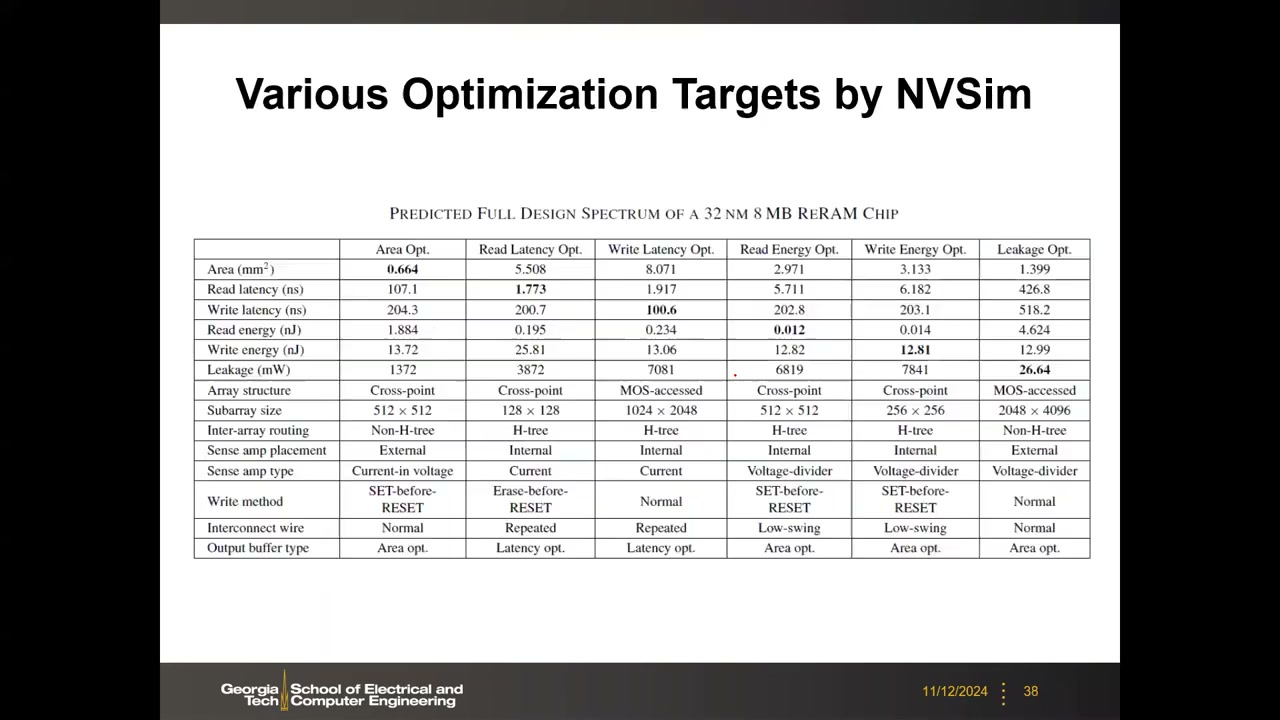
14. 设计空间探索:32nm 8MB RRAM 末级缓存 P2 00:29:12
任务设定:MOS 接入 RRAM 做末级缓存(LLC),32 nm 工艺、8 MB、8 路组相联。可变参数包括 sub-array 大小与数量、IO 宽度、互连模型、晶体管模型(HP/LP)、驱动器选项、电流/电压感测等,扫参后可分别向面积/漏电/速度三个方向收敛,在(读延迟 × 芯片面积 × 漏电)三维空间得到不同设计点。
更大范围的散点图(X. Dong et al., TACO 2013)P2 00:32:30:同一 32nm 节点下比较 MOS-accessed ReRAM、Cross-point ReRAM、SRAM、片外 DRAM、片上 eDRAM 的读/写延迟 vs 存储密度(KB/mm²)。SRAM(6T)单元大 → 密度低;1T1R 与交叉点 ReRAM 密度更高但延迟也更高——存在密度-延迟权衡,设计目标是逼近"高密度 + 低延迟"角落的 Pareto 前沿。写延迟图上 ReRAM 比 SRAM 慢 1–2 个数量级(平顶在 ~100+ ns)。
不同优化目标下的设计点 P2 00:34:28
| 优化目标 | 关键结果 | 配置要点 |
|---|---|---|
| 面积(Area Opt.) | 0.664 mm²(最小);读延迟 107.1 ns;写延迟 204.3 ns;漏电 1372 mW | 交叉点,sub-array 512×512,Non-H-tree,S/A 外置(External)共享,电流入电压感测,SET-before-RESET |
| 读延迟(Read Latency Opt.) | 1.773 ns(最快);面积 5.508 mm²(约 8 倍于面积优化) | 交叉点,sub-array 128×128,H-tree 布线,S/A 内置(Internal),电流感测,repeated 互连 |
| 写延迟(Write Latency Opt.) | 写延迟 100.6 ns | MOS-accessed,1024×2048 |
| 读能耗(Read Energy Opt.) | 0.012 nJ | 交叉点 512×512,低摆幅互连 |
| 写能耗(Write Energy Opt.) | 12.81 nJ | 交叉点 256×256 |
| 漏电(Leakage Opt.) | 26.64 mW(vs 面积优化的 1372 mW) | MOS-accessed,2048×4096,Non-H-tree |
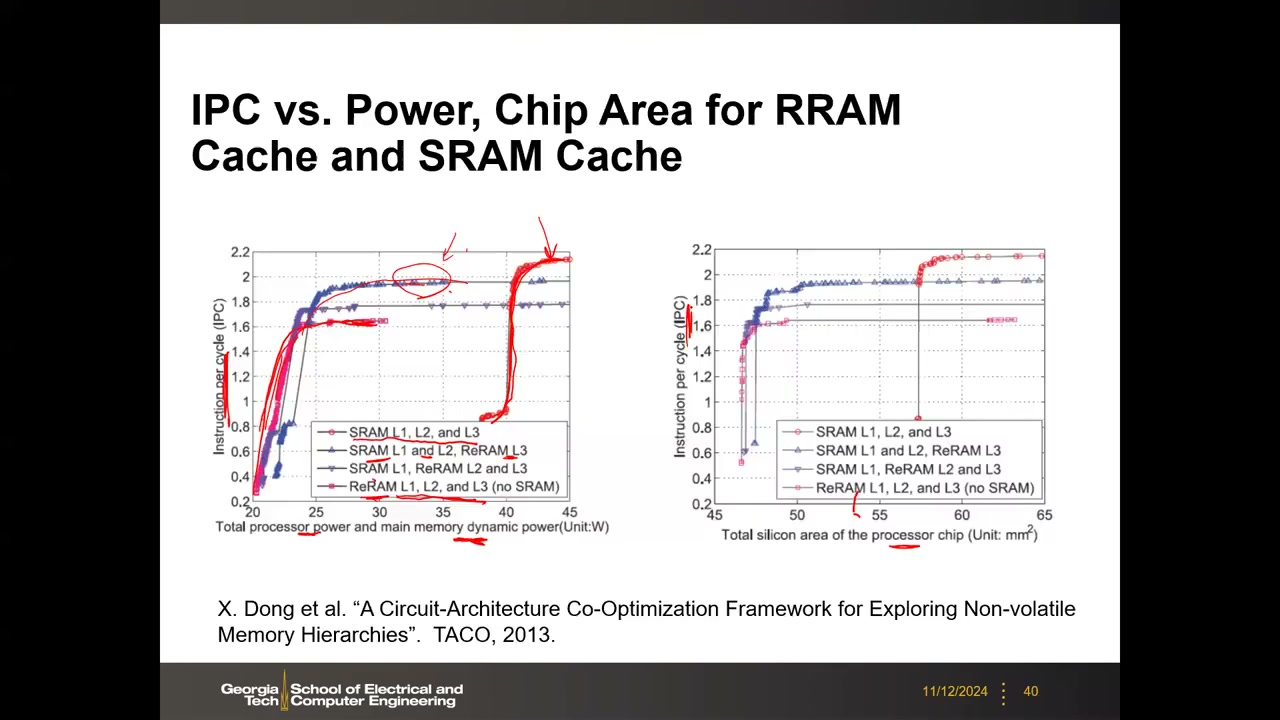
15. 系统级评估:NVSim + GEM5 P2 00:35:51
体系结构研究者关心系统级影响 → 把 NVSim 输出的 PPA 耦合进 GEM5(周期精确、基于 trace 的模拟器,ISCA/HPCA/MICRO 社区标准工具),分析工作负载下的访存模式。实验设定(TACO 2013):3.2 GHz、8 核顺序执行处理器;L1(I/D)8–64KB、L2 64–512KB、L3 4MB–128MB,每级缓存可选 SRAM 或 ReRAM,各级读写延迟由 NVSim 给出。以 IPC(每周期指令数)vs 动态功耗、vs 芯片总面积评估:
- 全 SRAM(L1/L2/L3):IPC 最高,但动态功耗最大;
- 全 ReRAM:功耗最低但 IPC 太差(L1/L2 需要速度,不该用 RRAM);
- SRAM L1/L2 + ReRAM L3:较好的折中点。
意义:实现"从器件技术 → 电路 → 处理器性能(工作负载下)"的全链路基准评估,是决定"哪一级存储层次用 NVM"的标准方法论。
16. NVSim 实操:配置文件、单元参数与输出解读 P2 00:40:41
获取与运行:GitHub https://github.com/SEAL-UCSB/NVSim,编译后运行 ./nvsim sample_STTRAM_macro.cfg。参考论文:X. Dong, C. Xu, Y. Xie, N. Jouppi, "NVSim: A Circuit-Level Performance, Energy, and Area Model for Emerging Nonvolatile Memory", IEEE TCAD, vol.31, no.7, 2012。作业中教授已上传可直接编译运行的版本。
配置文件 .cfg P2 00:41:13
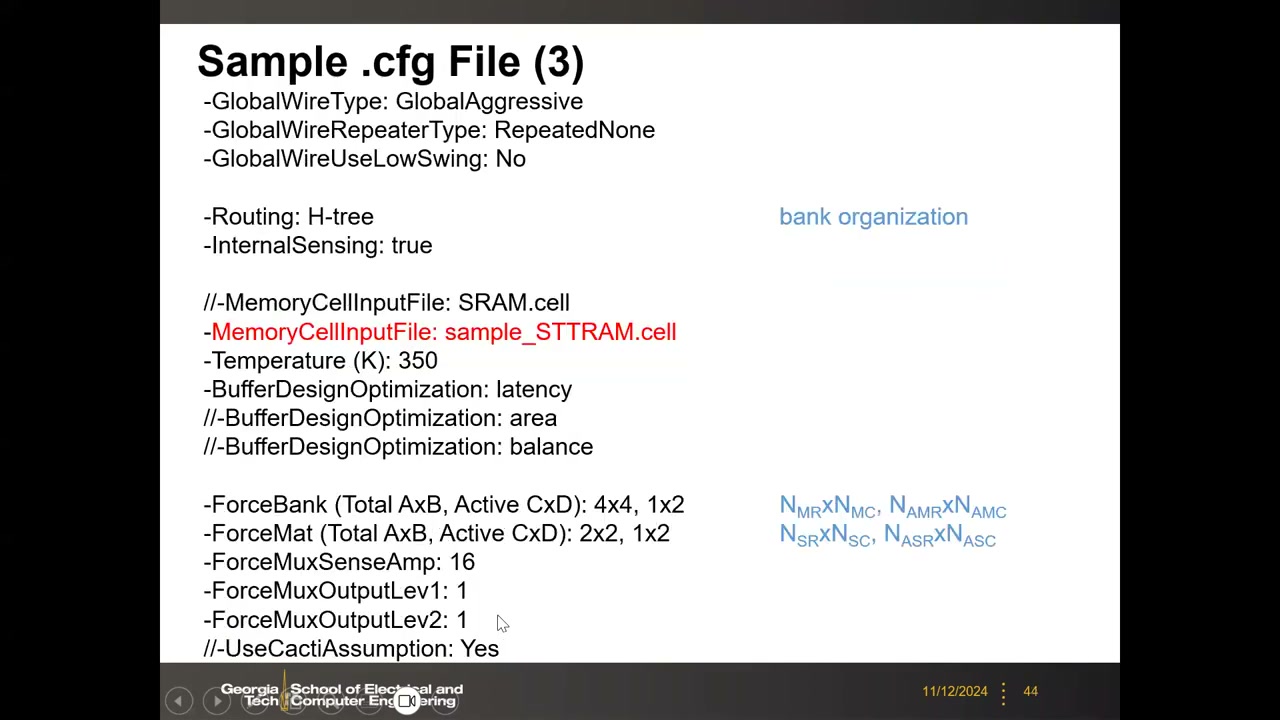
关键字段(- 为生效行,//- 为注释掉的备选项):
DesignTarget:cache 或 RAM(RAM 类似 scratchpad,无 tag);CacheAccessMode:Fast(tag 与 data 并行)/ Sequential;OptimizationTarget:ReadLatency / WriteLatency / Read(Write)DynamicEnergy / Read(Write)EDP / LeakagePower / Area——指定后工具自动在设计点中搜索最优;ProcessNode:90/65/45/32/22 nm;Capacity、WordWidth(IO 并行位数)、Associativity(仅 cache);DeviceRoadmap:HP / LSTP / LOP(外围晶体管类型);Local/Global wire 类型、repeater、low-swing 选项;Routing: H-tree;InternalSensing: true;MemoryCellInputFile: sample_STTRAM.cell(作业要改的就是这个文件);ForceBank (Total AxB, Active CxD): 4x4, 1x2↔ N_MR×N_MC、N_AMR×N_AMC;ForceMat: 2x2, 1x2↔ N_SR×N_SC、N_ASR×N_ASC;ForceMuxSenseAmp: 16(多少列共享一个 S/A)——Force* 参数把前面讲的层级/激活/共享 S/A 概念落到工具输入上。

单元参数文件 sample_STTRAM.cell P2 00:43:17
STT-MRAM 示例数值:MemCellType: MRAM;CellArea: 57.5 F²(接近 60 F²)、AspectRatio 0.57;ResistanceOn: 6000 Ω / ResistanceOff: 12000 Ω——开/关比仅 2 倍,与之前讲过的 STT-MRAM 低 on/off ratio 一致;ReadMode: current(电压输入电流感测)、ReadVoltage 0.25 V、MinSenseVoltage 25 mV;Set/Reset 均为电流写:40.82 μA、5 ns 脉冲、0.252 pJ;AccessType: CMOS(1T1R MOS 接入),AccessCMOSWidth 8.5 F。作业只需修改这个 cell 文件参数,观察存储单元技术对 bank 级 PPA 的影响(其他设计选项可自行尝试)。
输出解读:配置与延迟分解 P2 00:44:08
输出依次为:(1) 输入回显(单元参数与设计规格:RAM、128KB、128 bit 数据宽、按读延迟优化);(2) CONFIGURATION:Bank 1×1、Mat 2×2(全部激活)、Subarray 512 行 × 512 列、Senseamp Mux 16、局部导线 Local Aggressive;(3) RESULT:Total Area = 145.875 μm × 262.187 μm = 38246.504 μm²,Area Efficiency = 76.299%;Read Latency = 2.065 ns,分解为 Predecoder 80.392 ps + Subarray 1.985 ns(其中 Row Decoder 466.376 ps、Bitline 54.967 ps、Senseamp 1.454 ns、Mux 9.305 ps、Precharge 335.865 ps);Write Latency = 5.547 ns。
这个 latency breakdown 直接对应第 1 节的外围电路链(译码器 → 字线 → 位线 → S/A → Mux),并显示 S/A 与行译码器是读路径的主要开销。

结尾 P2 00:45:39:Yu 教授实验室把 NVSim 扩展为 NeuroSim——加入存内计算(神经网络加速)评估能力,并把工艺路线图从 32/28/22 nm 扩展到 5nm、3nm 乃至 2nm/1nm 及以后;本课程作业只用 NVSim。
本讲要点总结
- 子阵列 = 字线/位线被截断的最小阵列单元,外围电路链为:行译码器 → 字线驱动器 → (单元/位线)→ 位线 MUX → 灵敏放大器 → SA MUX → 输出/写驱动器,外加预充均衡电路。
- 译码器是标准数字电路:地址 ≥ 6–8 位必须采用两级预译码以避免过大扇入;伪 NMOS/动态逻辑可省面积或提速。
- 字线驱动器是延迟—面积折中的典型:驱动 4096 单位电容,延迟优化 6 级链(延迟 30/面积 1365 单位)vs 面积优化 2 级(延迟 ~130/面积 ~65 单位);SRAM cache 选延迟优化,DRAM/Flash 选面积优化。
- 位线 RC 延迟通式 Δt = (R_T·C_T/2)·[(R_m+R_T/3+R_L)/(R_m+R_T+R_L)] + R_m·C_T·[R_L/(R_m+R_T+R_L)];电压检测取 R_L→∞ 得 Δt_v = R_T·C_T/2 + R_m·C_T,电流检测取 R_L→0 得 Δt_i = (R_T·C_T/2)·(R_m+R_T/3)/(R_m+R_T)。
- 数值算例(R_m=2500 Ω、R_T=250 Ω、C_T=2 pF):电压模式 5.25 ns vs 电流模式 0.235 ns——电流模式通常更快,但电路更复杂;判别准则:信号进栅极 = 电压模式,注入漏/源 = 电流模式。
- SPICE 仿真给出 SA 选型准则:阵列小 → 电压型(VSA)快;阵列大、单元电阻大(读电流小)→ 电流型(CSA)快,盈亏平衡点约几百单元/BL。
- NAND 慢、NOR 快的电路本质:NAND 串联串导致等效 R_m 高、读电流仅 ~100 nA → 读出 ≥10 μs;NOR 单元并联、读电流 μA 级 → 读出几十 ns。SA 设计两大研究主题:小电流快读 + 失调(offset)容忍。
- 层级组织 bank / mat / sub-array / block 的第一性权衡:sub-array 大 → 面积效率高但慢;小 → 快但面积开销大。局部感测(每 sub-array 自带 S/A + H-tree 传数字信号)快但费面积;全局感测(共享 S/A,长线传部分摆幅模拟信号)省面积但慢。
- SanDisk 32Gb RRAM(24nm 交叉点、2 层)案例:单元本身快,但老工艺外围 + 每 Bay 仅 64 个共享 S/A(单次感测 ~1 μs)→ 2KB 页需多周期 → 读延迟 40 μs、只能做 NAND 兼容接口——瓶颈在外围电路与阵列组织,不在存储单元。
- NVSim(Yuan Xie 组,继承 HP CACTI):解析 PPA 模型、不依赖 EDA,验证误差多在个位数百分比;用于设计空间探索——不同优化目标(面积/读延迟/写延迟/能耗/漏电)导出完全不同的配置(如面积优化 0.664 mm²/107 ns vs 读延迟优化 1.773 ns/5.5 mm²)。
- NVSim + GEM5 实现器件→电路→系统全链路评估:全 SRAM 缓存 IPC 最高但功耗大,全 ReRAM 功耗低但 IPC 差,SRAM L1/L2 + ReRAM L3 是较好折中;但 RRAM 做缓存的根本短板是耐久性。
- 作业 5 实操:修改 sample_STTRAM.cell 的单元参数(57.5 F²、6k/12kΩ 等)观察 bank 级 PPA 变化;输出的延迟分解(示例中 Senseamp 占 1.454 ns / 读延迟 2.065 ns)直接对应外围电路链。
术语表
| 术语 | 中文 | 释义 |
|---|---|---|
| Sub-array | 子阵列 | 字线/位线被截断、内部不再分割的最小阵列单元,外围电路围绕其布置。 |
| Mat | 矩阵块 | bank 内的可操作构建块,由多个 sub-array 组成。 |
| Bank | 存储体 | 完整功能的存储单元,层级组织最高一级,由多个 mat 构成(SanDisk 论文中称 Bay)。 |
| Block | 数据块 | 数据存储单位;一次访问的数据可分布在多个激活的 sub-array 中。 |
| Peripheral circuitry | 外围电路 | 阵列周边的译码、驱动、选择、读出、预充等辅助电路。 |
| Row decoder | 行译码器 | 把 n 位行地址译码为 2^n 条字线选通信号的数字电路。 |
| Pre-decoder / two-stage decoding | 预译码/两级译码 | 把宽地址拆成两级小译码器级联以减小扇入和面积,≥6–8 位地址必用。 |
| Pseudo-NMOS | 伪 NMOS | 用单个常通 PMOS 作上拉负载的逻辑,省面积但有静态功耗、非轨到轨。 |
| Dynamic logic | 动态逻辑 | 时钟预充输出节点、再按输入放电的逻辑,通常比静态更快。 |
| Wordline driver | 字线驱动器 | 译码器后驱动大电容字线的多级渐增尺寸反相器链。 |
| Logical effort | 逻辑努力 | 计算反相器链最优级数与尺寸以最小化延迟的方法。 |
| Bitline MUX (column MUX) | 位线多路选择器 | 选择哪一列位线接入共享灵敏放大器的开关网络(预译码式或树形)。 |
| Transmission gate / pass gate | 传输门/导通门 | 由选通信号控制的 NMOS/PMOS(或互补对)模拟开关。 |
| Distributed RC model | 分布式 RC 模型 | 把长导线分段为多个 R、C 单元的寄生建模方法。 |
| R_T / C_T | 位线总电阻/总电容 | 位线导线的总寄生电阻与电容,决定 RC 延迟。 |
| R_m | 单元等效电阻 | 存储单元读通路的等效输出电阻(如 RRAM 单元电阻、SRAM 读通路沟道电阻)。 |
| Sense amplifier (SA / S/A) | 灵敏放大器 | 把位线上的微小电压/电流信号放大为全摆幅数字输出的电路,存储器电路创新核心。 |
| Voltage-mode sensing | 电压模式检测 | 信号以电压形式进 SA 晶体管栅极;理想输入阻抗无穷大,Δt_v = R_T·C_T/2 + R_m·C_T。 |
| Current-mode sensing | 电流模式检测 | 信号以电流形式注入 SA 晶体管漏/源;理想输入阻抗为零,一般更快但电路更复杂。 |
| Latch-type SA | 锁存型灵敏放大器 | 交叉耦合反相器靠正反馈快速翻转的 SA,SRAM/DRAM 主流。 |
| Current mirror | 电流镜 | 复制(并可按尺寸比放大/缩小)一支电流到另一支的基本模拟结构,用作差分负载或电流比较。 |
| Precharge & Equalization | 预充与均衡 | 读操作前把位线(对)充至固定电压并使其相等的电路(如 SRAM BL/BLB 预充到 VDD)。 |
| SAE / SAEN | 灵敏放大器使能 | 控制 SA 开始判决的时钟信号。 |
| V_BL development time | 位线电压发展窗口 | 预充后让位线按单元状态衰减/充电以建立可判决压差的时间段。 |
| Clamp voltage (V_CLP) | 钳位电压 | 电流模式读出中把位线电压固定在读电压附近的偏置,使读电流仅由单元电阻决定。 |
| Reference current/voltage | 参考电流/电压 | SA 判决基准;可由一半高阻一半低阻的 dummy 阵列取平均电流产生。 |
| Open bitline | 开放位线架构 | DRAM 中从相邻阵列借参考位线的阵列组织方式。 |
| HRS / LRS | 高阻态/低阻态 | 阻变存储器的两个电阻状态(数据 0/1)。 |
| 1T1R (MOS-accessed) | 一管一阻单元 | 一个选择晶体管串联一个阻变元件的存储单元结构,与交叉点结构相对。 |
| Offset | 失调 | 差分对晶体管失配(V_th 变异)导致 SA 内建偏置,使有效参考点偏移、临界信号判决出错;SA 设计关键挑战。 |
| H-tree routing | H 树布线 | 数据总线逐级对称分叉成 H 形的布线方式,到各子阵列路径等长,配合局部感测传输全摆幅数字信号。 |
| Local sensing | 局部感测 | 每个子阵列配备自己的灵敏放大器,在本地完成数字化后再聚合,速度快但面积大。 |
| Global sensing | 全局感测 | 灵敏放大器在多个子阵列间共享(非 H-tree 组织),省面积但模拟部分摆幅信号需长距离布线。 |
| Partial-swing signal | 部分摆幅信号 | 未经放大数字化的小幅度模拟电压/电流信号,对噪声和导线寄生敏感。 |
| Cross-point array | 交叉点阵列 | 字线位线交叉处仅放"选择器+存储电阻"的无晶体管阵列,密度高(4F²/层)但需偏置方案抑制潜行电流。 |
| Selector | 选择器 | 交叉点单元中与存储电阻串联的非线性器件,用于抑制未选单元漏电。 |
| Bay | 区(=bank) | SanDisk 论文中对 bank 一级的称呼;该芯片 16 个 Bay,每个含 128 个 block。 |
| Page Register | 页寄存器 | S/A 之后的寄存器/缓冲,暂存感测结果,逐周期填充页缓冲。 |
| V_UB (unselected bias) | 未选偏置电压 | 施加在未选行/列上的公共电压,用于最小化经未选单元的漏电流(潜行电流)。 |
| CACTI | CACTI 缓存模型 | HP 实验室 1990 年代开发的 SRAM/eDRAM 缓存面积-时序-功耗解析估算工具,NVSim 的前身。 |
| NVSim | 非易失存储器模拟器 | Yuan Xie 组开发的 bank 级 NVM 解析 PPA 模型(C++,无需 EDA),支持 SRAM/DRAM/STTRAM/PCRAM/ReRAM。 |
| PPA (Power, Performance, Area) | 功耗-性能-面积 | 电路/架构设计的三大评价指标。 |
| Design Space Exploration | 设计空间探索 | 在流片前扫描所有配置组合(数百至上千种),按优化目标寻找最优/Pareto 设计点。 |
| GEM5 | GEM5 体系结构模拟器 | 计算机体系结构社区标准的周期精确、基于 trace 的全系统模拟器,与 NVSim 耦合做系统级评估。 |
| IPC (Instructions Per Cycle) | 每周期指令数 | CPU 性能指标,越高越好;用于评估不同缓存技术组合的系统影响。 |
| LLC (Last-Level Cache) | 末级缓存 | 缓存层次最低一级(如 L3);因写入频繁,对耐久性有限的 RRAM 并不理想。 |
| Endurance | 耐久性 | 存储单元可承受的擦写循环次数;RRAM 类似闪存有限,不适合频繁重写的缓存场景。 |
| DeviceRoadmap (HP/LSTP/LOP) | 外围晶体管类型 | 高性能/低待机功耗/低工作功耗三种逻辑晶体管选项,Vth 与开关态电流不同。 |
| F² (feature size squared) | 特征尺寸平方 | 归一化单元面积单位;F 为半间距(SanDisk 芯片 F≈24 nm,STT-MRAM 示例单元 57.5 F²)。 |
| Area Efficiency | 面积效率 | 存储单元阵列面积占总面积(含外围电路)的比例,NVSim 输出示例为 76.299%。 |
| EDP (Energy-Delay Product) | 能耗-延迟积 | 综合能耗与速度的优化目标(NVSim 支持 ReadEDP/WriteEDP)。 |
| NeuroSim | NeuroSim 模拟器 | Yu 教授实验室基于 NVSim 的扩展,加入存内计算(神经网络加速)评估并支持 5nm/3nm 至 1nm 等先进节点。 |
| NVSim Force* 参数 | 强制组织参数 | ForceBank/ForceMat 指定 Total AxB 与 Active CxD,对应 N_MR/N_MC、N_AMR/N_AMC 与 N_SR/N_SC、N_ASR/N_ASC。 |